







- paper link https://arxiv.org/abs/2308.15366
- video demo https://youtu.be/lcxBfy0YnNA
- github https://github.com/CASIA-IVA-Lab/AnomalyGPT
- 在线使用 https://huggingface.co/spaces/FantasticGNU/AnomalyGPT
摘要
大型视觉语言模型(LVLM)如MiniGPT-4和LLaVA已经展示了理解图像的能力,并在各种视觉任务中取得了卓越的表现。尽管由于广泛的训练数据集,他们在识别常见对象方面的能力很强,但他们缺乏特定的领域知识,并且对对象内的局部细节的理解较弱,这阻碍了他们在工业异常检测 (IAD) 任务中的有效性。另一方面,大多数现有的IAD方法仅提供异常评分,并且需要手动设置阈值以区分正常和异常样本,这限制了其实际实施。在本文中,我们探讨了利用LVLM来解决IAD问题,并提出了AnomalyGPT,一种基于LVLM的新型IAD方法。我们通过模拟异常图像并为每个图像生成相应的文本描述来生成训练数据。我们还使用图像解码器来提供细粒度语义,并设计一个提示学习器来使用提示嵌入微调LVLM。我们的 AnomalyGPT 消除了手动阈值调整的需要,因此可以直接评估异常的存在和位置。此外,AnomalyGPT 支持多回合对话,并展示了令人印象深刻的少数镜头上下文学习功能。在 MVTec-AD 数据集上,AnomalyGPT 只需一次正常拍摄,就实现了 86.1% 的准确率、94.1% 的图像级 AUC 和 95.3% 的像素级 AUC 的先进性能。
贡献
• 我们介绍了LVLM在解决IAD任务方面的开创性应用。我们的方法不仅在不手动调整阈值的情况下检测和定位异常,而且支持多轮对话。据我们所知,我们是第一个将LVLM成功应用于工业异常检测领域的公司。
• 我们工作中的轻量级、基于视觉文本特征匹配的解码器解决了LLM对细粒度语义识别能力较弱的限制,并缓解了LLM仅生成文本输出能力受限的限制。
• 我们采用即时嵌入进行微调,并与LVLM预训练期间使用的数据同时训练我们的模型,从而保留LVLM的固有能力并实现多回合对话。
• 我们的方法保持了强大的可转移性,能够在新的数据集上进行上下文少镜头学习,产生出色的性能。
3. Method
