







首先Aurora采用AXIS接口
由于后续需要进行AXIS接口 不同时钟域的数据位宽转换(64bit和256bit之间的转换),因此分两次走。
第一种方法:采用AXIS数据位宽转换IP + AXIS跨时钟域IP
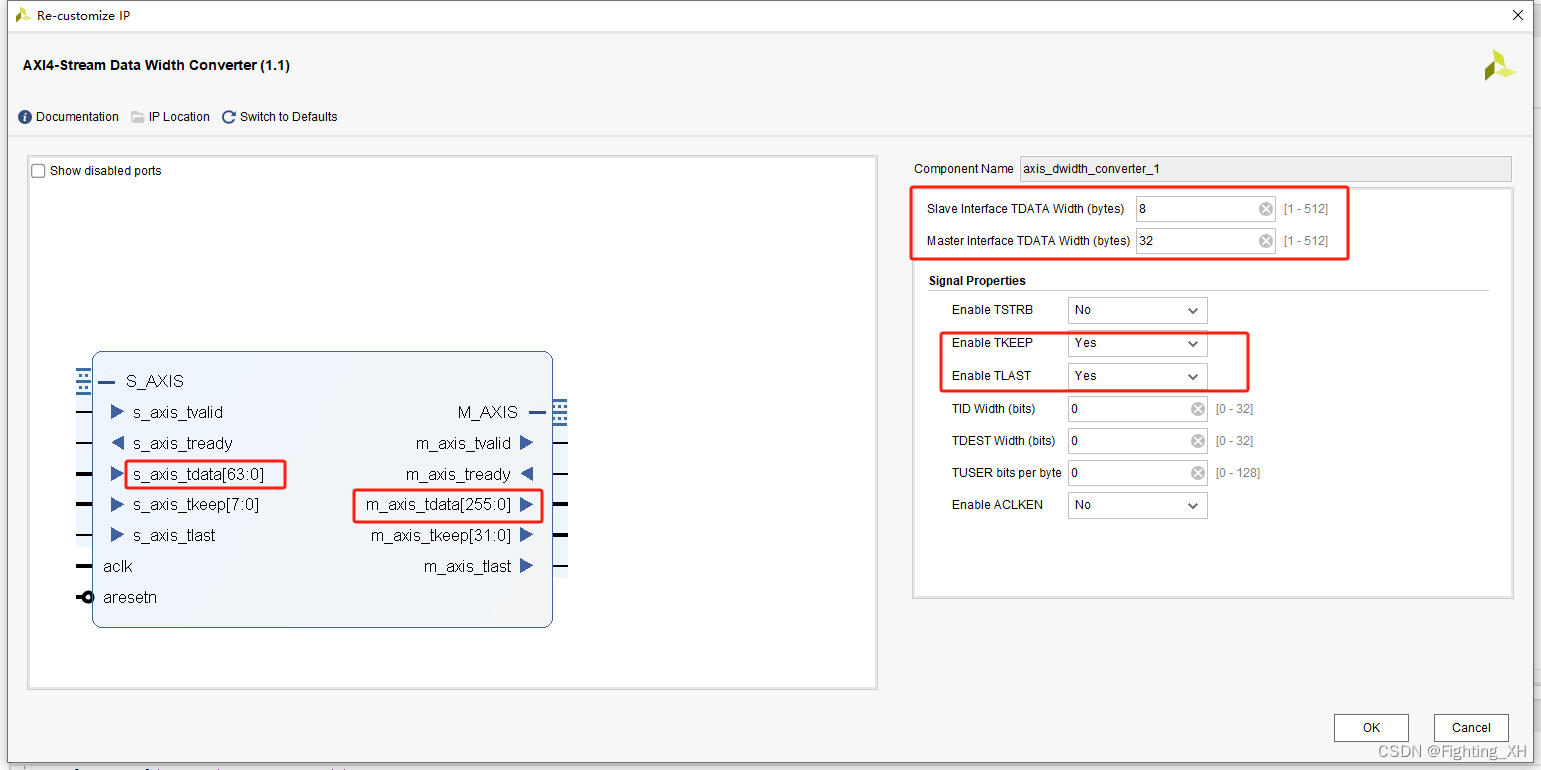
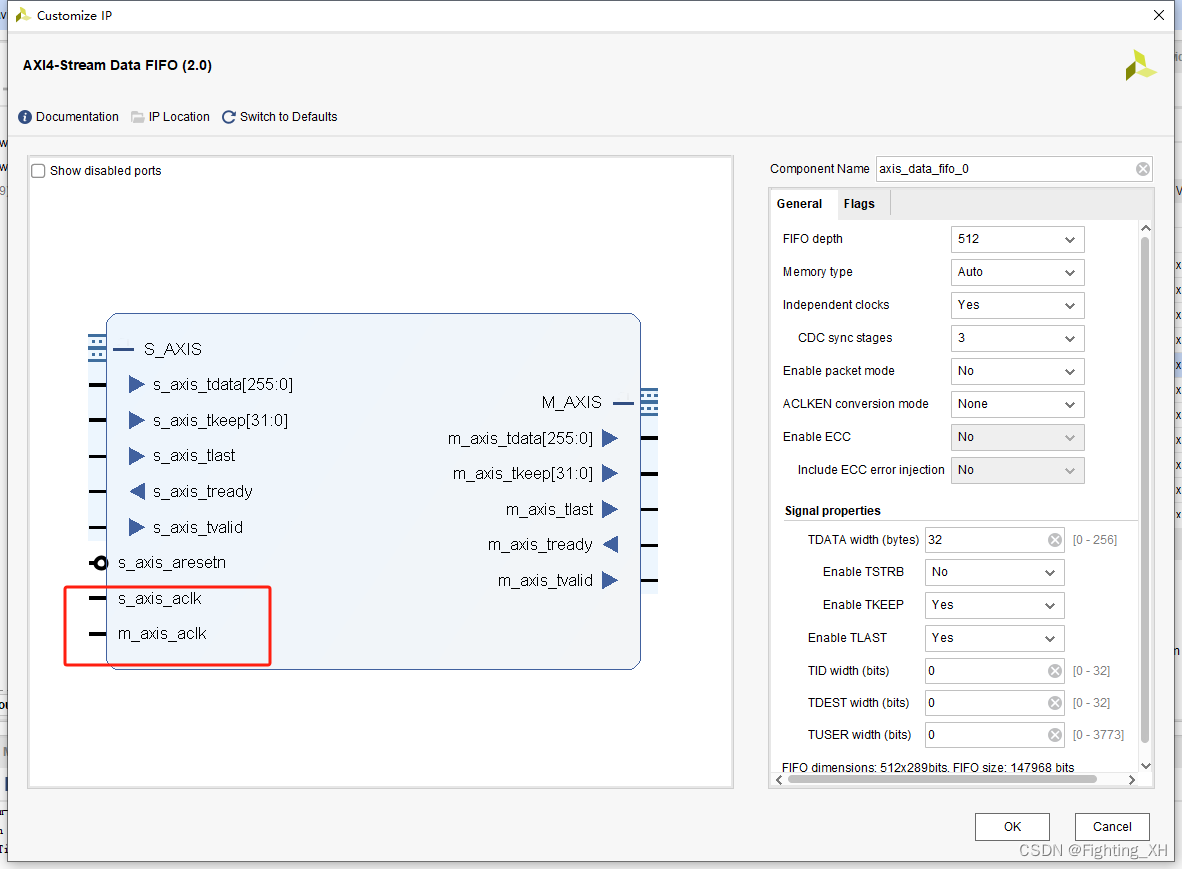
第二种方法:逻辑完成
下面记录逻辑实现方法。
为了能正常仿真,首先根据Aurora时序制造数据包。
s_tvlaid、s_tdata 通过计数器来创造,创造不同长度的数据包,其中包含非4的倍数的数据包、刚好4个数据的数据包,仅一个数据的数据包。
//生成计数器(辅助生成s_tvlaid、s_tdata)
always @(posedge USER_CLK)
if(SYS_RST)
r_cnt50 <= 0;
else if(r_cnt50 == 6'd50)
r_cnt50 <= 0;
else
r_cnt50 <= r_cnt50 + 1'b1;
//生成s_tvalid
assign s_tvalid_en = (((r_cnt50 >= 6'd5) && (r_cnt50 <= 6'd15)) || ((r_cnt50 >= 6'd17)&& (r_cnt50 <= 6'd20)) || (r_cnt50 == 6'd40) ) ? 1 : 0;
assign s_tvalid = r_tvalid;
always @(posedge USER_CLK)
if(s_tvalid_en)
r_tvalid <= 'b1;
else
r_tvalid <= 'b0;
//生成s_tdata
assign s_tdata = r_tdata;
always @(posedge USER_CLK)
if(s_tvalid_en)
r_tdata <= r_tdata + 64'h5; //64'hecff_bc1f
else
r_tdata <= 'b0;
//生成s_tlast_en
assign s_tlast_en = ((r_cnt50 == 6'd15) || (r_cnt50 == 6'd20) || (r_cnt50 == 6'd40)) ? 1: 0 ;
always @(posedge USER_CLK)
if(s_tlast_en)
r_tlast <= 'b1;
else
