






代码:https://github.com/Whiffe/Bert-OCNLI/tree/main/Bert-OCNLI-yf
b站:https://www.bilibili.com/video/BV1BU411o7pN/
0 资料
【数据集微调】
阿里天池比赛 微调BERT的数据集(“任务1:OCNLI–中文原版自然语言推理”)
请参照下面的信息,下载数据集、提交榜单测试。
-
“任务1:OCNLI–中文原版自然语言推理”数据集的GitHub地址:https://github.com/CLUEbenchmark/OCNLI
-
榜单提交步骤:
- 打开“榜单提交地址”,点击“立即测评”——填写相关信息(github地址填https://github.com/CLUEbenchmark/CLUE,其他信息任意填)。
- 上传一个.zip压缩文件,在压缩文件里存放我们模型预测结果的文件。
- 点击提交。
-
【注意】预测结果文件的格式:https://storage.googleapis.com/cluebenchmark/tasks/clue_submit_examples.zip
1 榜单提交
https://www.cluebenchmarks.com/index.html

需要对结果进行一些处理才能提交
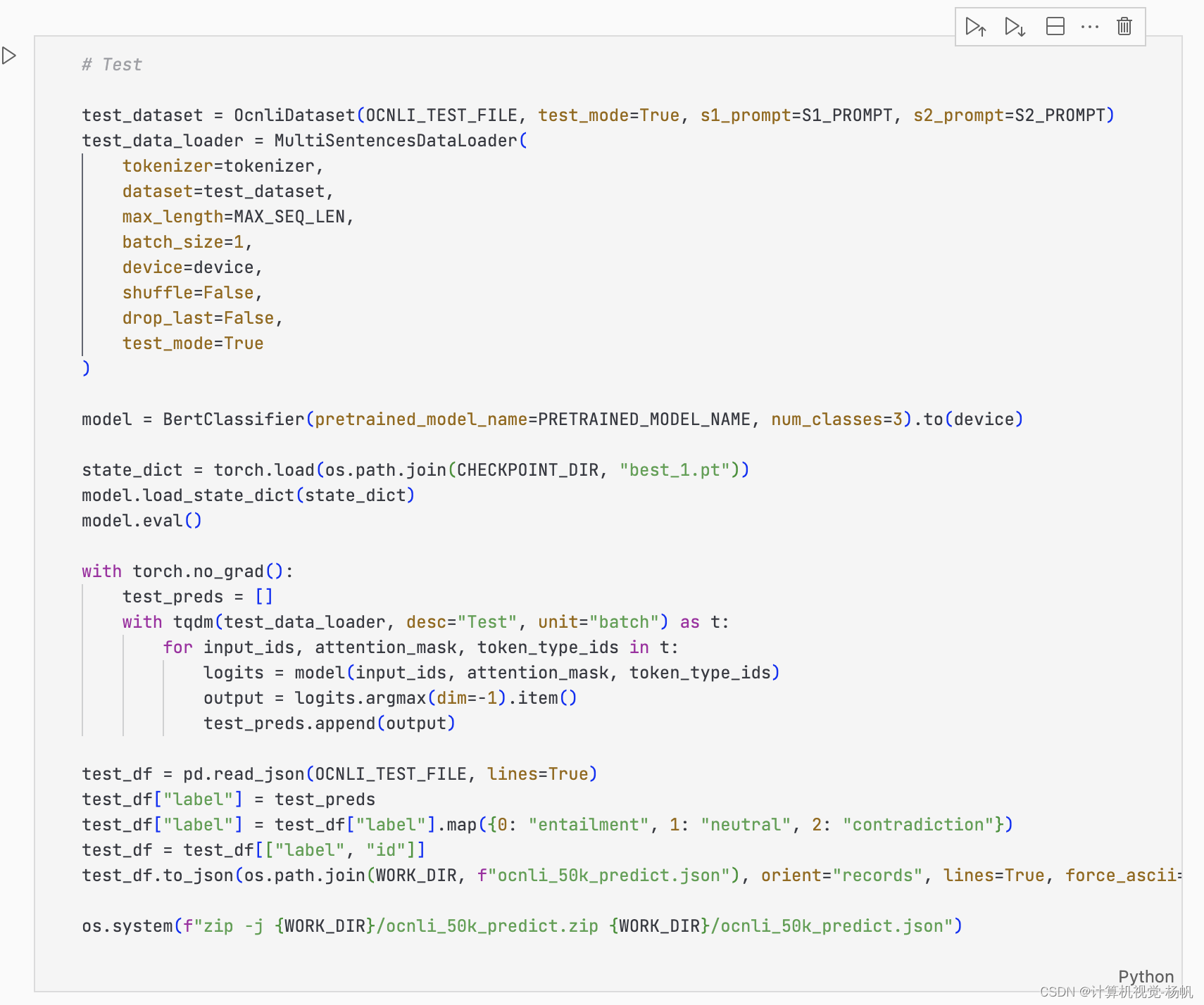
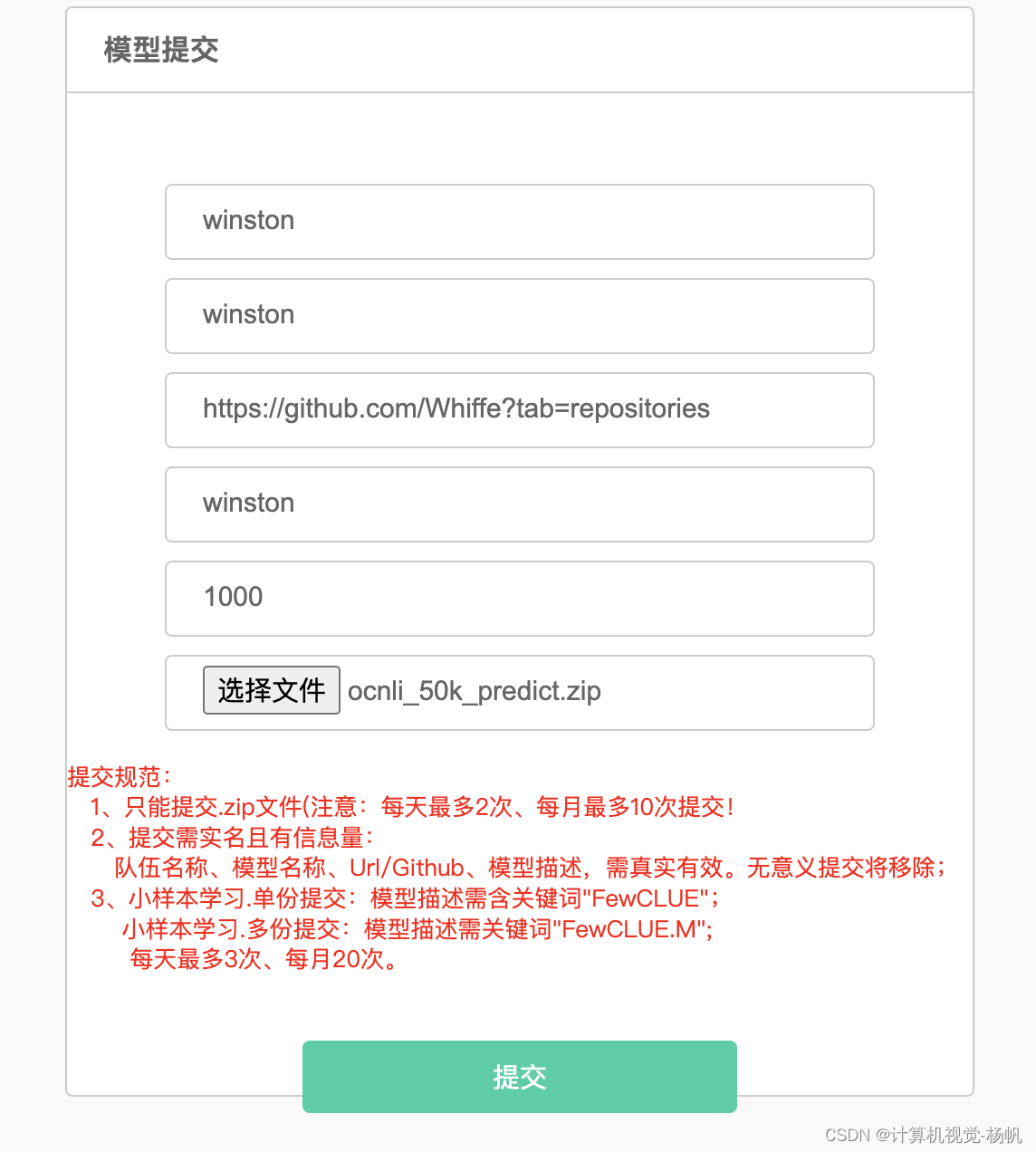
提交结果:
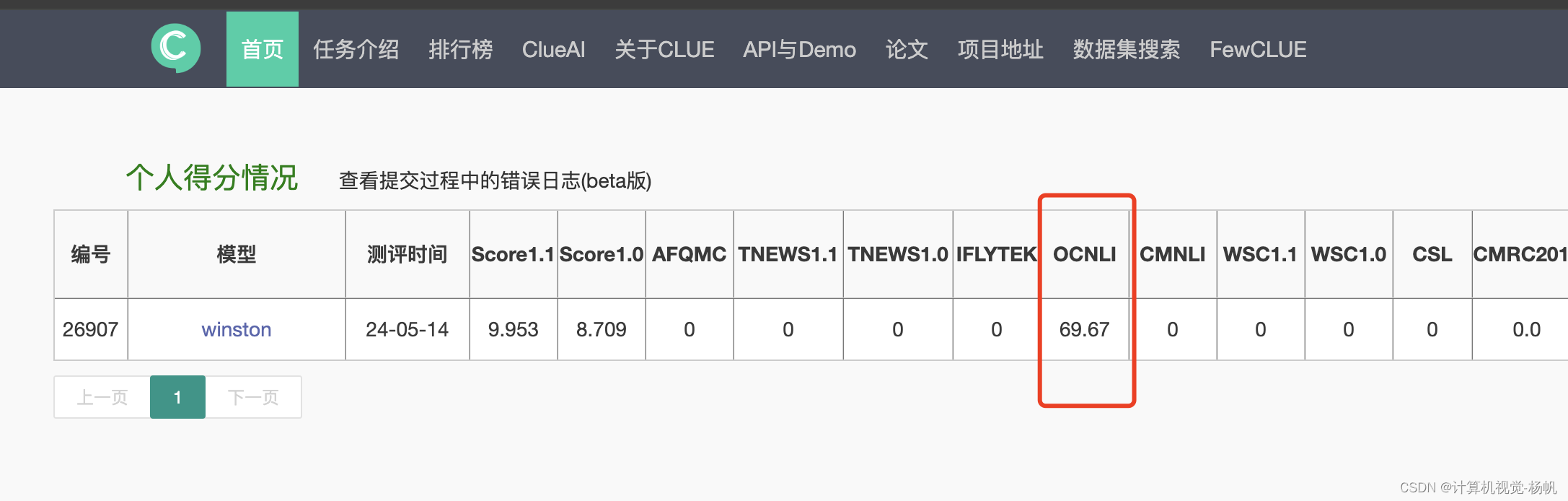
2 wandb
2.1 wandb介绍
Weights & Biases (wandb) 是一个用于机器学习实验管理和跟踪的平台。它帮助研究人员和工程师记录、比较和分享实验的结果和参数。以下是 wandb 的主要功能和特点:
-
实验跟踪:
- 记录训练过程中的各种指标(如损失、准确率)。
- 跟踪模型的超参数和配置。
- 支持可视化训练曲线和其他统计数据。
-
可视化:
- 提供丰富的图表和仪表板,用于可视化训练过程。
- 支持嵌入式媒体(如图像、音频)的展示。
-
模型管理:
- 保存和版本化模型检查点。
- 比较不同模型版本的性能。
-
协作:
- 支持团队协作,可以轻松分享实验结果和配置。
- 提供项目和工作空间,用于组织和管理多个实验。
-
集成:
- 与各种机器学习框架(如 TensorFlow、PyTorch、Keras)无缝集成。
- 支持与云存储服务(如 AWS、GCP)集成,便于保存和加载数据。
-
在线和离线模式:
- 支持在线模式,实时上传和共享实验数据。
- 支持离线模式,数据存储在本地,适用于网络不稳定或需要本地存储的情况。
以下是一个简单的 wandb 使用示例:
import wandb
# 初始化一个新的 wandb 运行
wandb.init(project="my_project", name="experiment_1")
# 配置你的模型和数据
# 记录超参数
wandb.config.learning_rate = 0.01
wandb.config.batch_size = 32
# 在训练过程中记录指标
for epoch in range(10):
# 模拟训练和验证过程
train_loss = 0.01 * epoch
val_accuracy = 0.8 + 0.01 * epoch
# 记录指标到 wandb
wandb.log({"train_loss": train_loss, "val_accuracy": val_accuracy})
# 保存模型
model_path = "model.pth"
torch.save(model.state_dict(), model_path)
wandb.save(model_path)
通过这种方式,wandb 可以帮助你更好地管理和分析机器学习实验,提高工作效率和协作能力。
2.2 wandb.init()
在 wandb.init() 函数中,有多个参数可以配置,用于初始化 Weights & Biases (wandb) 运行。以下是你提到的参数及其详细解释:
-
project:
- 类型:字符串
- 说明:指定项目的名称。所有属于同一项目的实验会被组织在一起,方便管理和比较。例如,
project="my_project"表示将当前运行记录到名为 “my_project” 的项目中。如果该项目不存在,会自动创建一个新的项目。
-
entity(被注释掉的部分):
- 类型:字符串
- 说明:指定团队或用户的名称。对于个人用户,这个值通常是你的用户名;对于团队或组织,这个值是团队的名称。它决定了项目在哪个账户下进行管理。例如,
entity="my_team"表示将当前运行记录到 “my_team” 团队下的项目中。这个参数在你的代码中被注释掉了,意味着当前运行会记录到默认的账户中。
-
name:
- 类型:字符串
- 说明:指定当前运行的名称。它有助于区分不同的实验运行。例如,
name="experiment_1"表示将当前运行命名为 “experiment_1”。这个名称在界面上会显示,便于识别和管理多个运行。
-
mode:
- 类型:字符串
- 说明:指定 wandb 的运行模式。常用的模式有以下几种:
"online":默认模式,实时将数据上传到 wandb 的服务器。"offline":本地记录数据,不上传到服务器。你可以稍后使用wandb sync命令将数据上传。"disabled":禁用 wandb,运行过程中不会记录任何数据或日志。这对于调试或快速测试代码时非常有用。例如,mode="disabled"表示当前运行不会记录任何数据到 wandb。
示例代码:
import wandb
# 配置 wandb 运行
wandb.init(
project="my_project", # 项目名称
# entity="my_team", # 团队或用户名称(被注释掉)
name="experiment_1", # 运行名称
