







年少不知记笔记,老来方恨看不懂……本文从三方面进行,首先是卡尔曼滤波的思想,然后对卡尔曼滤波进行公式推导,最后是对卡尔曼滤波进行总结。
核心思想
取自知乎Kent Zeng的回答:点击链接,我对他的回答进行了例子的补充。
1、假设你有两个传感器,测的是同一个信号。可是它们每次的读数都不太一样,怎么办?
取平均。
2、再假设你知道其中贵的那个传感器应该准一些,便宜的那个应该差一些。那有比取平均更好的办法吗?
加权平均。
怎么加权?假设两个传感器的误差都符合正态分布,假设你知道这两个正态分布的方差,用这两个方差值,(此处省略若干数学公式),你可以得到一个“最优”的权重。
Example:比如GPS和IMU测量值,GPS可以测量你走过的路,IMU也可以,它们的误差都满足正态分布,那我们也可以通过它们的误差协方差矩阵调整权重进行融合。
3、接下来,重点来了:假设你只有一个传感器,但是你还有一个数学模型。模型可以帮你算出一个值,但也不是那么准。怎么办?
把模型算出来的值,和传感器测出的值,(就像两个传感器那样),取加权平均。
Example:一个机器人当前状态是5米每秒,做匀速运动,且搭载雷达可测距,当前机器人距离障碍物20米,下一秒我们可以通过数学模型预测得到机器人距离障碍物还有15米(估计值),而此时雷达测距17米(观测值),然后我们就要看估计值和观测值的准确度,其实就是方差(多元的话是协方差矩阵),方差大权重就低,反之则高。
痛苦的证明
又到了痛苦的时候。
首先搞清楚几个概念:
预测值:通过预测方程得到的值,有噪声
观测值:通过观测方程得到的值,有噪声
估计值:最后得到的值,有噪声
标准值:无噪声,不可能得到的值
误差协方差:描述这个值的可信度,越小越好
我们要得到什么?
K时刻刚开始到来的时候,我们拥有K-1时刻的估计值以及它的误差协方差(可信度)。
那么K时刻结束时,我们要求拥有K时刻的估计值以及它的误差协方差(可信度)。
预测
状态转移方程&预测值
假设一台车的状态可以表示为位置和速度,假设有一台车,正在做加速运动(也就是有加速度),那么他的运动方程可以写成这种形式:
p
k
=
p
k
−
1
+
Δ
t
v
k
−
1
+
1
2
a
Δ
t
2
v
k
=
v
k
−
1
+
a
Δ
t
\begin{array}{l} {p_{k}=p_{k-1}+\Delta t v_{k-1}+\frac{1}{2} a \Delta t^{2}} \\ {v_{k}=\quad v_{k-1}+a \Delta t} \end{array}
pk=pk−1+Δtvk−1+21aΔt2vk=vk−1+aΔt
写成矩阵的形式,有:

这个又称为k-1时刻到k时刻的状态转移方程,
x
^
k
′
\hat{x}_k^{\prime}
x^k′指的是预测值。
B
k
B_k
Bk称为控制矩阵,
u
k
→
\overrightarrow{\mathbf{u}_{k}}
uk称为控制向量,这个项(
B
k
u
k
→
B_k\overrightarrow{\mathbf{u}_k}
Bkuk)可有可无(比如说小车做匀速运动时就没有),
x
^
k
−
1
\hat{x}_{k-1}
x^k−1指的是上一时刻的卡尔曼滤波的估计值。
预测值的误差协方差矩阵
来看一下预测值
x
^
k
′
\hat{x}_k^{\prime}
x^k′的误差协方差矩阵,也就是预测值的可信度。请注意,有一些外力是我们无法预测的,比如在运动的过程中,道路有坑洼,导致它的速度或者加速度并不是预想的那样,仅使用预测方程去预测是有误差的,该时刻的预测噪声
w
k
w_k
wk服从
N
(
0
,
Q
k
)
N(0,Q_k)
N(0,Qk)(又称为过程噪声),同时,这个预测值还会受到上一时刻的估计值误差协方差的影响。
由:
x
^
k
′
=
F
k
x
^
k
−
1
+
B
k
u
→
k
+
w
k
{\hat{{x}}_{k}^{\prime}={F}_{k} \hat{{x}}_{k-1}+{B}_{k} \overrightarrow{{u}}_{k}} + w_k
x^k′=Fkx^k−1+Bkuk+wk
算得预测状态的误差协方差:(交叉项为0,因为互相独立)
P
^
k
′
=
E
[
e
^
k
′
T
e
^
k
′
]
=
E
[
(
x
k
−
x
^
k
′
)
(
x
k
−
x
^
k
′
)
T
]
