






作者 | 奥本海默 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/617936182
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【多传感器融合】技术交流群
后台回复【多传感器融合综述】获取图像/激光雷达/毫米波雷达融合综述等干货资料!

论文:https://arxiv.org/abs/2211.14461
本文为大家带来CVPR 2023在图像融合领域的最新工作CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition,作者是西安交通大学的赵子祥博士 @沙坡村民工,大家也可以看作者的知乎主页哈。本文的整体架构和赵博士先前在IJCAI上发表的DIDFuse有继承关系,这次的亮点是1.结合CNN和当前火爆的Transformer;2.将特征解耦的思想引入了图像融合,将跨模态信息分解为共有信息和特有信息,类似于DRF等融合模型;3.两阶段训练法,第一阶段采用的输入和输出都是源图像的自监督方式,SD-Net、SFA-Fuse采用了这类思想;4.用高级视觉任务验证了融合效果。
下面是正文部分。
多模态图像融合目的是结合各个模态图像的特点,如有物理含义的高亮区域和纹理细节。为了能对跨模态进行有效建模,并分解得到期望的各模态共有特征和特有特征,本文提出了Correlation-Driven feature Decomposition Fusion (CDDFuse) 来进行多模态特征分解和图像融合。本文模型分为两阶段,第一阶段CDDFuse首先使用Restormer块来提取跨模态浅层特征,然后引入双分支Transformer-CNN特征提取器,其中 Lite Transformer (LT)块利用长程注意力处理低频全局特征, Invertible Neural Networks (INN) 块则用来提取高频局部特征。基于嵌入的语义信息,低频特征应该是相关的,而高频特征应该是不相关的。因此,提出了相关性驱动损失函数,让网络可以对特征进行更有效的分解。第二阶段,前述的LT和INN模块会输出融合图像。实验部分展示了ir-vis和医学影像融合两种任务,并且还验证了CDDFuse可以提升ir-vis对分割、检测等下游任务的效果提升。
目前已有的多模态图像融合模型很多采用自编码器结构,如下图a。
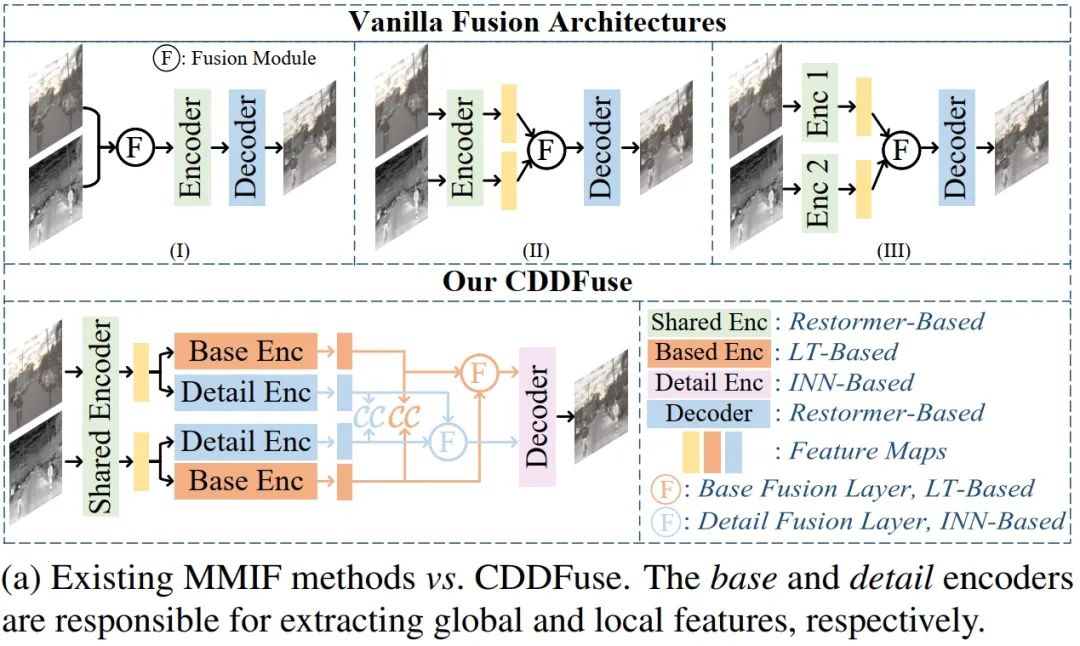
但是这种方式有三个缺陷:1.CNN的解释性较差,难以控制,对跨模态特征提取不够充分,如上图a前两种都是多模态输入共享编码器,因此难以提取到模态特有的特征,而第三种双分支结构则忽略了各个模态共有属性;2.上下文独立的CNN结构只能在相对小的感受野内提取到局部信息,很难捕获全局信息,因此目前还不清楚 CNN 的归纳偏差能否对所有模态的输入充分提取特征;3.网络的前向传播会造成高频信息丢失