r_tlast <= 'b0;
assign s_tlast = r_tlast;
//生成s_tkeep
assign s_tkeep = s_tlast ? 8'hff : 8'b0;

接下来就是AXIS接口 64bit转256bit
首先设计256bit移位寄存器
第一种方法:
//设计移位寄存器,先进的放低位
always @(posedge USER_CLK)
if(s_tvalid)
r_s_tdata_SHIFT <= {s_tdata,r_s_tdata_SHIFT[255:64]};
else
r_s_tdata_SHIFT <= r_s_tdata_SHIFT;

第二种方法:
reg [63:0] r1_s_tdata = 'b0;
reg [63:0] r2_s_tdata = 'b0;
reg [63:0] r3_s_tdata = 'b0;
wire [255:0] s_data_256 ;
//s_tdata打三拍
always @(posedge USER_CLK)
begin
r1_s_tdata <= s_tdata ;
r2_s_tdata <= r1_s_tdata;
r3_s_tdata <= r2_s_tdata;
end
assign s_data_256 = {s_tdata,r1_s_tdata,r2_s_tdata,r3_s_tdata};
拼接后的波形图如下:

生成转换后的m_tvalid信号
由于64bit转256,所以比率是4:1
那么生成4计数器,从而指示转换成的256bit数据有效
//设计 4:1计数器
always @(posedge USER_CLK)
begin
if(s_tlast & s_tvalid )
r_CNT2 <= 2'd0 ;
else if(s_tvalid)
r_CNT2 <= r_CNT2 + 1'b1 ;
else
r_CNT2 <= r_CNT2 ;
end
//生成 m_tvalid
always @(posedge USER_CLK)
begin
if(((r_CNT2 == 2'd3) || s_tlast) & s_tvalid)
m_tvalid <= 1'b1 ;
else
m_tvalid <= 1'b0 ;
end
生成tlast信号,不管数据包是不是4的倍数,总会被移入256bit寄存器,转换后的m_tlast信号相当于是比之前的s_talst晚一拍
//生成m_tlast
