







【MLCA注意力机制原理介绍】
创新升级:MLCA 机制助力 YOLOv11 性能飞跃
本篇文章将深入剖析一个全新的改进机制——混合局部通道注意力机制(MLCA),并详细阐述其在 YOLOv11 目标检测模型中的融合应用方式,以及这一结合为模型性能带来的显著提升。
首先,我们会揭开 MLCA 的神秘面纱,解析其工作原理。MLCA 巧妙地融合了通道信息与空间信息,同时兼顾局部特征与全局特征,旨在全方位提升目标检测网络的性能表现,而且始终坚守模型轻量化的原则。
随后,我们将进入核心环节,详细讲解如何将 MLCA 模块与 YOLOv11 深度融合。这一过程中,不仅会展示代码实现的具体细节,还会介绍使用该模块的实用方法。最终,通过一系列实验结果,直观呈现这一改进对目标检测效果产生的积极且显著的影响。
混合局部通道注意力机制 MLCA 结构深度解析
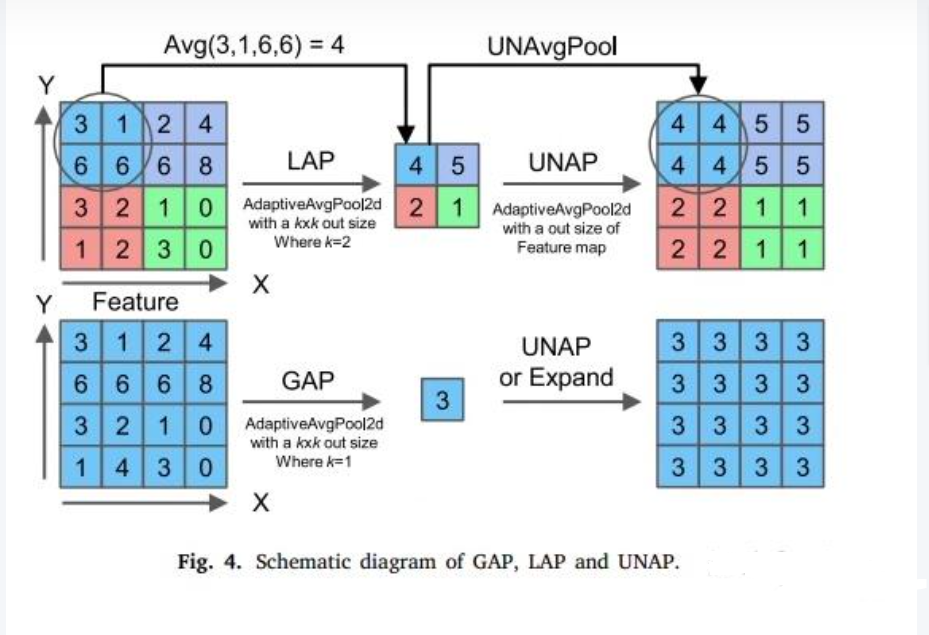
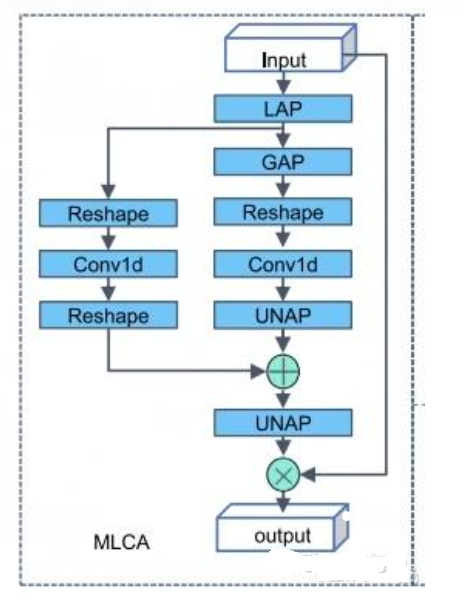
MLCA(Mixed Local - Channel Attention,混合局部通道注意力)作为一种轻量级的注意力机制,专为提升目标检测网络性能而设计。它独具匠心地将局部特征与全局特征、通道特征与空间特征的信息融为一体,极大地增强了网络对关键特征的捕捉能力。
具体而言,MLCA 的工作流程如下:
- 池化操作:对输入的特征图分别进行局部平均池化和全局平均池化。这两种池化操作能够从不同尺度对特征图进行信息提取,局部池化聚焦于局部区域的特征,全局池化则把握整体特征。
- 特征转换:经过池化操作后得到的特征,通过 1D 卷积进行特征转换。1D 卷积能够有效地对特征进行编码和提炼,挖掘出更深层次的特征信息。
- 特征融合:局部池化后的特征与原始输入特征进行融合,这一步骤使得模型在保留原始特征信息的基础上,进一步强化了局部特征的表达能力。而全局池化后的特征则与局部池化特征相结合,实现了局部与全局信息的有机整合。