本文探索了一种合理的范式来解决特征提取和融合上的问题。首先给提取到的特征添加相关性约束,提高特征提取的可控制性和可解释性,本文的假设是对于多模态图像融合,两个模态的输入特征在低频上是相关的,表示了所有模态的共有信息,在高频上是不相关的,表示了各个模态独有的信息。比如ir-vis融合,红外与可见光图的场景相同,在低频信息上包含统计上的共有信息,比如背景和大尺度环境特征,而高频部分的信息则是独立的,比如可见光模态纹理细节信息和红外模态的温度信息都是各自模态特有的。因此需要通过分别提高低频部分特征之间相关性、降低高频特征之间的相关性来促进跨模态特征提取。transformer目前在视觉任务上很成功,主要得益于它的自注意力机制和全局特征提取能力,但是往往很大的计算资源,因此本文提出让transformer结合CNN的局部上下文提取和计算高效性的优势。最后,为了解决丢失期望高频输入信息的问题,引入了Invertible Neural networks (INN)块,INN 是通过可逆性设计让输入和输出特征的相互生成来防止信息丢失,符合融合图像中保留高频特征的目标。
模型方法
模型整体结构如下图,整体分为四个模块:双分支编码器用于特征提取与分解、解码器用于训练阶段I的图像重建或者训练阶段II的图像融合、base/detail融合层用于融合不同频率的特征。
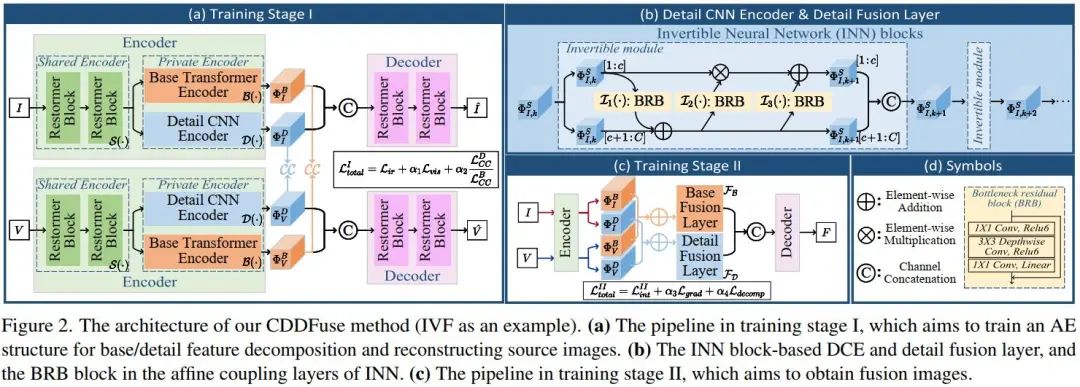
编码器:包含三部分:Restormer block - based share feature encoder (SFE)、Lite Transformer (LT) block - based base transformer encoder (BTE) 、 Invertible Neural networks (INN) block - based detail CNN encoder (DCE),其中BTE和DCE共同组成长短距离编码器。对于输入的三通道可见光图和单通道红外图,用S、B、D分别表示SFE、BTE、DCE三个模块。首先来看用来提取共有特征的SFE模块,它的目标是提取浅层特征,如下式。
在SFE中使用Restormer block的原因是利用维度间的自注意力机制提取全局特征,因此可以不增加算力的情况下提取跨模态浅层特征,这里采用的Restormer block结构来源于 Syed Waqas Zamir, Aditya Arora, Salman H. Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. CoRR, abs/2111.09881, 2021.