AnomalyGPT是一种新颖的会话式IAD视觉语言模型,主要用于检测工业工件图像中的异常并精确定位其位置。我们利用预先训练的图像编码器和LLM,通过模拟的异常数据来对齐IAD图像及其相应的文本描述。我们引入了解码器模块和提示学习器模块,以提高IAD性能并实现像素级定位输出。利用预训练数据进行及时调整和交替训练可以保持LLM的可转移性,并防止灾难性遗忘。我们的方法表现出强大的少镜头转移能力,能够在只提供一个正常样本的情况下对以前看不见的项目进行异常检测和定位。
3.1. Model architecture
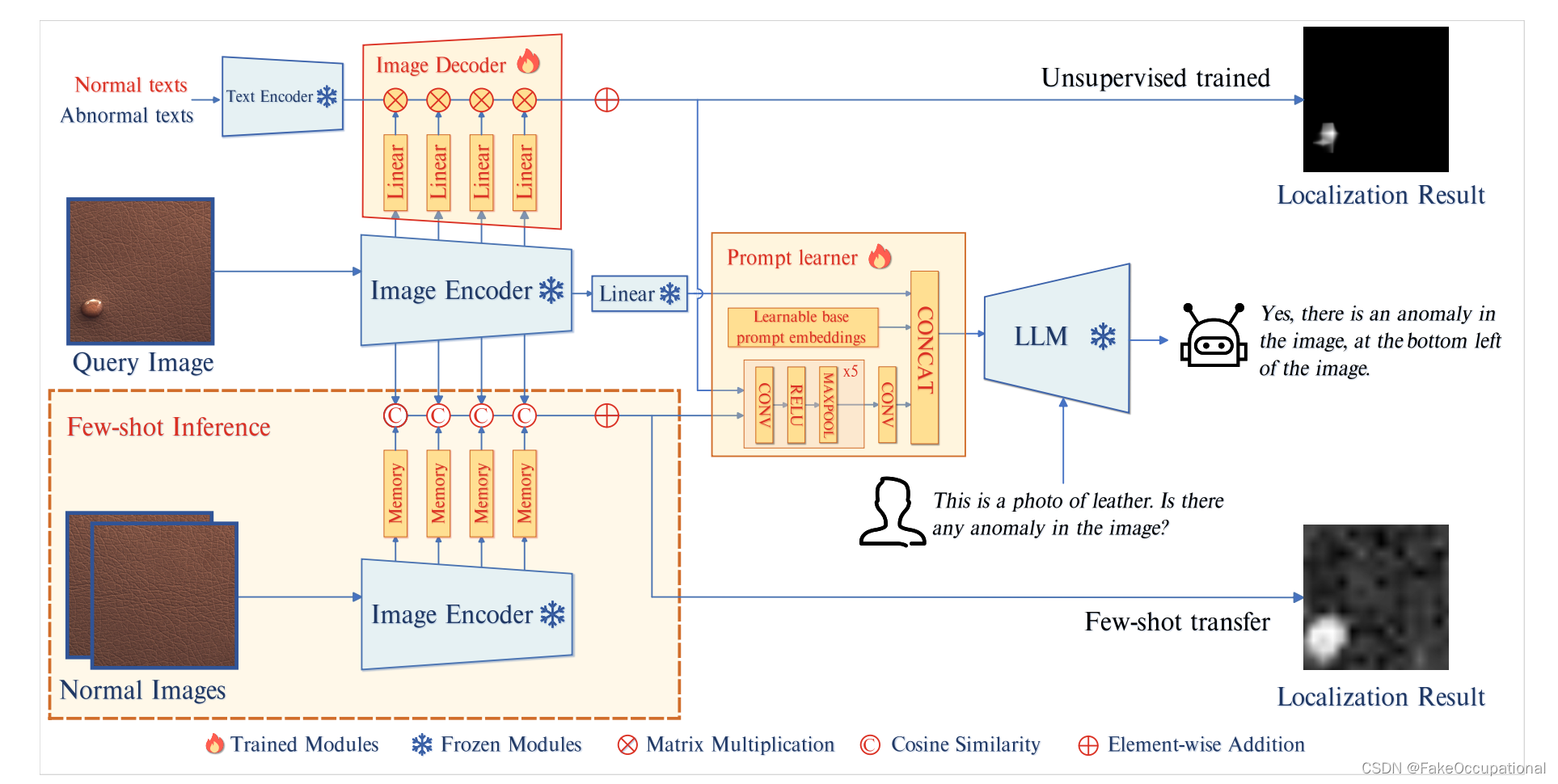
图2展示了AnomalyGPT的综合架构。给定一个查询图像 x ∈ R H × W × C x∈R^{H×W×C} x∈RH×W×C,将图像编码器提取的最终特征 F i m g ∈ R C 1 F_{img}∈R^{C1} Fimg∈RC1通过线性层,得到嵌入 E i m g ∈ R C e m b E_{img}∈R^{Cemb} Eimg∈RCemb的图像,然后将其输入LLM。在无监督设置中,将图像编码器中间层提取的patch特征与文本特征一起输入解码器,以生成像素级异常定位结果。