- 反池化恢复:最后,通过反池化操作将融合后的特征恢复到原始的空间维度,确保输出特征图与输入特征图在空间尺寸上保持一致,以便后续网络层能够顺利处理。
这种方法在保证计算效率的前提下,如同为模型注入了一剂强心针,显著提高了目标检测的精度,为 YOLOv11 模型带来了新的性能突破契机。
【yolov11框架介绍】
2024 年 9 月 30 日,Ultralytics 在其活动 YOLOVision 中正式发布了 YOLOv11。YOLOv11 是 YOLO 的最新版本,由美国和西班牙的 Ultralytics 团队开发。YOLO 是一种用于基于图像的人工智能的计算机模
Ultralytics YOLO11 概述
YOLO11 是Ultralytics YOLO 系列实时物体检测器的最新版本,以尖端的精度、速度和效率重新定义了可能性。基于先前 YOLO 版本的令人印象深刻的进步,YOLO11 在架构和训练方法方面引入了重大改进,使其成为各种计算机视觉任务的多功能选择。
Key Features 主要特点
- 增强的特征提取:YOLO11采用改进的主干和颈部架构,增强了特征提取能力,以实现更精确的目标检测和复杂任务性能。
- 针对效率和速度进行优化:YOLO11 引入了精致的架构设计和优化的训练管道,提供更快的处理速度并保持准确性和性能之间的最佳平衡。
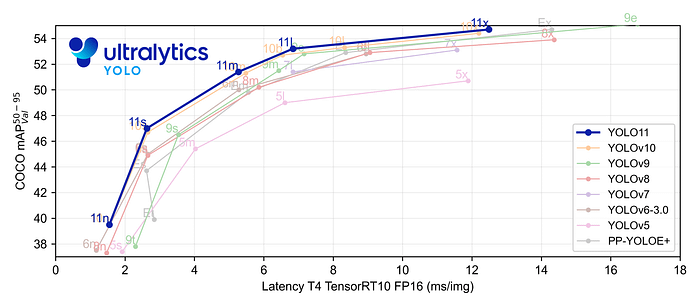
- 使用更少的参数获得更高的精度:随着模型设计的进步,YOLO11m 在 COCO 数据集上实现了更高的平均精度(mAP),同时使用的参数比 YOLOv8m 少 22%,从而在不影响精度的情况下提高计算效率。
- 跨环境适应性:YOLO11可以无缝部署在各种环境中,包括边缘设备、云平台以及支持NVIDIA GPU的系统,确保最大的灵活性。
- 支持的任务范围广泛:无论是对象检测、实例分割、图像分类、姿态估计还是定向对象检测 (OBB),YOLO11 旨在应对各种计算机视觉挑战。

与之前的版本相比,Ultralytics YOLO11 有哪些关键改进?
