








深度学习订单出餐时间概率预测 美团2022 KDD
背景
外卖出餐时间(Food Prepare Time) 的预估在订单指派和取餐时间推荐两个产品功能上十分重要。面临的主要困难有
- label不完整:
label分为两类,真实label(precise label,PL)和区间label(range-label,RL)。商家主动上报的出餐时间,或者骑手在商家等待一段时间后才取到外卖的取餐时间,我们将这一部分认为是PL,大概占总订单的不到70%。其余订单只能获取到其上下界。我们可以这样定义:出餐时间 ∈ \in ∈ [骑手因等太久放弃取餐的时间,取餐时间], 如果没有明确判定理由,下界设置为0。 - 数据不确定性。收到商家供给、食物准备流程、堂食环境等多方面因素影响,传统的预估方式很难准确。
本文尝试预估FPT的概率分布(PF probabilistic forecasting), 给不确定性决策提供更多有效的信息。
related work review:
- 贝叶斯/非贝叶斯方法,参数方法/非参数方法

- CRPS

问题定义

D: 订单里菜品的合集
m: 订单里不同的菜品的个数
d_i:订单里的第i个不同的菜品
num_i: 订单里的第i个不同的菜品的个数
方法
PL和RL订单的聚合
因为有RL样本,直接计算label的均值和方差的方法无效。本文使用离散累计概率DCP(Discrete Cumulative Probabilities)的方法。

D
C
P
z
DCP_z
DCPz表示在z这个等距离散时间点(够长 fpt不会跨越)前,有多少订单的出餐时间没有到达,一个计算的例子:

上下界穿越z的订单不计算,所以分母是5,分子是2。近似平均值的算法:

特征提取

S-CRPS and S-Quantile Loss
这一部分是为了定义模型的loss
-
CRPS(连续排序概率分数)已经在PF中被广泛应用,基本公式为:F是累计函数,y是观测值(observation) 。也就是x<y的时候如果想减小loss就要减小F, x>y时要增大F

ps. 更好理解的版本:

-
把crps和分位点loss(ql) 结合起来


F − 1 F^{-1} F−1是累计函数的逆函数(相当于已知概率求事件),为了方便计算(3)式会直接用 sum over discrete q = 0.01 … 0.99 来计算 -
本文的创新- SCRPS, 更适合RL数据,能产生更sharp的分布。不确定明确的label, 充分利用上下界

对于range label数据,处于上下界之间的样本不计算损失:


模型
- 结构
平平无奇DCN高维交叉 + Attention计算dishes的影响权重。模型的输出是一串递增的数据,表示概率分布。

值得一提的是,在预测阶段(a) 为了保证随着分位数的增加,预测概率同步增加,采用全连接softplus激活函数,
s
o
f
t
p
l
u
s
(
x
)
=
l
o
g
(
1
+
e
x
)
softplus(x)=log(1+e^x)
softplus(x)=log(1+ex), 每个分位数得到一个非负数,然后在Cumsum环节对前置各中间结果进行累加。最终输出
F
−
1
(
q
i
)
F^{-1}(q_i)
F−1(qi)。
- 训练

- 评估
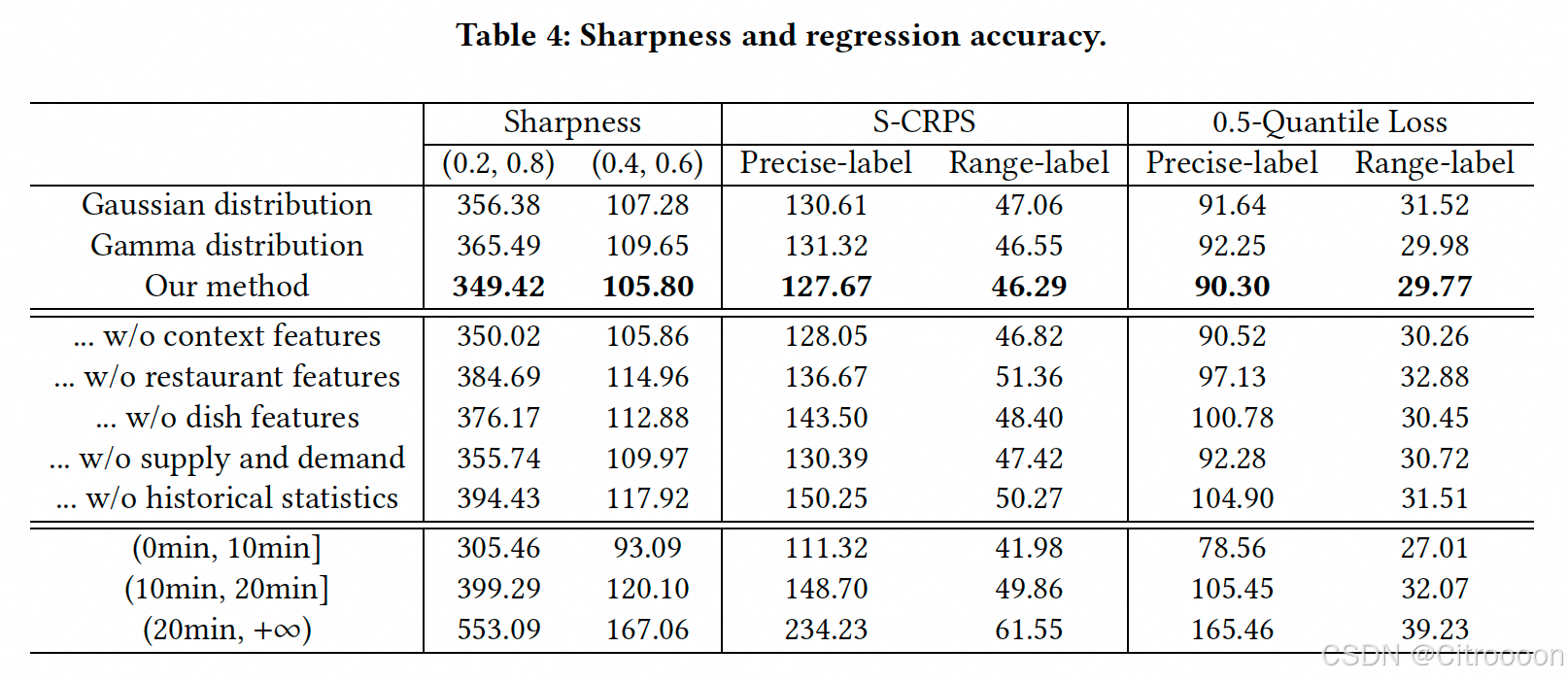
概率预测的目标是在满足 calibration(校准) 的前提下尽可能提高预测的 sharpness。
所谓的 calibration 指的是预测分布和观测值在统计上的一致性,而 sharpness(锐度) 则是指预测分布的集中程度。
用本文的非参数方法对比高斯分布/伽马分布(保持模型结构不变,只改变最后一层为分布的参数)



















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









