







| paper | code | more |
|---|---|---|
| https://arxiv.org/abs/1807.05520 | https://github.com/facebookresearch/deepcluster | https://www.youtube.com/watch?v=n2_My2IfBM4 |
- 伪标签方法
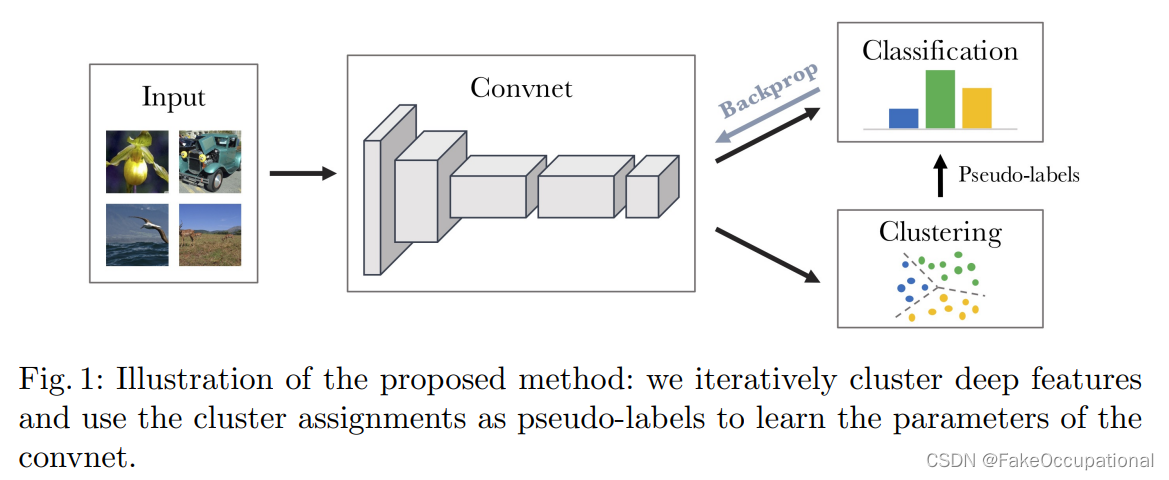
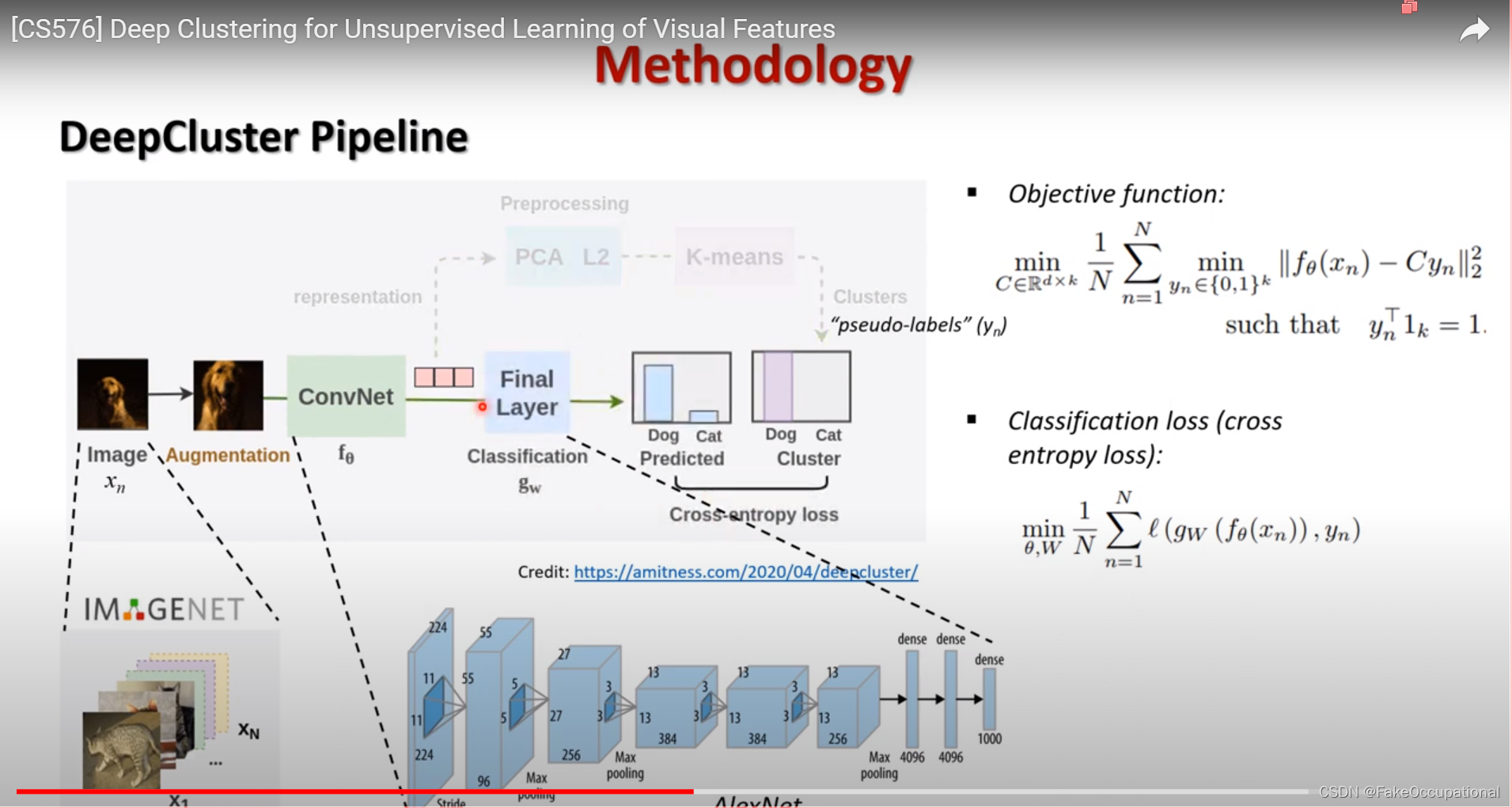
用于视觉特征无监督学习的深度聚类
-
聚类是一类无监督学习方法,在计算机视觉中得到了广泛的应用和研究。在使其适应大规模数据集上视觉特征的端到端训练方面,几乎没有做过什么工作。在这项工作中,我们介绍了DeepCluster,这是一种聚类方法,它共同学习神经网络的参数和结果特征的聚类分配。DeepCluster 使用标准聚类算法 k 均值对要素进行迭代分组,并使用后续赋值作为监督来更新网络的权重。我们将深度集群应用于在图像网和YFCC100M等大型数据集上卷积神经网络的无监督训练。由此产生的模型在所有标准基准上都以显着的优势优于当前技术水平。
-
本文为ECCV2018来自Facebook团队的作品,一次完整的训练需要在P100上训练12天,500 epochs,文中还提到,每个小批次包含256个图像。对于聚类,特征被PCA缩减到256维,白化和l2-归一化。我们使用Johnson等人[60]的k-means实现。请注意,运行k-means需要三分之一的时间,因为需要对整个数据集进行forward (Each mini-batch contains 256 images. For the clustering, features are PCA-reduced to 256 dimensions, whitened and `2-normalized. We use the k-means implementation of Johnson et al. [60]. Note that running k-means takes a third of the time because a forward pass on the full dataset is needed.)