=
E
[
(
F
k
x
^
k
′
)
(
F
k
x
^
k
′
)
T
]
+
Q
k
=
F
k
P
k
−
1
F
k
+
Q
k
\hat{P}_k^{\prime} = E[{{\hat{e}_k}^{\prime}}^T\hat{e}_k^{\prime}]\\ = E[(x_k - \hat{x}_k^{\prime})(x_k - \hat{x}_k^{\prime})^T] \\= E[(F_k\hat{x}_k^{\prime})(F_k\hat{x}_k^{\prime})^T] + Q_k \\ = F_kP_{k-1}F_k + Q_k
P^k′=E[e^k′Te^k′]=E[(xk−x^k′)(xk−x^k′)T]=E[(Fkx^k′)(Fkx^k′)T]+Qk=FkPk−1Fk+Qk
上述
x
k
x_k
xk指的是标准值,标准值-预测值的协方差,我们成为误差协方差。
这个
Q
k
Q_k
Qk要怎么获得?无法获得,但可以根据一些算法帮助我们找到适合的值。
至此,预测结束:
x
^
k
′
=
F
k
x
^
k
−
1
+
B
k
u
→
k
+
w
k
P
k
′
^
=
F
k
P
k
−
1
F
k
T
+
Q
k
\begin{array}{l} {\hat{{x}}_{k}^{\prime}={F}_{k} \hat{{x}}_{k-1}+{B}_{k} \overrightarrow{{u}}_{k}} + w_k \\ {{\hat{{P}_{k}^{\prime}}}={F}_{{k}} {P}_{k-1} {F}_{k}^{T}+{Q}_{k}} \end{array}
x^k′=Fkx^k−1+Bkuk+wkPk′^=FkPk−1FkT+Qk
我们获得了预测值,以及预测的误差协方差矩阵。
更新
获得估计值
现在,有一个额外的传感器来辅助我们得到相对正确的状态,比如说车轮表盘。在k-1时刻和k时刻之间,我们可以知道车轮转了多少圈,每一个瞬间转多少度,这和状态(位移以及速度)是有一个转化关系的,下面的 H k H_k Hk就是一个转移矩阵,故有车轮的信息和状态的转移方程为: Z k ′ ^ = H k x ^ k ′ \hat{Z_k^{\prime}}= H_k\hat{\mathbf{x}}_{k}^{\prime} Zk′^=Hkx^k′
Z k ′ ^ \hat{Z_k^{\prime}} Zk′^指的是预测值与转移矩阵相乘得到和车轮一致的信息,为什么要这么做,因为要相减得到残差,得保持量纲一致。
此时状态的估计值可以表示为:
x
^
k
=
x
^
k
′
+
K
k
(
Z
k
−
H
k
x
^
k
′
)
\hat{x}_{k}=\hat{x}_{k}^{\prime}+K_{k}\left(Z_{k}-H_k\hat{x}_{k}^{\prime}\right)
x^k=x^k′+Kk(Zk−Hkx^k′)
没错,你没看错,是估计值。
上面式子表示的意思就是估计值= 预测值 + 卡尔曼增益*(转换矩阵*预测值 - 观测值 )。这个估计状态值就是我们卡尔曼滤波后得到的值。
x
^
k
\hat{x}_k
x^k表示的是最后的状态估计值,
K
k
K_k
Kk表示的是卡尔曼增益,
Z
k
Z_k
Zk表示的是观测值(按上文所说就是车轮的状态,转多少圈,转多快),这个观测值是传感器得到的。将预测的状态值与转移矩阵H相乘,得到和
Z
k
Z_k
Zk相同的量纲,把
r
e
s
i
d
u
a
l
=
(
Z
k
−
H
x
k
^
′
)
residual = (Z_k - H\hat{x_k}^{\prime})
residual=(Zk−Hxk^′)视为残差,也就是观测值和预测值的差值。
其中观测值
Z
k
Z_k
Zk也一样具有误差,我们可以把观测值分为两块:
Z
k
=
H
k
x
k
+
v
k
①
Z_k = H_kx_k + v_k \ ①
Zk=Hkxk+vk ①
x
k
x_k
xk表示的是标准值,无噪声的,
v
k
v_k
vk为噪声,服从
N
(
0
,
R
k
)
N(0,R_k)
N(0,Rk)高斯分布,这个是传感器的噪声,这个协方差要怎么取,有可能传感器厂家会大致告诉你一个范围,总之,在这里我们把它当成已知的就好了。
现在,我们知道了预测值,也知道了观测值,那卡尔曼增益 K k K_k Kk要怎么算?卡尔曼增益又是啥?