Ultralytics YOLO11 与其前身相比引入了多项重大进步。主要改进包括:
- 增强的特征提取:YOLO11采用改进的主干和颈部架构,增强了特征提取能力,以实现更精确的目标检测。
- 优化的效率和速度:精细的架构设计和优化的训练管道可提供更快的处理速度,同时保持准确性和性能之间的平衡。
- 使用更少的参数获得更高的精度:YOLO11m 在 COCO 数据集上实现了更高的平均精度(mAP),参数比 YOLOv8m 少 22%,从而在不影响精度的情况下提高计算效率。
- 跨环境适应性:YOLO11可以跨各种环境部署,包括边缘设备、云平台和支持NVIDIA GPU的系统。
- 支持的任务范围广泛:YOLO11 支持多种计算机视觉任务,例如对象检测、实例分割、图像分类、姿态估计和定向对象检测 (OBB)
【测试环境】
windows10 x64
ultralytics==8.3.143
torch==2.3.1
【改进流程】
1. MLCA注意力机制代码(核心模块源码请参考改进步骤.docx)
2. 文件修改步骤
修改tasks.py文件
- 定位文件:在项目目录中找到
ultralytics/nn/tasks.py - 执行修改:
- 在模型解析函数
parse_model中添加MLCA模块处理逻辑 - 具体位置可通过搜索
def parse_model函数快速定位
- 在模型解析函数
创建模型配置文件
- 新建文件:在模型配置目录中创建
yolo11-MLCA.yaml - 文件配置:
- 复制标准yolo11.yaml文件内容
- 在网络结构定义部分将C2PSA替换成C2PSA_MLCA
- 保持其他训练参数与原始配置一致
3. 验证集成
使用新建的yaml配置文件启动训练任务:
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('yolo11-MLCA.yaml') # build from YAML and transfer weights
# Train the model
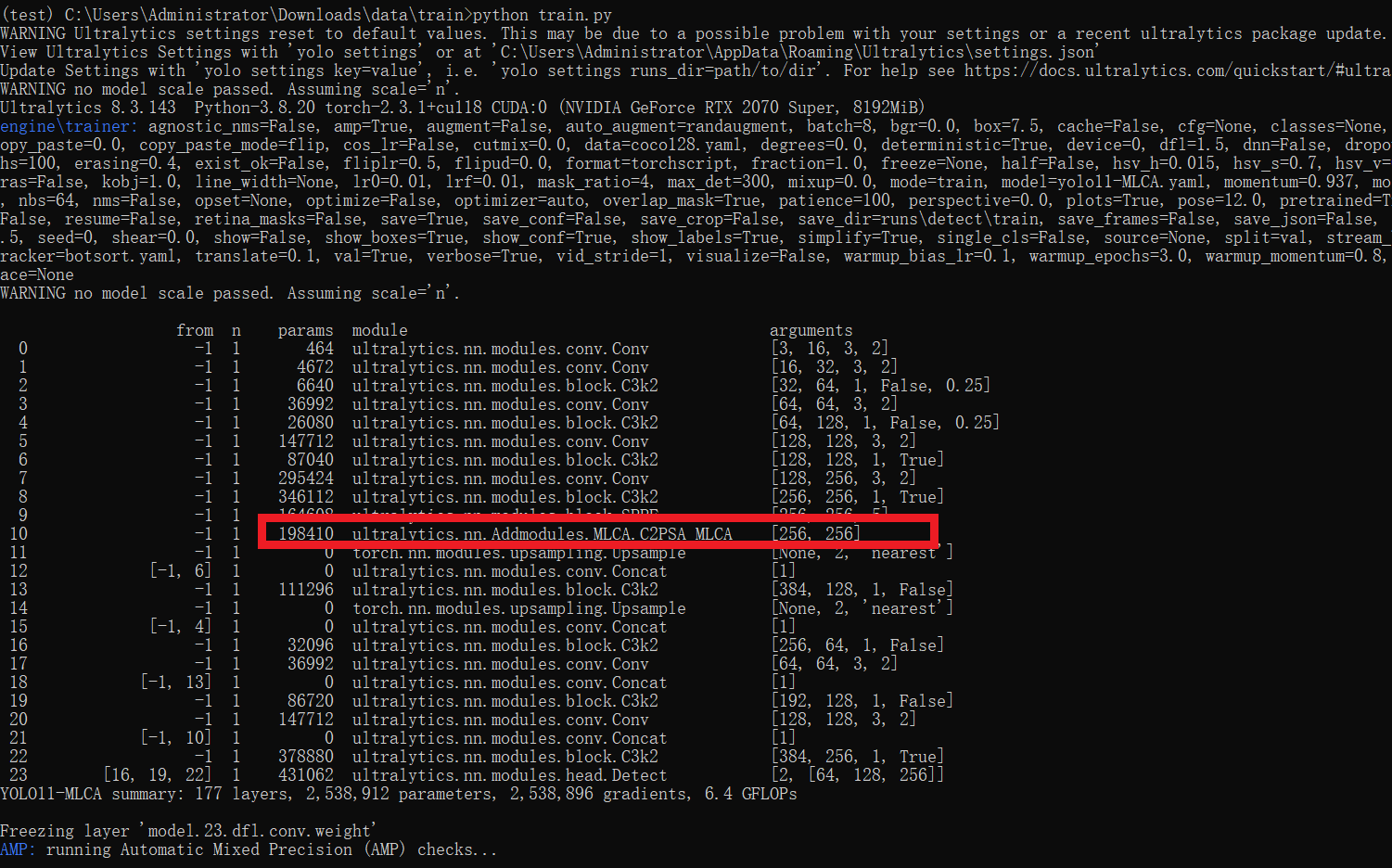
results = model.train(data='coco128.yaml',epochs=100, imgsz=640, batch=8, device=0, workers=1, save=True,resume=False)成功集成后,训练日志中将显示MLCA模块的初始化信息,表明注意力机制已正确加载到模型中。
【训练说明】
第一步:首先安装好yolov11必要模块,可以参考yolov11框架安装流程,然后卸载官方版本pip uninstall ultralytics,最后安装改进的源码pip install .
