







基于YOLOv5s的暴力行为检测系统设计与实现
一、引言
随着社会安全需求的不断提升,智能视频监控系统在公共场所的应用日益广泛。暴力行为检测作为智能监控的重要组成部分,能够实时识别打架、斗殴等危险行为,及时发出警报,有效提升公共安全水平。

传统的暴力行为检测方法主要依赖人工监控或基于手工特征的机器学习算法,存在效率低、误报率高的问题。近年来,深度学习技术在目标检测领域取得了显著进展,其中YOLO(You Only Look Once)系列算法因其出色的实时性能而备受关注。本文将详细介绍基于YOLOv5s模型进行暴力行为检测的系统设计与实现。
二、YOLOv5s模型概述
YOLOv5是Ultralytics公司于2020年推出的目标检测算法,相比前代YOLO版本,在精度和速度上都有显著提升。YOLOv5系列包含s、m、l、x四种不同规模的模型,其中YOLOv5s(small版本)具有最小的模型尺寸和最快的推理速度,非常适合部署在资源有限的边缘设备上。
YOLOv5s的网络结构主要包含以下组件:
- Backbone:采用CSPDarknet53结构,通过跨阶段部分连接(Cross Stage Partial connections)减少计算量的同时保持特征提取能力
- Neck:使用PANet(Path Aggregation Network)进行多尺度特征融合,增强对不同尺寸目标的检测能力
- Head:采用与YOLOv3类似的检测头,输出三个不同尺度的特征图以检测不同大小的目标
YOLOv5s的输入图像尺寸默认为640×640,在COCO数据集上可达27.4mAP的精度,同时保持超过140FPS的推理速度(在Tesla V100 GPU上)。
三、暴力行为检测系统设计
3.1 系统架构
基于YOLOv5s的暴力行为检测系统主要包括以下模块:
- 数据采集模块:从监控摄像头或视频文件中获取视频流
- 预处理模块:对输入图像进行尺寸调整、归一化等操作
- 行为检测模块:使用YOLOv5s模型检测暴力行为
- 后处理模块:对检测结果进行非极大值抑制(NMS)等处理
- 报警模块:当检测到暴力行为时触发报警机制
- 可视化模块:将检测结果实时显示在监控画面上
3.2 暴力行为定义与标注
暴力行为的准确定义对模型性能至关重要。在本系统中,我们将暴力行为定义为包括但不限于以下动作:
- 拳击
- 踢打
- 持械攻击
- 掐脖子
- 多人斗殴
数据标注采用YOLO格式,每个标注文件包含:
- 目标类别
- 边界框中心坐标(x,y)
- 边界框宽度和高度(w,h)
所有坐标参数均为相对于图像宽高的归一化值(0-1之间)。
3.3 模型训练与优化
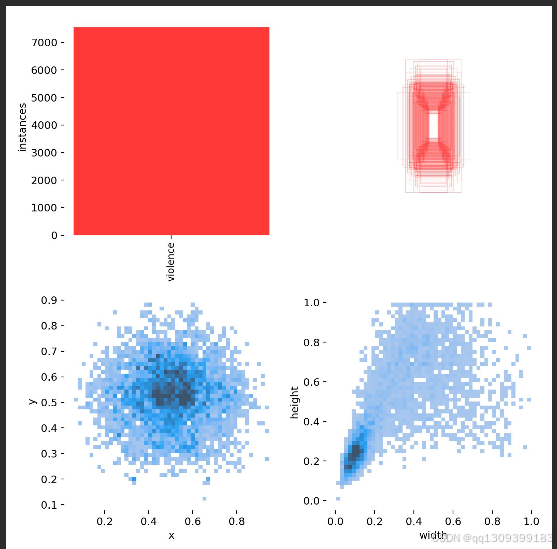
3.3.1 数据集准备
我们收集并标注了包含多种暴力行为的视频数据集,总计约10,000张图像。数据集涵盖了不同场景(如街道、商场、学校等)、不同光照条件和不同视角下的暴力行为。为增强模型泛化能力,我们对数据进行了以下增强处理:
- 随机水平翻转
- 色彩空间变换(亮度、饱和度、色调调整)
- 随机缩放裁剪
- Mosaic数据增强(将4张图像拼接为1张进行训练)
数据集按7:2:1的比例划分为训练集、验证集和测试集。
3.3.2 模型训练
训练过程采用以下关键参数:
- 初始学习率:0.01
- 优化器:SGD(动量0.937,权重衰减0.0005)
- Batch size:16(根据GPU显存调整)
- 训练轮次:300
- 学习率调度:余弦退火
为提升小目标检测能力,我们在损失函数中增加了对小目标的权重:
# 自定义损失函数权重
loss_weights = {
'box': 0.05, # 边界框损失
'obj': 1.0, # 目标性损失
'cls': 0.5, # 分类损失
'small_obj': 1.5 # 小目标额外权重
}

3.3.3 模型优化
针对暴力行为检测的特殊性,我们对YOLOv5s进行了以下优化:
