






论文地址:https://browse.arxiv.org/pdf/1911.09516.pdf
github:https://gitcode.net/mirrors/ruinmessi/asff?utm_source=csdn_github_accelerator
1.是什么?
ASFF(Adaptive Structure Feature Fusion)网络是一种用于目标检测的神经网络模型。它是基于Faster R-CNN框架的一种改进,旨在提高特征融合的效果,从而改善目标检测的准确性和性能。
ASFF网络引入了自适应结构特征融合模块,用于融合多个不同层次的特征图。传统的目标检测网络通常只使用单一层次的特征图,而ASFF网络通过动态地选择和融合多层特征图,使得网络能够更好地捕捉目标的多尺度信息。
ASFF网络首先通过主干网络提取不同层次的特征图。然后,它使用自适应的注意力机制来对这些特征图进行加权融合,以便更好地保留重要的特征信息。最后,融合后的特征被传递给目标检测头部进行目标分类和定位。
相比传统的目标检测方法,ASFF网络在准确性和性能方面都有所提高。它能够更好地捕捉目标的多尺度信息,从而在目标检测任务中取得更好的效果。
2.为什么?
特征金字塔的一大缺点是不同尺度特征的不一致性,特别是对于一阶段检测器。确切地说,在FPN形式的网络中启发式地选择特征,高层语义信息中检测大目标、低层语义信息中检测小目标。当某个目标在某一层被当做正类时,相应地该目标区域在其它层被当做负类。如果一幅图像中既有大目标也有小目标,那么不同层间的特征的不一致性将会影响最后检测结果(大目标的检测在某一层,小目标的检测在另一层,但是网络的多尺寸检测不会仅仅检测一个特定的区域,而是综合整幅图进行检测。在特征融合时,其它层很多无用的信息也会融合进来)。
3.怎么样?
3.1 网络结构图
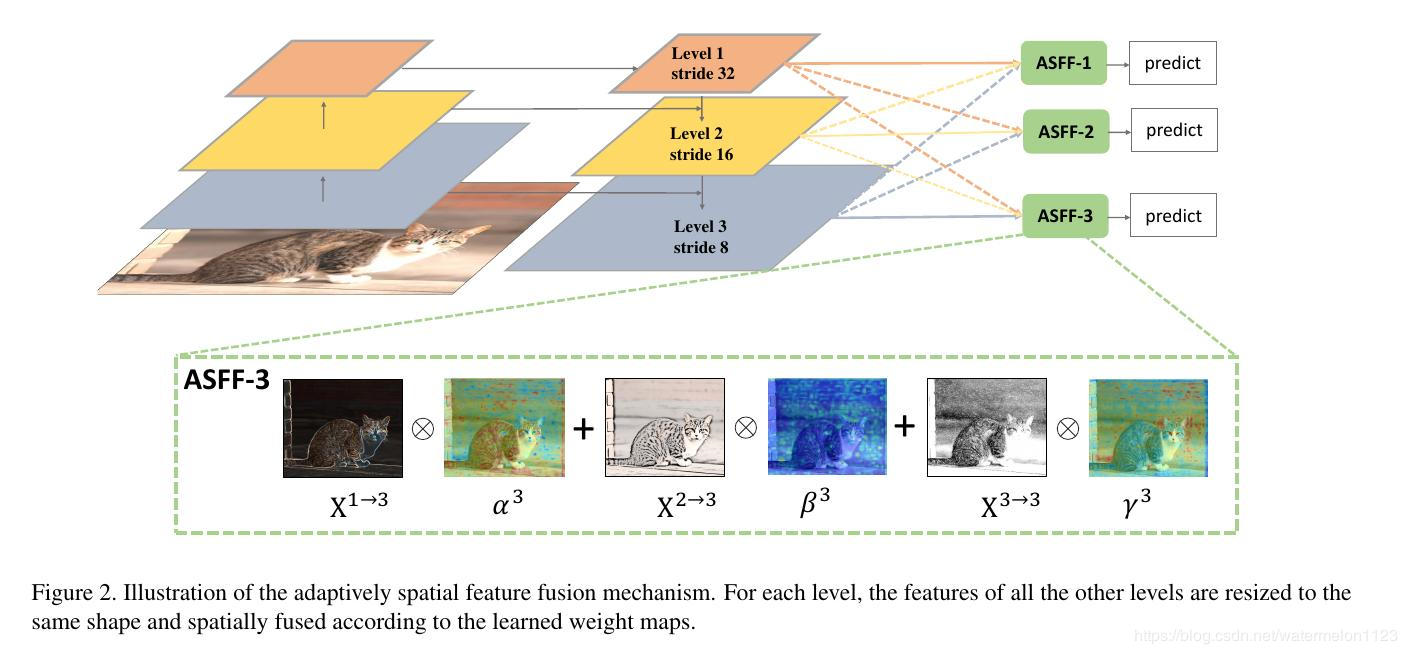
ASFF的关键思想是自适应地学习每个尺度特征图的融合空间权重,分为两步:恒等缩放和自适应融合。
3.2恒等缩放、
- 对于ASFF-1:对level-3的特征图做3x3MaxPool(stride=2)+3x3Conv(stride=2)得到
. 对level-2的特征图做3x3Conv(stride=2)得到
.