第二步:将自己数据集按照dataset文件夹摆放,要求文件夹名字都不要改变
第三步:打开train.py修改必要的参数,最后执行python train.py即可训练
【提供文件】
├── [官方版]ultralytics-8.3.143.zip
├── train/
│ ├── coco128.yaml
│ ├── dataset/
│ │ ├── train/
│ │ │ ├── images/
│ │ │ │ ├── firc_pic_1.jpg
│ │ │ │ ├── firc_pic_10.jpg
│ │ │ │ ├── firc_pic_11.jpg
│ │ │ │ ├── firc_pic_12.jpg
│ │ │ │ ├── firc_pic_13.jpg
│ │ │ ├── labels/
│ │ │ │ ├── classes.txt
│ │ │ │ ├── firc_pic_1.txt
│ │ │ │ ├── firc_pic_10.txt
│ │ │ │ ├── firc_pic_11.txt
│ │ │ │ ├── firc_pic_12.txt
│ │ │ │ ├── firc_pic_13.txt
│ │ │ └── labels.cache
│ │ └── val/
│ │ ├── images/
│ │ │ ├── firc_pic_100.jpg
│ │ │ ├── firc_pic_81.jpg
│ │ │ ├── firc_pic_82.jpg
│ │ │ ├── firc_pic_83.jpg
│ │ │ ├── firc_pic_84.jpg
│ │ ├── labels/
│ │ │ ├── firc_pic_100.txt
│ │ │ ├── firc_pic_81.txt
│ │ │ ├── firc_pic_82.txt
│ │ │ ├── firc_pic_83.txt
│ │ │ ├── firc_pic_84.txt
│ │ └── labels.cache
│ ├── train.py
│ ├── yolo11-MLCA.yaml
│ └── 训练说明.txt
├── 【改进】ultralytics-8.3.143.zip
├── 改进原理.docx
└── 改进流程.docx【常见问题汇总】
问:为什么我训练的模型epoch显示的map都是0或者map精度很低?
回答:由于源码改进过,因此不能直接从官方模型微调,而是从头训练,这样学习特征能力会很弱,需要训练很多epoch才能出现效果。此外由于改进的源码框架并不一定能够保证会超过官方精度,而且也有可能会存在远远不如官方效果,甚至精度会很低。这说明改进的框架并不能取得很好效果。所以说对于框架改进只是提供一种可行方案,至于改进后能不能取得很好map还需要结合实际训练情况确认,当然也不排除数据集存在问题,比如数据集比较单一,样本分布不均衡,泛化场景少,标注框不太贴合标注质量差,检测目标很小等等原因
【重要声明】
我们只提供改进框架一种方案,并不保证能够取得很好训练精度,甚至超过官方模型精度。因为改进框架,实际是一种比较复杂流程,包括框架原理可行性,训练数据集是否合适,训练需要反正验证以及同类框架训练结果参数比较,这个是十分复杂且漫长的过程。


















 1250
1250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