- 注意力机制引入:在Backbone中嵌入CBAM(Convolutional Block Attention Module),增强模型对关键部位的关注能力
- 自适应锚框计算:根据暴力行为数据集重新聚类生成更适合的anchor boxes
- 多帧信息融合:引入轻量级LSTM模块处理时序信息,提升对连续性动作的识别能力
- 模型量化:采用PTQ(Post Training Quantization)将模型从FP32量化为INT8,减少模型大小并提升推理速度
四、系统实现与部署
4.1 开发环境
- 操作系统:Ubuntu 18.04 LTS
- 深度学习框架:PyTorch 1.8.0
- GPU:NVIDIA GTX 1080Ti (11GB显存)
- CUDA版本:11.1
- Python版本:3.8
4.2 关键代码实现
4.2.1 模型加载与推理
import torch
from models.experimental import attempt_load
# 加载预训练模型
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = attempt_load('yolov5s_violence.pt', map_location=device)
model.eval()
# 推理函数
def detect(frame):
# 预处理
img = preprocess(frame)
img = torch.from_numpy(img).to(device)
img = img.float() / 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# 推理
with torch.no_grad():
pred = model(img, augment=False)[0]
# 后处理
pred = non_max_suppression(pred, conf_thres=0.5, iou_thres=0.45)
return pred
4.2.2 多线程视频处理
为提高实时性,我们采用生产者-消费者模式实现多线程处理:
import threading
import queue
class VideoProcessor:
def __init__(self, video_source):
self.cap = cv2.VideoCapture(video_source)
self.frame_queue = queue.Queue(maxsize=30)
self.result_queue = queue.Queue(maxsize=30)
self.stop_event = threading.Event()
def capture_thread(self):
while not self.stop_event.is_set():
ret, frame = self.cap.read()
if not ret:
break
if not self.frame_queue.full():
self.frame_queue.put(frame)
def detection_thread(self):
while not self.stop_event.is_set():
if not self.frame_queue.empty():
frame = self.frame_queue.get()
result = detect(frame)
self.result_queue.put((frame, result))
def display_thread(self):
while not self.stop_event.is_set():
if not self.result_queue.empty():
frame, result = self.result_queue.get()
visualize(frame, result)
cv2.imshow('Violence Detection', frame)