BTE用来从共有特征中提取低频基特征,如下式。
为了能提取城距离dependency,使用具有空间自注意力的transformer,为了能平衡效果和运算效率,这里采用了LT block作为BTE的基础单元,可以在降低参数量的情况下保证效果。
DCE和BTE相反,用来提取高频细节信息,如下式。
考虑到边缘纹理信息在融合任务中也很重要,这里就希望DCE能尽量保留更多的细节。INN模块通过输入和输出能相互生成来确保输入信息被尽可能保留,因此可以在DCE中用于无损特征提取,具体实现时是用INN搭配affine coupling层,每个可逆层的变换如下。
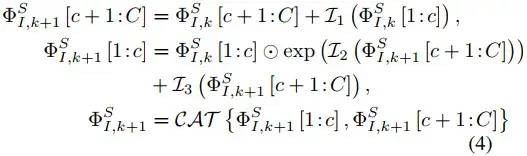
上式过程和图2的b中过程是对应的,图中BRB的结构如图2中的d(来源于MobileNetV2),每个可逆层中的BRB都可以看做是无损信息映射。
融合层:用于将编码器提取到的特征进行融合。考虑到 base/detail 特征融合的归纳偏置应该和编码器的 base/detail 特征提取相同,使用LT和INN块来实现 base/detail 融合层,如下式。
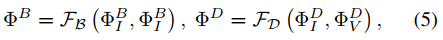
解码器:解码器首先将分解的特征在通道维度拼接作为输入,然后在训练阶段I将源图作为输出,在训练结算II将融合图作为输出,如下式。
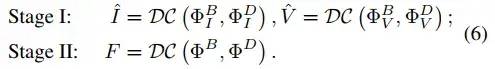
由于输入的特征是跨模态且多频段特征,因此让解码器结构和SFE保持一致,即将Restormer block作为基础单元。
两阶段训练:由于没有GT,采用和RFN-Nest相同的两阶段训练法。一阶段将ir-vis作为SFE的输入来提取浅层特征,然后BTE和DCE提取高低频特征,然后再把红外的base和detail特征拼接,可见光的base和detail特征拼接,送到解码器中,分别用来重建原始输入的红外图和可见光图。二阶段训练时的编码器部分相同,不同之处为提取到base和detail特征之后,可以看图2的c,需要将红外和可见光的base特征相加,detail特征也分别相加,然后分别送入base和detail融合层中,输出再在通道维度上拼接,经过解码器后就是融合图像F了。
损失函数:一阶段损失函数如下。

前两项是红外和可见光的重建损失,第三项是特征分解损失。一阶段损失整体是为了编码和解码过程中信息不会损失。
第一项红外重建损失形式如下。
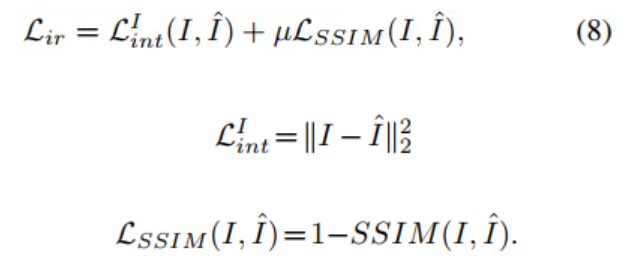
第二项的可见光重建损失和上式形式是一样的,换成可见光图即可。