kmeans相关
>>> from sklearn.cluster import KMeans
>>> import numpy as np
>>> X = np.array([[1, 2], [1, 4], [1, 0],
... [10, 2], [10, 4], [10, 0]])
>>> kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
>>> kmeans.labels_
array([1, 1, 1, 0, 0, 0], dtype=int32)
>>> kmeans.predict([[0, 0], [12, 3]])
array([1, 0], dtype=int32)
>>> kmeans.cluster_centers_
array([[10., 2.],
[ 1., 2.]])
- 算法原理 https://stanford.edu/~cpiech/cs221/handouts/kmeans.html
- 原理图示 https://www.javatpoint.com/k-means-clustering-algorithm-in-machine-learning
- https://jakevdp.github.io/PythonDataScienceHandbook/05.11-k-means.html
参考与更多
-
Deep k-Means: Re-Training and Parameter Sharing with Harder Cluster Assignments for Compressing Deep Convolutions这篇文章并非是深度聚类的:,这篇论文提出一种简单却高效的框架,该框架可以对权重进行k-means聚类进而可以对卷积进行压缩,压缩是通过权值共享得到的。该压缩过程只记录聚类中心和权重的下标。该论文还引入了一种新颖的基于谱放松的k-means约束,这样可以对难学的卷基层权重利用聚类中心来重新训练。















 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