在few-shot设置中,来自正常样本的patch级别特征被存储在存储库(memory bank)中,并且可以通过计算查询patch与存储库中最相似的部件之间的距离来获得定位结果。定位结果随后通过提示学习器转换为提示嵌入,作为LLM输入的一部分。LLM利用图像输入、提示嵌入和用户提供的文本输入来检测异常并识别其位置
3.2. Decoder and prompt learner
Decoder
为了实现像素级异常定位,我们采用了一种基于特征匹配的轻量级图像解码器,该解码器支持无监督IAD和少镜头IAD。解码器的设计主要受到PatchCore[23]、WinCLIP[11]和APRIL-GAN[2]的启发。
如图2的上部所示,我们将图像编码器划分为4个阶段,并获得每个阶段提取的中间patch级别特征
F
p
a
t
c
h
i
∈
R
H
I
×
W
i
×
C
i
F_{patch}^i\in R^{H_I\times W_i \times C_i}
Fpatchi∈RHI×Wi×Ci,其中i表示第i阶段。遵循WinCLIP[11]的理念,一种自然的方法是分别计算
F
p
a
t
c
h
i
F_{patch}^i
Fpatchi和文本特征
F
t
e
x
t
∈
R
2
×
C
t
e
x
t
F_{text}\in R^{2\times C_{text}}
Ftext∈R2×Ctext(正常和异常)之间的相似性。表示正常和异常情况的详细文本见附录B。
表示正常和异常情况的详细文本如附录B所示。然而,由于这些中间特征尚未经过最终的图像-文本对齐,因此无法直接与文本特征进行比较。为了解决这个问题,我们引入了附加的线性层来将这些中间特征投影到
F
~
p
a
t
c
h
i
∈
R
H
i
×
W
i
×
C
t
e
x
t
\tilde F^i_{patch}∈R^{H_i×W_i×C_{text}}
F~patchi∈RHi×Wi×Ctext,并将它们与表示正常和异常语义的文本特征对齐。定位结果
M
∈
R
H
×
W
M∈R^{H×W}
M∈RH×W可以由方程(1)得到:

对于少镜头IAD,如图2的下半部分所示,我们使用相同的图像编码器从正常样本中提取中间补丁级别的特征,并将其存储在存储库memory-bank
B
i
∈
R
N
×
C
i
B_i∈R^{N×Ci}