mode="disabled" # 运行模式
)
# 其余代码,例如模型训练、记录指标等
通过这种方式,你可以灵活地配置 wandb,满足不同的实验管理需求。
2.3 wandb.config
这段代码用于将配置参数保存到 Weights & Biases (wandb) 的配置对象 wandb.config 中。这有助于记录实验的超参数和其他配置,以便在 wandb 仪表板上查看和分析。详细解释如下:
-
wandb_config = wandb.config:
- 说明:
wandb.config是一个字典样式的对象,用于存储当前运行的配置信息。通过将wandb.config赋值给wandb_config,可以方便地将各种配置参数添加到这个对象中。
- 说明:
-
wandb_config.model_name = configs.model_name:
- 说明:将模型的名称保存到 wandb 配置中。例如,如果
configs.model_name是"bert-base-chinese",则该行代码会将model_name设置为"bert-base-chinese"。
- 说明:将模型的名称保存到 wandb 配置中。例如,如果
-
wandb_config.num_classes = configs.num_classes:
- 说明:将分类任务的类别数保存到 wandb 配置中。例如,如果
configs.num_classes是3,则该行代码会将num_classes设置为3。
- 说明:将分类任务的类别数保存到 wandb 配置中。例如,如果
-
wandb_config.dropout = configs.dropout:
- 说明:将 dropout 概率保存到 wandb 配置中。这是模型中的一个超参数,用于防止过拟合。例如,如果
configs.dropout是0.1,则该行代码会将dropout设置为0.1。
- 说明:将 dropout 概率保存到 wandb 配置中。这是模型中的一个超参数,用于防止过拟合。例如,如果
-
wandb_config.freeze_pooler = configs.freeze_pooler:
- 说明:将是否冻结池化层的设置保存到 wandb 配置中。这通常是一个布尔值,用于指示是否在训练过程中冻结模型的池化层。例如,如果
configs.freeze_pooler是True,则该行代码会将freeze_pooler设置为True。
- 说明:将是否冻结池化层的设置保存到 wandb 配置中。这通常是一个布尔值,用于指示是否在训练过程中冻结模型的池化层。例如,如果
-
wandb_config.batch_size = configs.batch_size:
- 说明:将训练过程中使用的批次大小保存到 wandb 配置中。例如,如果
configs.batch_size是32,则该行代码会将batch_size设置为32。
- 说明:将训练过程中使用的批次大小保存到 wandb 配置中。例如,如果
-
wandb_config.max_length = configs.max_length:
- 说明:将输入序列的最大长度保存到 wandb 配置中。例如,如果
configs.max_length是128,则该行代码会将max_length设置为128。
- 说明:将输入序列的最大长度保存到 wandb 配置中。例如,如果
-
wandb_config.lr = configs.lr:
- 说明:将学习率保存到 wandb 配置中。这是一个重要的超参数,控制模型的学习速度。例如,如果
configs.lr是1e-5,则该行代码会将lr设置为1e-5。
- 说明:将学习率保存到 wandb 配置中。这是一个重要的超参数,控制模型的学习速度。例如,如果
-
wandb_config.epochs = configs.epochs:
- 说明:将训练的轮数保存到 wandb 配置中。例如,如果
configs.epochs是10,则该行代码会将epochs设置为10。
- 说明:将训练的轮数保存到 wandb 配置中。例如,如果
-
wandb_config.device = configs.device:
- 说明:将训练所用设备保存到 wandb 配置中。例如,如果
configs.device是"cuda",则该行代码会将device设置为"cuda"。
- 说明:将训练所用设备保存到 wandb 配置中。例如,如果
-
wandb_config.seed = configs.seed:
- 说明:将随机种子保存到 wandb 配置中。这有助于确保实验的可重复性。例如,如果
configs.seed是42,则该行代码会将seed设置为42。
- 说明:将随机种子保存到 wandb 配置中。这有助于确保实验的可重复性。例如,如果
通过将这些参数保存到 wandb.config 中,实验的所有配置信息都能在 wandb 仪表板上方便地查看和分析。这对于调试、优化模型和复现实验结果非常有用。
2.4 wandb.watch
wandb.watch 是 Weights & Biases (W&B) 库中的一个函数,用于监控 PyTorch 模型的训练过程。它可以记录和可视化模型的权重、梯度,以及随时间变化的训练过程数据。这样可以帮助你深入了解模型的训练行为,检测和诊断潜在问题。以下是 wandb.watch 的详细讲解:
函数签名
wandb.watch(models, criterion=None, log="gradients", log_freq=1000, idx=None, log_graph=False)
参数解释
-
models:- 需要监控的模型或模型的列表。通常是一个 PyTorch 模型(
nn.Module)。
- 需要监控的模型或模型的列表。通常是一个 PyTorch 模型(
-
criterion:- 可选参数。指定要监控的损失函数。可以是一个 PyTorch 损失函数(例如