特征分解损失形式如下。
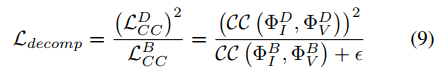
式中的CC是融合中常用的指标correlation coefficient。这一项损失就是前文中描述的让共有特征之间距离尽量近、特有特征之间距离尽量远,搭配相关系数可以测量特征之间距离了,因此将低频base特征作为分母,高频detail特征作为分子。该部分分解的效果如下图。

二阶段的损失函数形式如下。
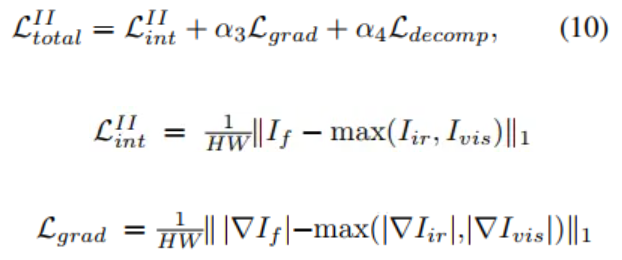
实验部分
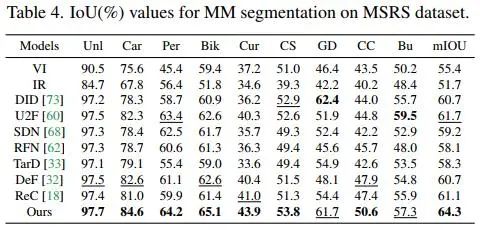
实验使用ir-vis融合来演示,选择了MSRS、Roadscene、TNO三个经典数据集。训练时将图片裁切为128×128的patch,训练120个epoch,其中第一阶段和第二阶段分别为40和80,batch设置为16。其他训练细节可以直接看原文。
方法之间的对比可以看下图。

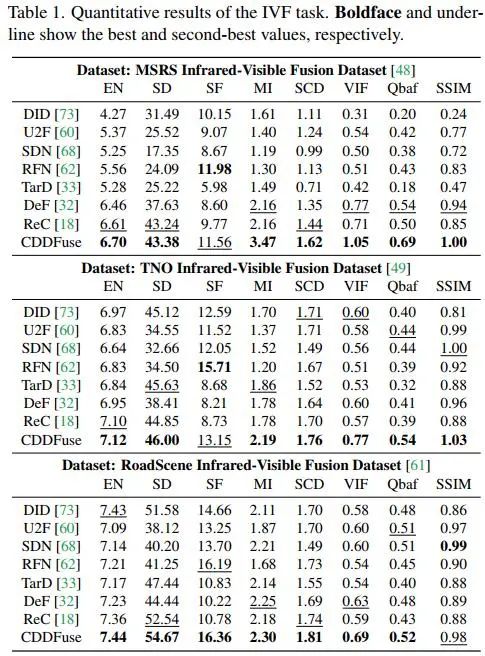
消融实验有三部分。第一部分是分解损失,将base和detail损失由相除变为相减,另一个是直接去除分解损失。编码器中的LT和INN块也进行了消融实验,分别是将BTE中的LT换为INN、DCE中的INN换为LT、DCE中的INN换为CNN。最后一个是两阶段训练的实验,也就是直接采用一阶段训练法,用第二阶段的融合图像作为约束训练网络,可以看到效果差了很多。
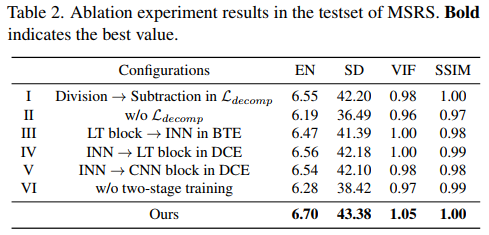
下游高级视觉任务的对比,展示了检测和分割两种任务上的效果。首先是检测,这里采用了M3FD数据集,将YOLOv5作为检测器,训练400个epoch,指标选为mAP@0.5,结果如下表。
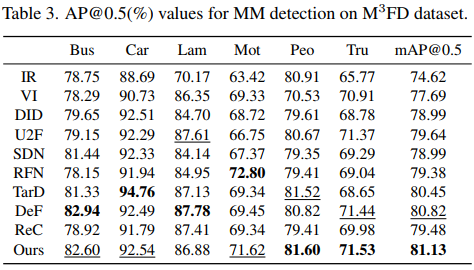
分割任务使用MSRS数据集,使用DeeplabV3+作为分割模型,评价指标选择IoU,结果如下表。
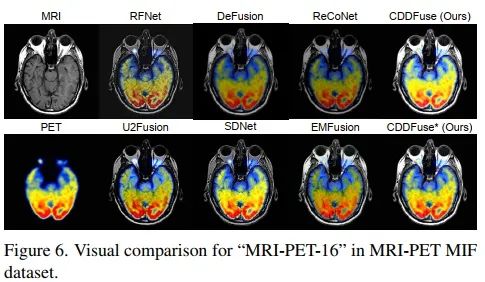
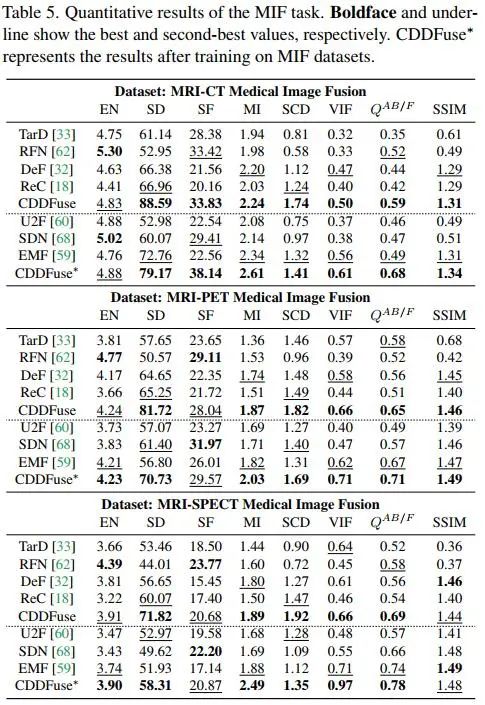
另一组多模态图像融合实验是针对医学影像进行的,选取了Harvard Medical website中286个图像对,包含MRI-CT、MRI-PET、MRI-SPECT三种图像对数据,对比结果如下图。
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









