






五、大模型训练耗时估计
知道了理论计算量,我们就可以估算训练时间了。但是,实际训练时间不仅取决于理论计算量,还与硬件性能和利用率有关。让我们来看看如何进行粗略的估计:
首先,我们需要考虑激活重计算技术。使用这种技术,对于每个token,每个模型参数,我们需要进行:
- 1次前向传递
- 2次后向传递
- 1次额外的前向传递(用于重计算)
重计算方法:正向传播中间状态占的内存太多了,可以用算力换内存,就是不存储那么多梯度和每一层的正向传播的中间状态,而是在计算到某一层的时候再临时从头开始重算正向传播的中间状态,这样这层的正向传播中间状态就不用保存了,论文:《Reducing Activation Recomputation in Large Transformer Models》
所以,总共是1 + 2 + 1 = 4次基本操作,每次操作包含2次浮点运算。因此,最终的计算量是:
实际FLOPs = 8 * tokens数 * 模型参数量
有了这个,我们就可以估算训练时间了:
训练时间 = (8 * tokens数 * 模型参数量) / (GPU数量 * 每个GPU的峰值FLOPS * GPU利用率)
这里的GPU利用率是个关键因素。一般来说,GPU利用率在0.3到0.55之间。为什么不能达到100%呢?因为在实际训练中,我们还需要考虑:
- CPU加载数据的时间
- 优化器更新参数的时间
- 多卡之间的通信时间
- 记录日志的时间
所有这些因素都会降低GPU的有效利用率。
六、常见显卡算力峰值
说到GPU,我们来看看一些常见显卡的算力峰值(以FP16精度为例):
- NVIDIA A100 80GB PCIe:312 TFLOPS
- NVIDIA A10 24GB PCIe:125 TFLOPS
- NVIDIA A800 80GB PCIe:312 TFLOPS
知道这些数据后,我们就可以更准确地估算训练时间了。比如,假设我们用8张A100卡来训练,GPU利用率为0.5,那么有效算力就是:
8 * 312 * 0.5 = 1248 TFLOPS
七、训练模型参数量与训练数据量的关系
在规划训练时,我们还需要考虑模型参数量和训练数据量之间的关系。根据研究,我们有以下发现:
- OpenAI在2020年的研究"Scaling Laws for Neural Language Models"给出了一些初步的结论。
- 更进一步,DeepMind在2022年的研究"Training Compute-Optimal Large Language Models"提出了一个简略版的结论:每个参数大约需要20个文本token。
这个结论非常有用。比如,如果你有一个10亿参数的模型,那么理想的训练数据量应该在200亿token左右。
需要注意的是,这个比例并不是固定不变的。随着模型规模的增大,这个比例可能会有所变化。但作为一个初步估计,这个"1:20"的比例是一个很好的起点。
八、epoch的设置
在传统的机器学习中,我们常常会进行多轮(多个epoch)的训练,以便模型能够充分学习数据中的模式。但在大语言模型(LLM)的训练中,情况有些不同。
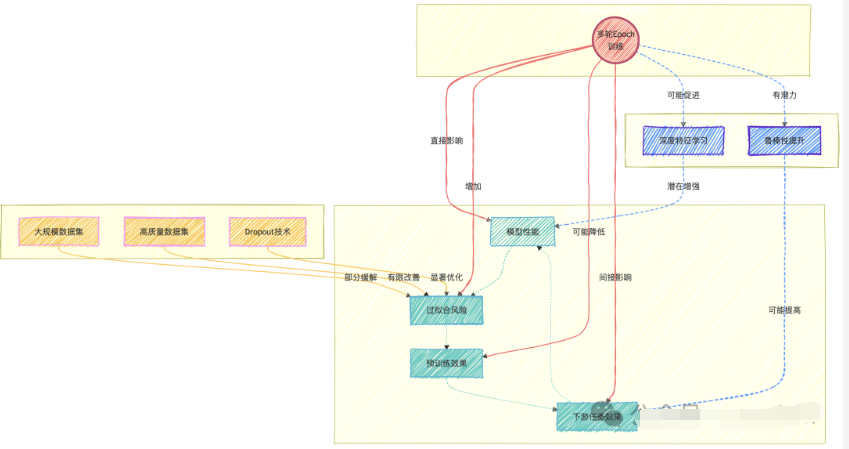
首先,让我们回顾一下epoch的定义:一个epoch指的是模型训练过程中完成一次全体训练样本的全部训练迭代。
在LLM时代,很多模型的epoch只有1次或几次。为什么会这样呢?让我们来看看一些研究发现:
-
数据重复对模型性能的影响:根据研究"To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis",多轮epoch的训练实际上会降低模型性能。
-
数据量和模型规模的关系:模型参数规模的增长与模型需要的tokens数量基本上是呈线性关系的。这意味着,随着模型变大,我们需要更多的不重复数据。
-
数据质量的影响:即使提高数据集的质量,也无法完全挽救重复训练带来的过拟合问题。
-
模型规模的影响:有趣的是,无论是小规模还是大规模模型,在重复训练时都表现出类似的过拟合趋势。
-
正则化技术的作用:Dropout是一个在大语言模型训练中常被忽视的正则化技术。虽然它可能会降低训练速度,但能有效减少多epoch训练的负面影响。一个有效的策略是在训练过程中逐渐增加dropout率。
在大模型训练中,我们倾向于使用更大的数据集和更少的epoch,而不是在同一数据集上反复训练。这不仅能提高模型性能,还能节省计算资源。
九、token和存储之间的关系
在规划训练数据时,了解token和实际存储空间之间的关系很重要。这里有一些粗略的估算:
1. 对于中文文本:
- 1个token大约对应1.4-1.7个汉字
- 一个汉字在UTF-8编码下占用2个字节
- 因此,1B(10亿)token大约对应3GB的中文文本存储空间
2. 对于英文文本:
- 1个token大约对应3-4个字符
- 假设每个字符占用1个字节(ASCII编码)
- 那么,1B token大约对应3-4GB的英文文本存储空间
这些估算可以帮助你在准备训练数据时,大致判断需要多少存储空间。不过,请记住,这只是粗略估计,实际情况可能会有所不同,尤其是在处理混合语言或特殊格式的文本时。
十、结语
好了,我们已经深入讨论了大模型微调训练的方方面面,从理论计算量到实际训练时间的估算,从内存需求到数据量的选择。记住,在实际项目中,这些因素都需要综合考虑。
比如,当你知道了数据量和目标模型的参数量,你就可以估算出:
- 所需的理论计算量
- 训练所需的最小内存
- 在给定硬件条件下的预计训练时间
- 所需的存储空间
有了这些信息,你就可以更好地规划资源,也能更专业地向项目负责人或老板解释为什么需要这些资源。
记住,大模型训练是一个复杂的过程,需要不断实践和调整。希望这篇文章能给你一个好的起点,帮助你在大模型微调的道路上走得更远。
如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方CSDN官方认证二维码,免费领取【
保证100%免费】

如有侵权,请联系删除

















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