nn.CrossEntropyLoss)。如果提供了这个参数,W&B 会记录损失函数的值。
- 可选参数。指定要监控的损失函数。可以是一个 PyTorch 损失函数(例如
-
log:- 指定要记录的内容。可以是以下值之一:
"gradients": 仅记录梯度。"parameters": 仅记录参数。"all": 同时记录梯度和参数。
- 默认值为
"gradients"。
- 指定要记录的内容。可以是以下值之一:
-
log_freq:- 指定记录频率。表示每隔多少步记录一次模型的梯度和/或参数。默认值为
1000。
- 指定记录频率。表示每隔多少步记录一次模型的梯度和/或参数。默认值为
-
idx:- 可选参数。如果监控多个模型,可以使用这个参数指定要监控的模型索引。
-
log_graph:- 布尔值,表示是否记录计算图。默认值为
False。
- 布尔值,表示是否记录计算图。默认值为
使用示例
假设你有一个训练函数 train,你可以在训练开始前调用 wandb.watch 来监控模型。下面是一个完整的示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import wandb
# 假设我们有一个简单的模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 50)
self.fc2 = nn.Linear(50, 3)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 假设我们有一个简单的数据集
class SimpleDataset(Dataset):
def __init__(self):
self.data = torch.randn(100, 10)
self.labels = torch.randint(0, 3, (100,))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
def train(model, train_loader, criterion, optimizer, num_epochs):
# 初始化 Weights & Biases
wandb.init(project="simple-project", name="simple-experiment")
# 监控模型
wandb.watch(model, log="all")
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / len(train_loader)
print(f"Epoch {epoch+1}, Loss: {avg_loss}")
wandb.log({"loss": avg_loss})
# 创建模型、数据集和 DataLoader
model = SimpleModel()
dataset = SimpleDataset()
train_loader = DataLoader(dataset, batch_size=32, shuffle=True)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
train(model, train_loader, criterion, optimizer, num_epochs=5)
代码解释
-
初始化 W&B:
wandb.init(project="simple-project", name="simple-experiment")- 初始化 W&B 项目和实验,设置项目名称和实验名称。
-
监控模型:
wandb.watch(model, log="all")- 调用
wandb.watch监控模型,记录模型的所有内容(梯度和参数)。
- 调用
-
记录损失:
wandb.log({"loss": avg_loss})- 在每个 epoch 结束时记录平均损失到 W&B。
总结
使用 wandb.watch 可以帮助你在训练过程中实时监控和记录模型的权重、梯度和其他相关数据。这些数据会被记录到 Weights & Biases 平台上,你可以通过其提供的可视化工具更好地理解和分析模型的训练过程。通常,你会在模型定义和优化器定义之后,在训练循环之前调用 wandb.watch。
2.5 wandb.log
wandb.log 是 Weights & Biases (W&B) 中用于记录任意指标和数据的函数。它将这些数据记录到 W&B 仪表板中,以便实时监控训练过程,查看历史数据,并进行分析和可视化。详细解释如下:
函数签名
wandb.log(data, step=None, commit=True)
参数解释
-
data:- 一个字典,其中键是你要记录的指标名称,值是对应的数值。每次调用
wandb.log都会将这些数据发送到 W&B 仪表板并记录下来。
- 一个字典,其中键是你要记录的指标名称,值是对应的数值。每次调用
-
step:- 可选参数,指定当前记录的步数(通常是迭代次数或 epoch)。如果不提供,W&B 会自动递增步数。
-
commit:- 布尔值,表示是否将这一记录视为一个事务(即,提交这一记录)。默认值为
True。如果设置为False,你可以在稍后进行一次批量提交。
- 布尔值,表示是否将这一记录视为一个事务(即,提交这一记录)。默认值为
使用示例
在训练模型的过程中,我们通常会在每次计算完损失和其他指标后调用 wandb.log 来记录这些数据。以下是一个示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import wandb
# 假设我们有一个简单的模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 50)
self.fc2 = nn.Linear(50, 3)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 假设我们有一个简单的数据集