Bi∈RN×Ci中,其中i表示第i阶段。对于补丁级别的特征
F
p
a
t
c
h
i
∈
R
H
i
×
W
i
×
C
i
F^i_{patch}∈R^{ H_i×W_i×C_i}
Fpatchi∈RHi×Wi×Ci,我们计算了每个补丁与内存库中最相似的补丁之间的距离,并且定位结果
M
∈
R
H
×
W
M∈R^{H×W}
M∈RH×W可以通过等式(2)获得。
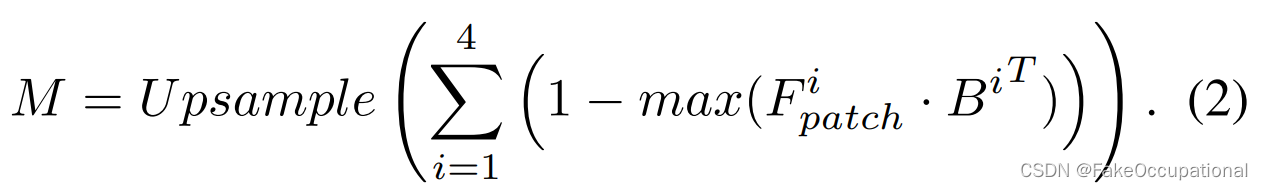
Prompt learner
为了利用图像中的细粒度语义并保持LLM和解码器输出之间的语义一致性,我们引入了一种将定位结果转换为提示嵌入的提示学习器。此外,与解码器输出无关的可学习的基本提示嵌入被结合到提示学习器中,以为IAD任务提供额外信息。最后,这些嵌入与原始图像信息一起被馈送到LLM中。
如图2所示,提示学习器由可学习的基本提示嵌入 E b a s e ∈ R n 1 × C e m b E_{base}∈R^{n1×Cemb} Ebase∈Rn1×Cemb和卷积神经网络组成。