always @(posedge USER_CLK)
begin
if( s_tlast & s_tvalid)
m_tlast <= 1'b1 ;
else
m_tlast <= 1'b0 ;
end
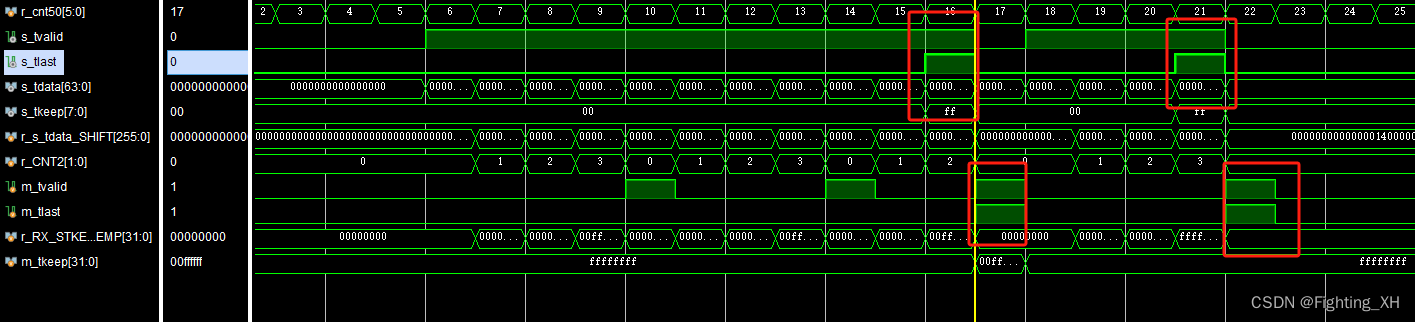
生成m_tkeep ,首先确定最后一个256bit数据,即m_tlast对应的256bit数据的m_tkeep值,这里根据移入寄存器的个数有关。
也就是说,当计数器为0的表示,还没移入数据;当为1移入第一个64bit数据,因此是八个字节有效,所以最后一个数据位置的m_tkeep的低八位为1,即可8‘hff,以此类推。
从而确定最终的m_tkeep值。
//生成m_tkeep
always @(*)
begin
case(r_CNT2)
2'd0 : r_tkeep_TEMP = { 8'h00 , 8'h00, 8'h00 , s_tkeep } ;
2'd1 : r_tkeep_TEMP = { 8'h00 , 8'h00, s_tkeep , 8'hff } ;
2'd2 : r_tkeep_TEMP = { 8'h00 , s_tkeep , 8'hff , 8'hff } ;
2'd3 : r_tkeep_TEMP = { s_tkeep , 8'hff , 8'hff , 8'hff } ;
default : r_tkeep_TEMP = 32'd0 ;
endcase
end
//s_tlast位置对应的tkeep
always @(posedge USER_CLK)
begin
if(s_tlast & s_tvalid)
m_tkeep <= r_tkeep_TEMP ;
else
m_tkeep <= 32'hffff_ffff;
end
由于我们发的第一个数据包中有11个64bit数据,因此最后一拍256bit数据中仅包含3个64bit数据,所以24个字节有效,因此m_tkeep的高两位为0,剩下为f。

把拼接后的256bit数据取出来。
重点在于,取出的256bit数据要保证在m_tvalid时刻有效,不然是不符合axis接口时序的,后续没办法使用。
//把拼接数据取出
reg [255:0] r_s_data_256 = 'b0 ;
reg [255:0] data_256_1 = 'b0 ;
wire [255:0] data_256_2 ;