卡尔曼增益
首先,卡尔曼增益可以看成是一个权重。根据上述式子,我们得到了两个值,预测值和观测值,简单来说,要想得到最后的估计值,那我们就可以把两者进行加权平均。因此,卡尔曼增益的作用,就是分配模型预测的状态和传感器测量的状态之间的权重。
接下来,让我们来算一算卡尔曼增益,在算卡尔曼增益之前,我们先算算估计值的误差协方差是怎么样一个形态。
估计值的误差协方差可以由如下式子算出:
P k = E [ e ^ k e ^ k T ] = E [ ( x k − x ^ k ) ( x k − x ^ k ) T ] ② P_{k}=E\left[\hat{e}_{k} \hat{e}_{k}^{T}\right]=E\left[\left(x_{k}-{\hat{x}}_{k}\right)\left(x_{k}-{\hat{x}}_{k}\right)^{T}\right] \ ② Pk=E[e^ke^kT]=E[(xk−x^k)(xk−x^k)T] ②
由把①代入③,得:
x
^
k
=
x
^
k
′
+
K
k
(
H
x
k
+
v
k
−
H
x
^
k
′
)
③
{\hat{x}}_{k}=\hat{x}_{k}^{\prime}+K_{k}\left(H x_{k}+v_{k}-H \hat{x}_{k}^{\prime}\right) \ ③
x^k=x^k′+Kk(Hxk+vk−Hx^k′) ③
故对③式左右两侧同时取负并加上标准值
x
k
x_k
xk,得:
x
k
−
x
^
k
=
x
k
−
[
x
^
k
′
+
K
k
(
H
x
k
+
v
k
−
H
x
^
k
′
)
]
④
x_k-{\hat{x}}_{k}=x_k-[\hat{x}_{k}^{\prime}+K_{k}\left(H x_{k}+v_{k}-H \hat{x}_{k}^{\prime}\right)] \ ④
xk−x^k=xk−[x^k′+Kk(Hxk+vk−Hx^k′)] ④
把④代入②,合并同类项,估计值的误差协方差有:
P
k
=
E
[
[
(
I
−
K
k
H
)
(
x
k
−
x
k
′
^
)
−
K
k
v
k
]
[
(
I
−
K
k
H
)
(
x
k
−
x
k
′
^
)
−
K
k
v
k
]
T
]
⑤
\begin{aligned} P_{k}=E &\left[\left[\left(I-K_{k} H\right)\left(x_{k}-\hat{{x}_{k}^{\prime}}\right)-K_{k} v_{k}\right]\right.\\ &\left.\left[\left(I-K_{k} H\right)\left(x_{k}-\hat{{x}_{k}^{\prime}}\right)-K_{k} v_{k}\right]^{T}\right ] \ ⑤ \end{aligned}
Pk=E[[(I−KkH)(xk−xk′^)−Kkvk][(I−KkH)(xk−xk′^)−Kkvk]T] ⑤
对其展开:
P
k
=
(
I
−
K
k
H
)
E
[
(
x
k
−
x
k
′
^
)
(
x
k
−
x
k
′
^
)
T
]
(
I
−
K
k
H
)
+
K
k
E
[
v
k
v
k
T
]
K
k
T
⑥
\begin{aligned} P_{k} &=\left(I-K_{k} H\right) E\left[\left(x_{k}-\hat{{x}_{k}^{\prime}}\right)\left(x_{k}-\hat{{x}_{k}^{\prime}}\right)^{T}\right]\left(I-K_{k} H\right) \\ &+\quad K_{k} E\left[v_{k} v_{k}^{T}\right] K_{k}^{T} \end{aligned} \ ⑥
Pk=(I−KkH)E[(xk−xk′^)(xk−xk′^)T](I−KkH)+KkE[vkvkT]KkT ⑥
咦?上面噪声项和残差项的结合去哪了?由于噪声和估计值是互相独立的,而噪声的期望又为0,所以为0呀! v k v_k vk服从 N ( 0 , R k ) N(0,R_k) N(0,Rk),而 E [ ( x k − x k ^ ) ( x k − x k ^ ) T ] E[(x_k-\hat{x_k})(x_k - \hat{x_k})^T] E[(xk−xk^)(xk−xk^)T] 为预测值的协方差矩阵 P k ′ {P_k}^{\prime} Pk′,最开始的时候我们已经求过了。
故⑥式可以写成:
P
k
=
(
I
−
K
k
H
)
P
k
′
(
I
−
K
k
H
)
T
+
K
k
R
K
k
T
P_{k}=\left(I-K_{k} H\right) {P_{k}^{\prime}}\left(I-K_{k} H\right)^{T}+K_{k} R K_{k}^{T}
Pk=(I−KkH)Pk′(I−KkH)T+KkRKkT
矩阵对角量相加为矩阵的迹,误差协方差矩阵的迹是均方误差的总和。因此,通过减小
P
k
P_k
Pk的迹可以减少均方误差,我们用
T
[
.