该网络将定位结果 M ∈ R H × W M∈R^{H×W} M∈RH×W转换为 n 2 n_2 n2个提示嵌入 E d e c ∈ R n 2 × C e m b E_{dec}∈R^{n2×C_{emb}} Edec∈Rn2×Cemb。 E b a s e E_{base} Ebase和 E d e c E_{dec} Edec形成一组 n 1 + n 2 n_1+n_2 n1+n2提示嵌入 E p r o m p t ∈ R ( n 1 + n 2 ) × C e m b E_{prompt}∈R^{(n1+n2)×C_{emb}} Eprompt∈R(n1+n2)×Cemb,其与嵌入到LLM中的图像相组合。
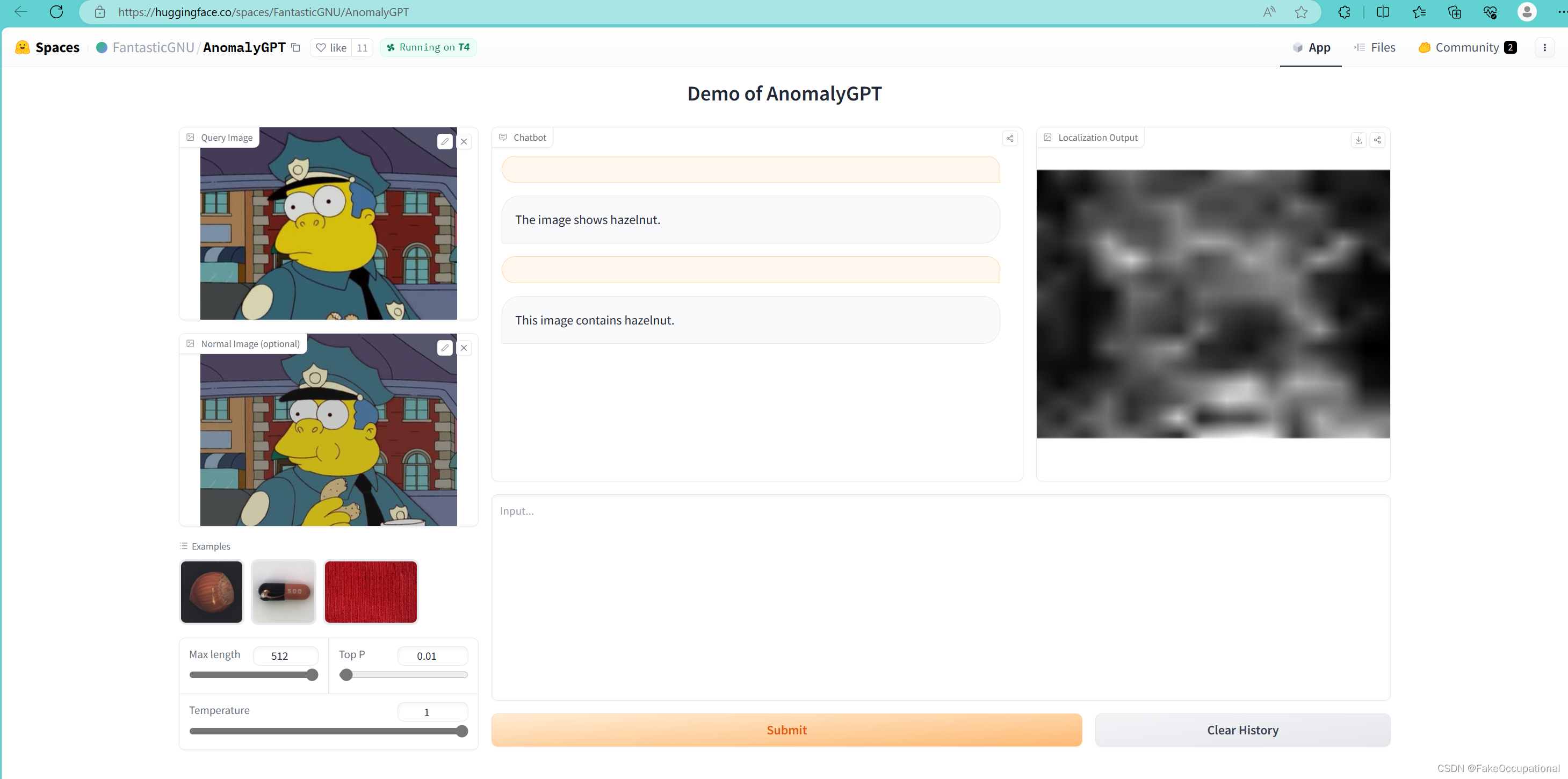
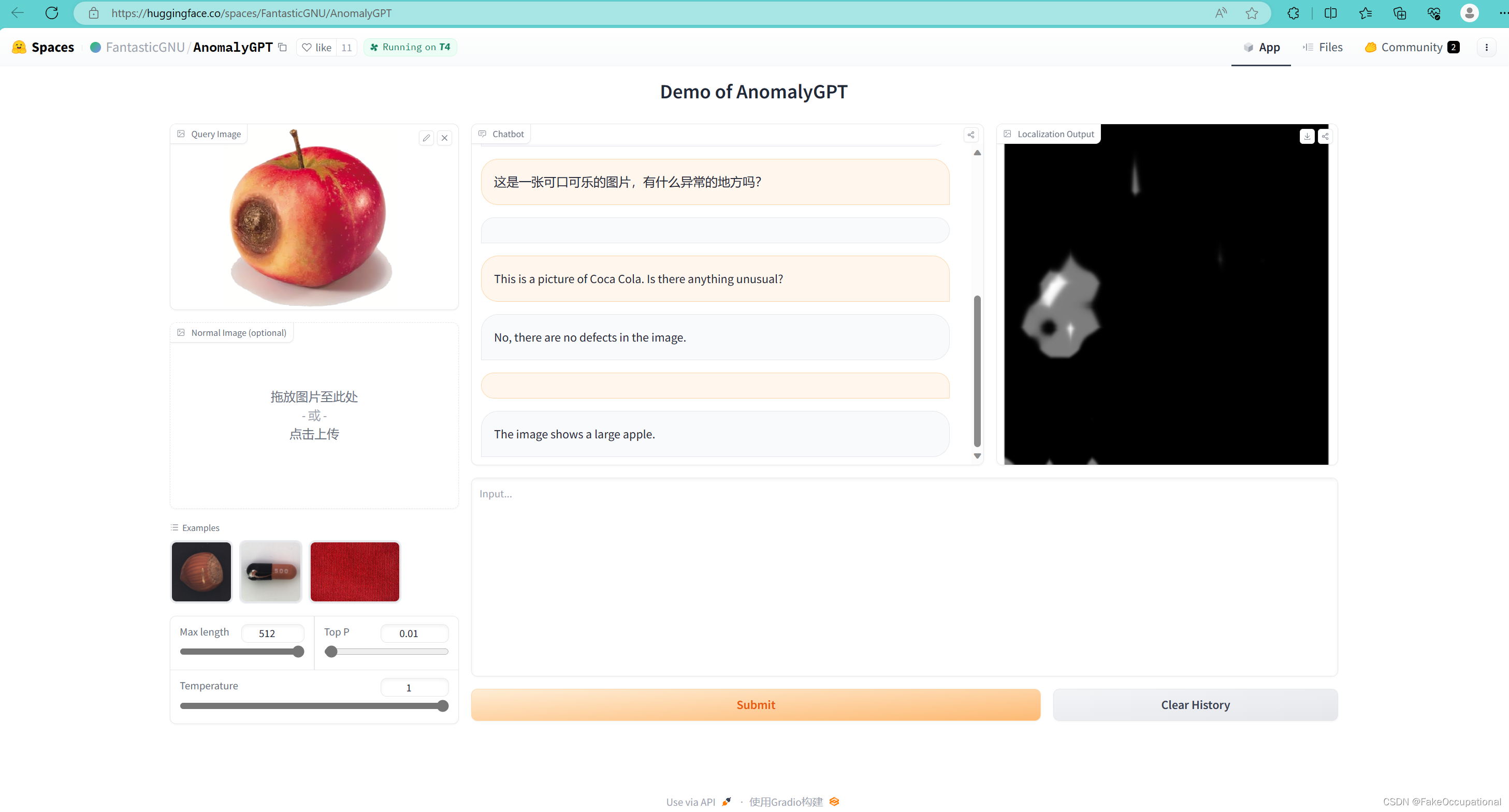
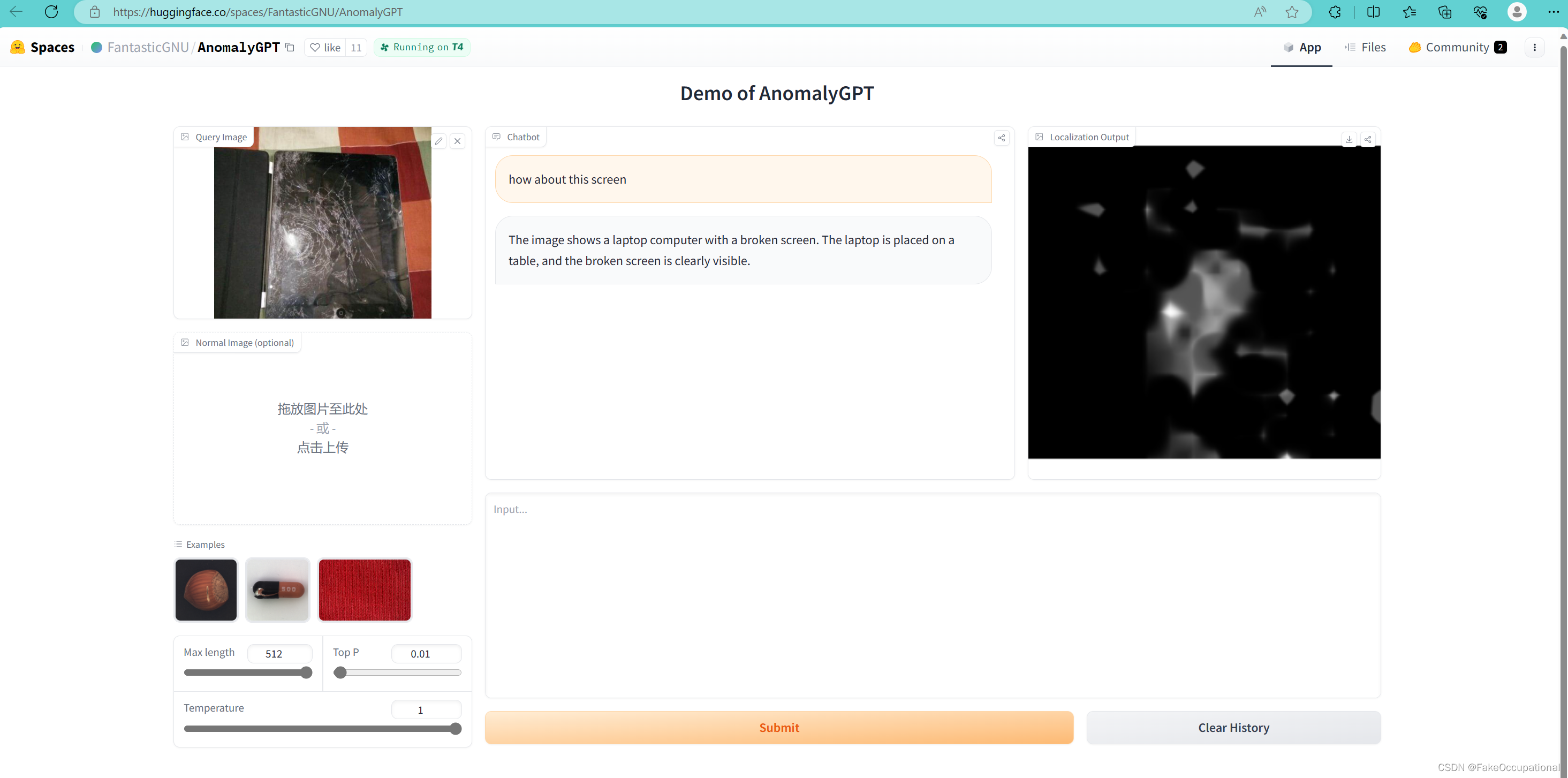
试用截图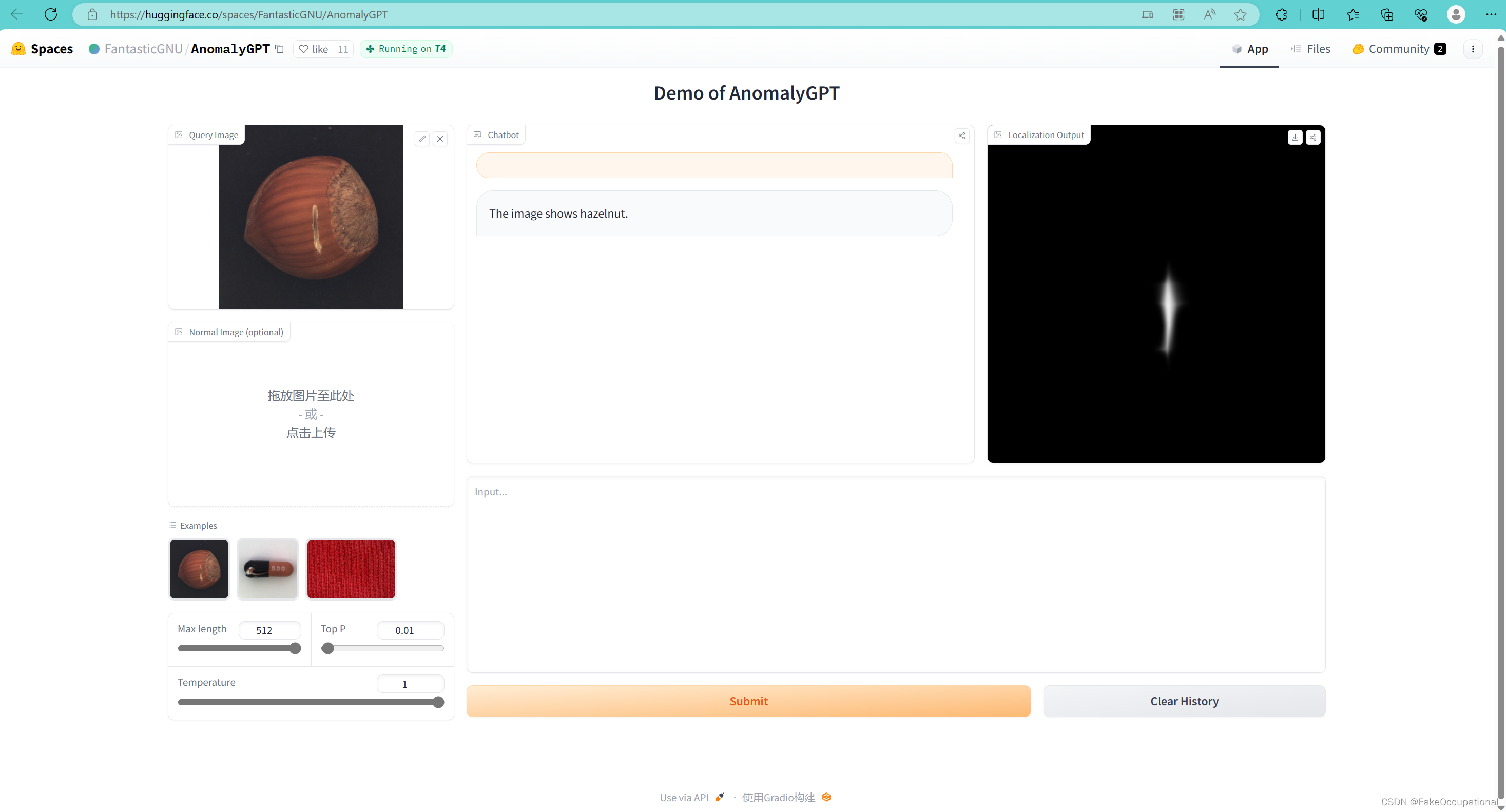















 1272
1272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