reg [255:0] r_STDATA = 'b0 ;
reg [255:0] r_s_tdata_tmp = 'b0 ;
reg [255:0] r_STDATA_1 = 'b0 ;
always @(posedge USER_CLK)
r_s_data_256 <= s_data_256;
always @(posedge USER_CLK)
if(m_tvalid)
data_256_1 <= r_s_data_256;
else
data_256_1 <= data_256_1;
assign data_256_2 = m_tvalid ? r_s_data_256 :'b0 ;
always @(posedge USER_CLK)
begin
if(((r_CNT2 == 2'd3) || s_tlast) & s_tvalid)
r_STDATA <= s_data_256;
else
r_STDATA <= r_STDATA;
end
//方法二
always @(*)
begin
case(r_CNT2)
2'd0 : r_s_tdata_tmp = { 8'h00 , 8'h00, 8'h00 , s_tdata } ;
2'd1 : r_s_tdata_tmp = { 8'h00 , 8'h00, s_tdata , r_s_tdata_SHIFT[255:192] } ;
2'd2 : r_s_tdata_tmp = { 8'h00 , s_tdata , r_s_tdata_SHIFT[255:128] } ;
2'd3 : r_s_tdata_tmp = { s_tdata , r_s_tdata_SHIFT[255:64] } ;
default : r_s_tdata_tmp = 256'd0 ;
endcase
end
always @(posedge USER_CLK)
begin
if(((r_CNT2 == 2'd3) || s_tlast) & s_tvalid)
r_STDATA_1 <= r_s_tdata_tmp;
else
r_STDATA_1 <= r_STDATA_1;
end
简单记录一下该方法,后面还要用到,还需要在好好理解一下,尤其是转换前后tready信号,还是不大懂。















 3767
3767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