class SimpleDataset(Dataset):
def __init__(self):
self.data = torch.randn(100, 10)
self.labels = torch.randint(0, 3, (100,))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
def train(model, train_loader, criterion, optimizer, num_epochs):
# 初始化 Weights & Biases
wandb.init(project="simple-project", name="simple-experiment")
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 计算准确率
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
avg_loss = running_loss / len(train_loader)
accuracy = correct / total
print(f"Epoch {epoch+1}, Loss: {avg_loss}, Accuracy: {accuracy}")
# 记录损失和准确率到 Weights & Biases
wandb.log({
'loss': avg_loss,
'accuracy': accuracy
})
# 创建模型、数据集和 DataLoader
model = SimpleModel()
dataset = SimpleDataset()
train_loader = DataLoader(dataset, batch_size=32, shuffle=True)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
train(model, train_loader, criterion, optimizer, num_epochs=5)
代码解释
-
初始化 Weights & Biases:
wandb.init(project="simple-project", name="simple-experiment")- 初始化 W&B 项目和实验,设置项目名称和实验名称。
-
计算并记录指标:
在每个 epoch 结束时计算平均损失和准确率,并使用wandb.log记录这些指标:avg_loss = running_loss / len(train_loader) accuracy = correct / total print(f"Epoch {epoch+1}, Loss: {avg_loss}, Accuracy: {accuracy}") # 记录损失和准确率到 Weights & Biases wandb.log({ 'loss': avg_loss, 'accuracy': accuracy })wandb.log中的数据字典包含两个键值对:'loss': 对应当前 epoch 的平均损失。'accuracy': 对应当前 epoch 的准确率。
-
参数
commit:- 默认情况下,
wandb.log会自动提交这一记录。你可以将多个wandb.log调用的commit参数设置为False,然后在最后一个调用中设置为True进行批量提交。
- 默认情况下,
总结
使用 wandb.log 可以方便地将训练过程中产生的各种指标记录到 Weights & Biases 平台。这样做的好处是:
- 实时监控训练进展。
- 生成可视化图表,方便分析和调试。
- 保持训练日志,便于回溯和复现实验结果。
通过这种方式,你可以更好地理解和优化模型的训练过程。
2.6 wandb.save
wandb.save 是 Weights & Biases (W&B) 中用于保存文件的函数,它可以将本地文件保存到 W&B 的云存储中,以便进行版本控制和共享。详细解释如下:
函数签名
wandb.save(glob_str, base_path=None, policy='live')
参数解释
-
glob_str:- 字符串,表示要保存的文件或文件模式。可以使用通配符(如
*.pt)来匹配多个文件。例如,"checkpoint.pth"或"checkpoints/*.pt"。
- 字符串,表示要保存的文件或文件模式。可以使用通配符(如
-
base_path:- 可选参数,表示文件的基础目录。默认情况下,W&B 会使用当前工作目录。
-
policy:- 字符串,指定文件保存策略。选项包括:
'live':默认选项,表示保存文件的当前版本,并在文件更新时自动更新到云存储中。'end':表示在训练结束时保存文件的最终版本。'now':立即保存文件,不管文件是否在训练结束时更新。
- 字符串,指定文件保存策略。选项包括:
使用示例
在训练过程中,我们通常会保存模型的检查点文件。为了确保这些文件在训练结束后可以被回溯和分析,我们可以使用 wandb.save 将它们保存到 W&B 的云存储中。以下是一个示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import wandb
import os
# 假设我们有一个简单的模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(10, 50)
self.fc2 = nn.Linear(50, 3)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 假设我们有一个简单的数据集
class SimpleDataset(Dataset):
def __init__(self):
self.data = torch.randn(100, 10)
self.labels = torch.randint(0, 3, (100,))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