- 对于ASFF-2:对level-3的特征图做3x3Conv(stride=2)得到
. 对level-1的特征图做1x1Conv,并resize到原图分辨率2倍大小得到
.
- 对于ASFF-3:对level-2的特征图做1x1Conv,并resize到原图分辨率2倍大小,得到
对level-1的特征图做1x1Conv,并resize到原图分辨率4倍大小,得到
3.3自适应融合
以ASFF-3为例,图中的绿色框描述了如何将特征进行融合,其中X1,X2,X3分别为来自level,level2,level3的特征,与为来自不同层的特征乘上权重参数α3,β3和γ3并相加,就能得到新的融合特征ASFF-3,如下面公式所示:
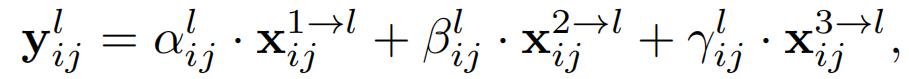
对于权重参数α,β和γ,则是通过resize后的level1~level3的特征图经过1×1的卷积得到的。并且参数α,β和γ经过concat之后通过softmax使得他们的范围都在[0,1]内并且和为1:
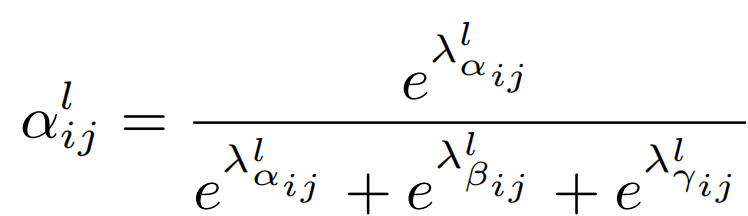
3.4 代码实现
class ASFF(nn.Module):
def __init__(self, level, rfb=False, vis=False):
super(ASFF, self).__init__()
self.level = level
self.dim = [512, 256, 256]
self.inter_dim = self.dim[self.level]
# 每个level融合前,需要先调整到一样的尺度
if level==0:
self.stride_level_1 = add_conv(256, self.inter_dim, 3, 2)
self.stride_level_2 = add_conv(256, self.inter_dim, 3, 2)
self.expand = add_conv(self.inter_dim, 1024, 3, 1)
elif level==1:
self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1)
self.stride_level_2 = add_conv(256, self.inter_dim, 3, 2)
self.expand = add_conv(self.inter_dim, 512, 3, 1)
elif level==2:
self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1)
self.expand = add_conv(self.inter_dim, 256, 3, 1)
compress_c = 8 if rfb else 16 #when adding rfb, we use half number of channels to save memory
self.weight_level_0 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_1 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_2 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_levels = nn.Conv2d(compress_c*3, 3, kernel_size=1, stride=1, padding=0)
self.vis= vis
def forward(self, x_level_0, x_level_1, x_level_2):
if self.level==0:
level_0_resized = x_level_0
level_1_resized = self.stride_level_1(x_level_1)
level_2_downsampled_inter =F.max_pool2d(x_level_2, 3, stride=2, padding=1)
level_2_resized = self.stride_level_2(level_2_downsampled_inter)
elif self.level==1:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized =F.interpolate(level_0_compressed, scale_factor=2, mode='nearest')
level_1_resized =x_level_1
level_2_resized =self.stride_level_2(x_level_2)
elif self.level==2:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized =F.interpolate(level_0_compressed, scale_factor=4, mode='nearest')
level_1_resized =F.interpolate(x_level_1, scale_factor=2, mode='nearest')
level_2_resized =x_level_2
level_0_weight_v = self.weight_level_0(level_0_resized)
level_1_weight_v = self.weight_level_1(level_1_resized)
level_2_weight_v = self.weight_level_2(level_2_resized)
levels_weight_v = torch.cat((level_0_weight_v, level_1_weight_v, level_2_weight_v),1)
# 学习的3个尺度权重
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
# 自适应权重融合
fused_out_reduced = level_0_resized * levels_weight[:,0:1,:,:]+\
level_1_resized * levels_weight[:,1:2,:,:]+\
level_2_resized * levels_weight[:,2:,:,:]
out = self.expand(fused_out_reduced)
if self.vis:
return out, levels_weight, fused_out_reduced.sum(dim=1)
else:
return out
参考:【论文笔记】:ASFF:Learning Spatial Fusion for Single-Shot Object Detection

















 405
405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