]
T[.]
T[.]表示矩阵的迹,有:
T
[
P
k
]
=
T
[
P
k
′
]
−
2
T
[
K
k
H
P
k
′
]
+
T
[
K
k
(
H
P
k
′
H
T
+
R
)
K
k
T
]
T\left[P_{k}\right]=T\left[{P_{k}^{\prime}}\right]-2 T\left[K_{k} H {P_{k}^{\prime}}\right]+T\left[K_{k}\left(H {P_{k}^{\prime}} H^{T}+R\right) K_{k}^{T}\right]
T[Pk]=T[Pk′]−2T[KkHPk′]+T[Kk(HPk′HT+R)KkT]
有了估计值误差协方差的形式,回到刚刚的问题,
K
k
K_k
Kk要怎么取值呢?我们的目的是得到协方差最小的估计值,所以我们最小化估计值的误差协方差即可,简单来说就是说找一个误差最小的估计值。
所以对于上式,我们令
K
k
K_k
Kk为变量,并对其求导令式子为0(这个是高中数学的内容了,一阶导数为零说明是极值点):
d
T
[
P
k
]
d
K
k
=
−
2
(
H
P
k
′
)
T
+
2
K
k
(
H
P
k
′
H
T
+
R
)
=
0
\frac{d T\left[P_{k}\right]}{d K_{k}}=-2\left(H {P_{k}^{\prime}}\right)^{T}+2 K_{k}\left(H {P_{k}^{\prime}}H^{T}+R\right) = 0
dKkdT[Pk]=−2(HPk′)T+2Kk(HPk′HT+R)=0
有:
K
k
=
P
k
′
H
T
(
H
P
k
′
H
T
+
R
)
−
1
K_k = P_k^{\prime}H^T(HP_k^{\prime}H^T + R ) ^{-1}
Kk=Pk′HT(HPk′HT+R)−1
哦?这卡尔曼增益
K
k
K_k
Kk不就出来了吗?(美滋滋)上面的量都是已知的。
由此我们就知道了预测+更新融合出来的估计值
x
^
k
\hat{x}_k
x^k(把K待进去即可)以及卡尔曼增益
K
k
K_k
Kk,但还没完呢……
估计值的误差协方差
还得把
K
k
K_k
Kk代进入求一下估计值的误差协方差矩阵呀,也就是
P
k
P_k
Pk:
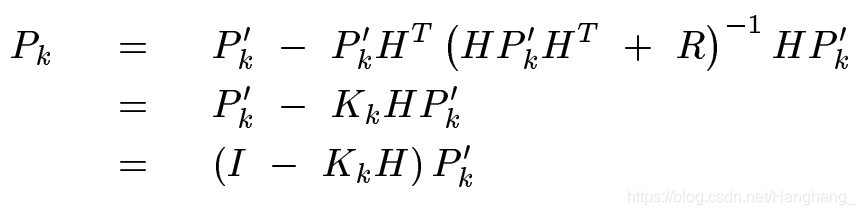
以上,证明完毕……
理清思路
1、我们拥有上一时刻的估计值,上一时刻估计值的误差协方差矩阵。
2、通过数学模型计算预测值、以及预测值和真实值之间的误差协方差矩阵。
3、计算卡尔曼增益,并得到估计值。
4、计算估计值与标准值之间的误差协方差矩阵。
扩展卡尔曼滤波
扩展卡尔曼滤波和卡尔曼滤波的不同之处就在于,他的状态转移方程和观测方程是非线性的,我们只需要对两方程进行泰勒展开即可。
参考文献:
证明过程参考此处
https://www.jianshu.com/p/9214a94b26ca
https://blog.csdn.net/victor_zy/article/details/82862904
https://www.cnblogs.com/bonelee/p/9210821.html
https://zh.wikipedia.org/wiki/%E5%8D%A1%E5%B0%94%E6%9B%BC%E6%BB%A4%E6%B3%A2














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