def train(model, train_loader, criterion, optimizer, num_epochs, checkpoint_dir):
# 初始化 Weights & Biases
wandb.init(project="simple-project", name="simple-experiment")
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 计算准确率
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
avg_loss = running_loss / len(train_loader)
accuracy = correct / total
print(f"Epoch {epoch+1}, Loss: {avg_loss}, Accuracy: {accuracy}")
# 记录损失和准确率到 Weights & Biases
wandb.log({
'loss': avg_loss,
'accuracy': accuracy
})
# 保存模型检查点
checkpoint_path = os.path.join(checkpoint_dir, f"checkpoint_epoch_{epoch+1}.pth")
torch.save(model.state_dict(), checkpoint_path)
# 使用 wandb.save 将检查点文件保存到 W&B 云存储
wandb.save(checkpoint_path)
# 创建模型、数据集和 DataLoader
model = SimpleModel()
dataset = SimpleDataset()
train_loader = DataLoader(dataset, batch_size=32, shuffle=True)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
train(model, train_loader, criterion, optimizer, num_epochs=5, checkpoint_dir="./checkpoints")
代码解释
-
初始化 Weights & Biases:
wandb.init(project="simple-project", name="simple-experiment")- 初始化 W&B 项目和实验,设置项目名称和实验名称。
-
训练循环:
- 每个 epoch 结束时,计算平均损失和准确率,并使用
wandb.log记录这些指标。
- 每个 epoch 结束时,计算平均损失和准确率,并使用
-
保存模型检查点:
- 每个 epoch 结束时,保存模型的状态字典到本地文件。
checkpoint_path = os.path.join(checkpoint_dir, f"checkpoint_epoch_{epoch+1}.pth") torch.save(model.state_dict(), checkpoint_path) -
使用
wandb.save将检查点文件保存到 W&B 云存储:wandb.save(checkpoint_path)- 这行代码会将保存的检查点文件上传到 W&B 的云存储,以便进行版本控制和共享。
总结
wandb.save 是 Weights & Biases 提供的一个便捷函数,用于将本地文件保存到 W&B 的云存储中。它的主要作用是:
- 备份和共享文件,例如模型检查点、配置文件等。
- 进行文件版本控制,以便在不同的训练实验之间进行对比和分析。
- 通过 W&B 仪表板实时访问和下载保存的文件。
通过这种方式,你可以确保训练过程中生成的重要文件得到了妥善保存和管理。
2.7 wandb.config.update
wandb.config.update 是 WandB(Weights & Biases)库中的一个方法,用于更新当前运行的配置参数。WandB 会将这些配置参数记录下来,以便你在实验追踪和分析时能够查看和比较不同实验的配置。下面是一个详细的解释和示例。
wandb.config.update 的作用
当你在进行实验时,常常需要记录实验的各种参数配置,如学习率、批次大小、模型架构等。wandb.config.update 允许你一次性更新多个配置参数,并将其保存到当前的 WandB 运行中。这些参数可以在 WandB 仪表板上查看,帮助你回溯实验配置和结果。
使用示例
假设你有一组实验参数需要记录到 WandB 中,你可以使用 wandb.config.update 方法。以下是一个完整的示例,包括初始化 WandB 和更新配置参数。
import wandb
# 初始化 WandB
wandb.init(
project="BERT-OCNLI-YF", # 项目名称
name="bert-base-epcoh10-lr5e-5", # 运行名称
mode="online" # 运行模式,可以是 "online", "offline", 或 "disabled"
)
# 创建一个配置字典
config = {
'pretrain_model_name': 'bert-base-chinese',
'num_classes': 3,
'dropout': 0.1,
'batch_size': 32,
'max_length': 128,
'lr': 5e-5,
'epochs': 10
}
# 更新 WandB 配置
wandb.config.update(config)
# 现在你可以继续你的训练脚本,WandB 会自动记录这些配置参数
# 例如,下面是一个简化的训练示例
for epoch in range(config['epochs']):
# 模拟训练过程
train_loss = 0.02 * (epoch + 1) # 假设的训练损失