if cv2.waitKey(1) == ord('q'):
self.stop_event.set()
def run(self):
threads = [
threading.Thread(target=self.capture_thread),
threading.Thread(target=self.detection_thread),
threading.Thread(target=self.display_thread)
]
for t in threads:
t.start()
for t in threads:
t.join()
self.cap.release()
cv2.destroyAllWindows()
4.3 部署方案
系统支持多种部署方式:
- 云端部署:将模型部署在云服务器上,通过RTSP协议接收监控视频流
- 边缘计算部署:使用NVIDIA Jetson系列开发板进行本地化部署
- 混合部署:在边缘设备进行初步检测,将可疑片段上传至云端进行二次分析
为优化边缘设备上的性能,我们采取了以下措施:
- 使用TensorRT加速推理
- 实现帧采样策略(如每3帧处理1帧)
- 动态调整推理分辨率(根据设备负载自动切换320×320或640×640)
五、性能评估与结果分析
5.1 评估指标
我们采用以下指标评估系统性能:
- 精度指标:Precision、Recall、mAP@0.5
- 速度指标:FPS(Frames Per Second)
- 资源消耗:GPU显存占用、CPU利用率
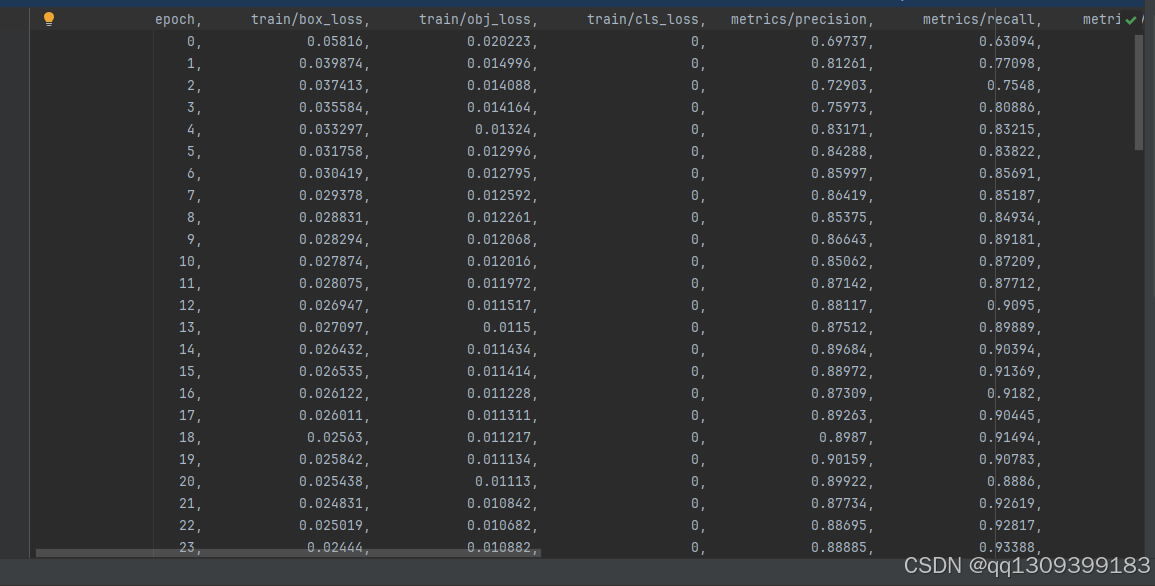
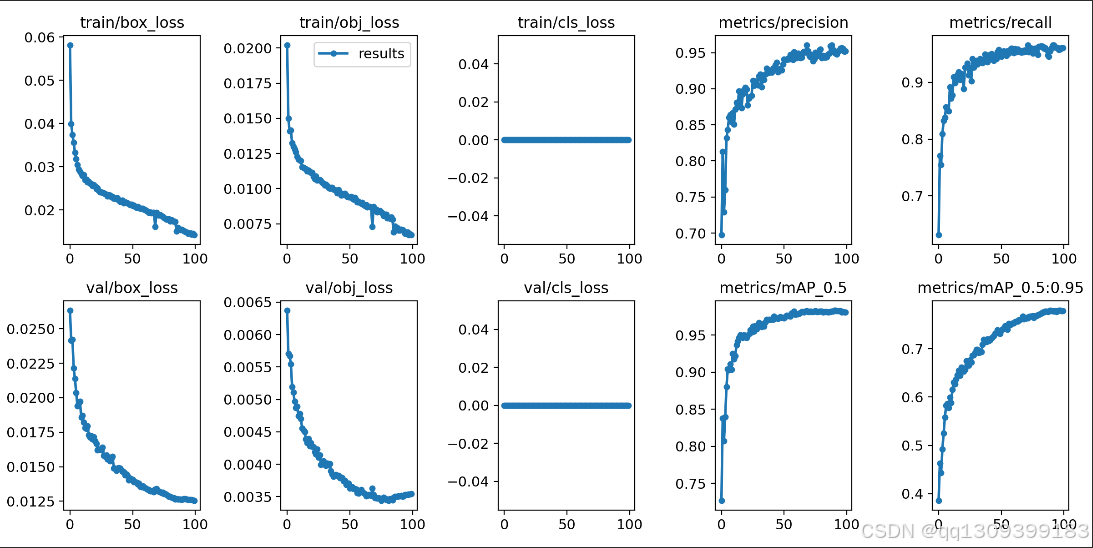
5.2 实验结果
在测试集上的评估结果如下:
| 模型版本 | mAP@0.5 | Precision | Recall | FPS |
|---|---|---|---|---|
| YOLOv5s基础版 | 0.782 | 0.812 | 0.743 | 68 |
| YOLOv5s优化版 | 0.821 | 0.845 | 0.792 | 62 |
| YOLOv5m | 0.834 | 0.852 | 0.803 | 45 |
优化后的YOLOv5s在保持较高推理速度的同时,精度接近更大的YOLOv5m模型。在Jetson Xavier NX上的性能测试显示,量化后的INT8模型可实现35FPS的实时处理速度,满足大多数监控场景的需求。
5.3 误报分析
通过分析误报案例,我们发现主要误报来源包括:
- 激烈的体育动作(如篮球对抗)
- 亲密行为(如拥抱)
- 快速行走或奔跑
为减少误报,我们在后处理阶段增加了以下规则:
- 持续时间阈值:仅当暴力行为持续超过2秒才触发报警
- 区域人数检测:单人动作不触发暴力报警
- 动作连续性检查:要求连续多帧检测到相似动作
六、应用前景与未来改进
基于YOLOv5s的暴力行为检测系统可广泛应用于:
- 公共场所智能监控(机场、车站、广场等)
- 校园安全监控
- 监狱管理
- 智能家居安全系统
未来改进方向包括:
- 多模态融合:结合声音分析(如喊叫声、打斗声)提升检测准确率
- 3D姿态估计:引入人体姿态信息更好区分暴力行为与正常动作
- 联邦学习:在不同监控点之间进行分布式模型训练,保护数据隐私
- 自适应学习:系统能够根据新数据持续优化模型,适应新型暴力行为
七、结论
本文提出的基于YOLOv5s的暴力行为检测系统,通过模型优化和工程实现,在精度和速度之间取得了良好平衡。实验结果表明,系统能够准确识别多种暴力行为,并实现实时处理。系统的轻量级特性使其适合部署在各种边缘设备上,为智能安防提供了一种有效的技术解决方案。未来随着算法的不断优化和硬件性能的提升,暴力行为检测技术将在公共安全领域发挥更加重要的作用。


















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