train_acc = 0.8 + 0.02 * epoch # 假设的训练准确率
# 记录训练损失和准确率到 WandB
wandb.log({'train_loss': train_loss, 'train_accuracy': train_acc})
# 完成 WandB 运行
wandb.finish()
wandb.config.update 的优势
- 简洁性:使用
wandb.config.update你可以一次性更新多个配置参数,代码更简洁。 - 一致性:确保所有配置参数都被记录在 WandB 中,避免遗漏。
- 可追溯性:所有实验配置都保存在 WandB 仪表板上,方便回溯和比较不同实验的配置和结果。
详细解析
wandb.config.update 的调用会将参数字典中的键值对更新到 WandB 当前运行的配置中。以下是一些关键点:
- 字典形式:参数需要以字典形式传递,每个键值对对应一个配置项。
- 自动记录:这些配置项会自动记录到 WandB 仪表板的 “config” 部分。
- 实验追踪:方便你在 WandB 仪表板上查看不同实验的配置和结果,进行对比分析。
通过使用 wandb.config.update,你可以更方便地管理和记录实验配置,提升实验追踪的效率和准确性。
wandb.finish() 是 Weights & Biases(WandB)库中的一个方法,用于结束当前的 WandB 运行。当你完成一个实验或训练任务时,调用 wandb.finish() 可以确保所有的日志数据、配置参数、模型检查点和其他信息被正确地保存和上传到 WandB 仪表板。这个方法帮助你明确地标记一个运行的结束,并释放 WandB 所占用的资源。
使用场景
通常在以下情况下使用 wandb.finish():
- 当一个训练过程或实验完成时。
- 当你想要确保所有数据被正确地上传和保存。
- 当你需要结束当前运行以便开始一个新的 WandB 运行。
3 read_ocnli
read_ocnli 用于读取和解析OCNLI数据集,将其转换为可用于训练和测试的数据格式。OCNLI(Original Chinese Natural Language Inference)数据集包含自然语言推理任务的数据,任务是判断两个句子之间的关系(蕴含、中立或矛盾)。下面是对这个函数的详细解释:
函数定义
def read_ocnli(data_dir, trainval_name, isTest=False):
- 参数:
data_dir: 数据集的目录路径。trainval_name: 数据文件的名称。isTest: 是否是测试数据集。如果是测试数据集,则没有标签(默认值为False)。
标签映射
label_map = {'entailment': 0, 'neutral': 1, 'contradiction': 2, '-': 3}
- label_map: 标签映射字典,将标签从字符串形式转换为整数。
entailment: 0,表示蕴含关系。neutral: 1,表示中立关系。contradiction: 2,表示矛盾关系。'-': 3,表示无法分类的数据。
构建文件路径
file_name = os.path.join(data_dir, trainval_name)
- file_name: 数据文件的完整路径。
读取文件内容
data = []
with open(file_name, 'r', encoding='utf-8') as f:
rows = f.readlines()
- data: 用于存储解析后的数据。
- rows: 读取文件中的所有行。
解析数据
根据 isTest 参数的值,分别处理训练/验证数据和测试数据。
处理训练/验证数据
if not isTest:
for row in rows:
row = json.loads(row)
# 去除无法分类的标签
if row['label'] == '-':
continue
data.append(
(
(row['sentence1'], row['sentence2']),
label_map[row['label']]
)
)
- 如果
isTest为False(即处理训练/验证数据):- 对每一行数据进行解析(将JSON字符串转换为Python字典)。
- 如果标签为
'-',则跳过这条数据。 - 否则,将句子对和对应的标签添加到
data列表中。格式为((sentence1, sentence2), label)。
处理测试数据
else:
for row in rows:
row = json.loads(row)
data.append(
(
(row['sentence1'], row['sentence2']),
)
)
- 如果
isTest为True(即处理测试数据):- 对每一行数据进行解析。
- 将句子对添加到
data列表中。格式为((sentence1, sentence2),),没有标签。
返回解析后的数据
return data
- 最后,返回解析后的数据列表
data。
工作流程总结
- 初始化标签映射:定义一个字典将标签映射为整数。
- 构建文件路径:根据数据目录和文件名构建完整的文件路径。
- 读取文件:打开文件并读取所有行。
- 解析数据:
- 对于训练/验证数据:解析每一行,过滤掉无法分类的数据,将句子对和标签添加到数据列表。
- 对于测试数据:解析每一行,将句子对添加到数据列表,不包括标签。
- 返回数据:返回解析后的数据列表,供后续模型训练或评估使用。
4 OCNLI_Dataset
class OCNLI_Dataset(Dataset):
def __init__(
self,
dataset,
device,
max_length=128,
pretrain_model_name='bert-base-chinese'
):
self.tokenizer = AutoTokenizer.from_pretrained(pretrain_model_name)
sentences = [i[0] for i in dataset]
labels = [i[1] for i in dataset]
self.texts = self.tokenizer.batch_encode_plus(
batch_text_or_text_pairs=[
(sentence[0], sentence[1]) for sentence in sentences
],
truncation=True,
padding='max_length',
max_length=max_length,
return_tensors='pt',
return_length=True
)
self.input_ids = self.texts['input_ids'].to(device)
self.attention_mask = self.texts['attention_mask'].to(device)
self.token_type_ids = self.texts['token_type_ids'].to(device)
self.labels = torch.LongTensor(labels).to(device)
def __len__(self):
# return len(self.labels)
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.attention_mask[idx], self.token_type_ids[idx], self.labels[idx]
4.1 AutoTokenizer.from_pretrained(pretrain_model_name)
这行代码使用了 transformers 库中的 AutoTokenizer 类来加载一个预训练的 BERT 分词器。AutoTokenizer 是一个通用的分词器接口,适用于各种预训练模型。
-
AutoTokenizer:AutoTokenizer是transformers库中的一个类,它可以根据指定的模型名称自动加载相应的分词器。这种设计使得你可以方便地切换不同的预训练模型,而不需要修改太多代码。
-
from_pretrained(pretrain_model_name):from_pretrained方法根据预训练模型的名称加载分词器的配置和词汇表。pretrain_model_name是预训练模型的名称,在这个例子中是'bert-base-chinese',表示加载中文 BERT 基础模型的分词器。
self.tokenizer = AutoTokenizer.from_pretrained(pretrain_model_name)
这行代码会从 Hugging Face 的模型库中加载 BERT 的中文分词器,使其可以处理中文文本的分词操作。
4.2 self.texts = self.tokenizer.batch_encode_plus(…)
这段代码使用加载的分词器对输入的句子对进行批量编码。
详细解释
-
batch_encode_plus方法:batch_encode_plus是transformers库中的一个方法,用于对一批文本或文本对进行编码。它可以处理多个句子对,并将它们转换为模型所需的输入格式。
-
参数:
batch_text_or_text_pairs: 输入的文本或文本对。在这个例子中,输入的是一个句子对列表。truncation=True: 启用截断,如果句子对的长度超过max_length,则会被截断。padding='max_length': 启用填充,如果句子对的长度小于max_length,则会填充到max_length。max_length=max_length: 设置最大长度。这里max_length是 128。return_tensors='pt': 指定返回的格式为 PyTorch 的张量。return_length=True: 返回每个编码后的输入的实际长度。
self.texts = self.tokenizer.batch_encode_plus(
batch_text_or_text_pairs=[
(sentence[0], sentence[1]) for sentence in sentences
],
truncation=True,
padding='max_length',
max_length=max_length,
return_tensors='pt',
return_length=True
)
整个过程
-
输入数据:
sentences是一个包含多个句子对的列表。- 通过列表推导式
[(sentence[0], sentence[1]) for sentence in sentences],将每个句子对提取出来,形成一个新的列表。
-
编码:
batch_encode_plus对这些句子对进行编码,将它们转换为模型可以理解的格式。编码后的结果包括input_ids,attention_mask, 和token_type_ids。
-
返回结果:
input_ids: 编码后的输入 ID。attention_mask: 注意力掩码,指示哪些位置是实际输入,哪些是填充。token_type_ids: 指示每个 token 属于第一个句子还是第二个句子。
这些编码结果会被存储在 self.texts 中,并进一步转换为 PyTorch 张量,保存在 self.input_ids, self.attention_mask, 和 self.token_type_ids 中。
总结
self.tokenizer = AutoTokenizer.from_pretrained(pretrain_model_name)加载了一个预训练的 BERT 中文分词器。self.texts = self.tokenizer.batch_encode_plus(...)使用加载的分词器对句子对进行批量编码,生成模型所需的输入格式,包括input_ids,attention_mask, 和token_type_ids。这些编码结果被转换为 PyTorch 张量,方便后续模型的训练和推理。
5 基于BERT的文本分类器
这段代码定义了一个,其中包括两个类:BertClassificationHead和BertClassifier。下面是对这段代码的详细解释:
5.1 BertClassificationHead 类
这个类定义了分类头,负责将BERT的输出特征映射到分类任务的输出空间。
class BertClassificationHead(nn.Module):
def __init__(self, hidden_size=768, num_classes=3, dropout=0.1):
super().__init__()
self.dense = nn.Linear(hidden_size, hidden_size)
self.dropout = nn.Dropout(dropout)
self.out_proj = nn.Linear(hidden_size, num_classes) # (输入维度,输出维度)
def forward(self, features, **kwargs):
x = features[-1][:, 0, :] # features[-1]是一个三维张量,其维度为[批次大小, 序列长度, 隐藏大小]。
x = self.dropout(x) # 正则化技术,防止过拟合。
x = self.dense(x) # 全连接层,线性变换。
x = torch.tanh(x) # 激活函数,引入非线性。
x = self.dropout(x) # 增加模型的泛化能力。
x = self.out_proj(x) # 最后的全连接层,将特征映射到输出空间。
return x
详细解释
-
初始化方法
__init__:hidden_size: BERT隐藏层的维度,默认为768。num_classes: 分类任务的类别数量,默认为3。dropout: Dropout正则化的概率,默认为0.1。self.dense: 全连接层,将输入特征映射到新的特征空间。self.dropout: Dropout层,用于防止过拟合。self.out_proj: 最后的全连接层,将特征映射到输出类别。
-
前向传播方法
forward:features[-1][:, 0, :]: 取BERT最后一层的[CLS]标记的输出。self.dropout(x): 进行Dropout操作。self.dense(x): 全连接层变换。torch.tanh(x): 使用Tanh激活函数。self.dropout(x): 再次进行Dropout操作。self.out_proj(x): 最后的全连接层,输出分类结果。
5.2 BertClassifier 类
这个类定义了整个分类模型,包括加载预训练的BERT模型和分类头。
class BertClassifier(nn.Module):
def __init__(self, pretrained_model_name, num_classes, dropout=0.1):
super().__init__()
self.bert = BertModel.from_pretrained(pretrained_model_name, output_hidden_states=True)
self.classifier = BertClassificationHead(
hidden_size=self.bert.config.hidden_size,
num_classes=num_classes,
dropout=dropout
)
def forward(self, input_ids, attention_mask, token_type_ids):
outputs = self.bert(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
logits = self.classifier(outputs.hidden_states)
return logits
详细解释:
-
初始化方法
__init__:pretrained_model_name: 预训练BERT模型的名称。num_classes: 分类任务的类别数量。dropout: Dropout正则化的概率。self.bert: 加载预训练的BERT模型,并设置输出隐藏状态。self.classifier: 实例化BertClassificationHead类,作为分类头。
-
前向传播方法
forward:input_ids,attention_mask,token_type_ids: BERT模型的输入。outputs = self.bert(...): 获取BERT的输出,包括隐藏状态。logits = self.classifier(outputs.hidden_states): 使用分类头对BERT的输出进行分类。return logits: 返回分类结果。
工作流程总结
-
BERT 模型:
BertClassifier初始化时加载预训练的BERT模型,并将其输出(包括隐藏状态)传递给分类头。
-
分类头:
BertClassificationHead接收 BERT 的输出特征,对其进行Dropout、全连接层变换、激活函数变换,再次Dropout,最后通过一个全连接层得到分类结果。
-
前向传播:
- 输入数据经过BERT模型处理后,通过分类头进行特征变换,最终输出分类结果。
6 项目目录结构
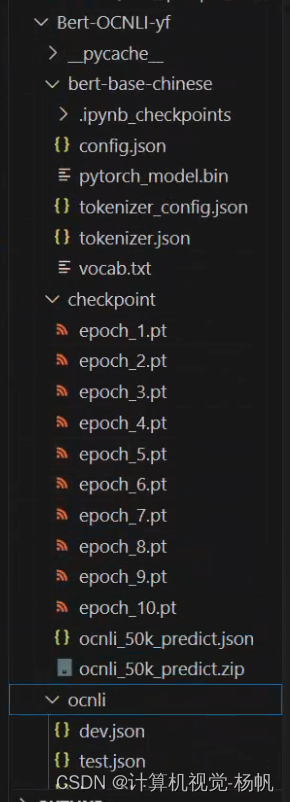

代码:https://github.com/Whiffe/Bert-OCNLI/tree/main/Bert-OCNLI-yf















 1273
1273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









