







目录
0 资料
这是一个系列:
过去的内容:
Bert 在 OCNLI 训练微调
Bert 在 OCNLI 训练微调 2
arxiv:RoBERTa: A Robustly Optimized BERT Pretraining Approach
pytorch官方实现:https://pytorch.org/hub/pytorch_fairseq_roberta/
hugging face hfl chinese-roberta-wwm-ext:https://huggingface.co/hfl/chinese-roberta-wwm-ext/tree/main
1 项目搭建
1.1 环境安装
安装transformers
pip install transformers
pip install pandas
pip install wandb
1.2 项目源码
https://github.com/Whiffe/Bert-OCNLI/tree/main
1.3 模型下载
oBERTa, MacBERT,structbert-large-zh
https://huggingface.co/junnyu/structbert-large-zh
1.4 目录结构
2 改进部分
相对于Bert 在 OCNLI 训练微调 2,我做了代码的更多改进。
改进如下:
1,可以实现更多模型的切换
2,固定随机种子,保证输出的数据一致
3,增加了另一个数据集进行联合训练
4,模型测试时选择最好的一个模型而非最后一个
2.1 可以实现更多模型的切换
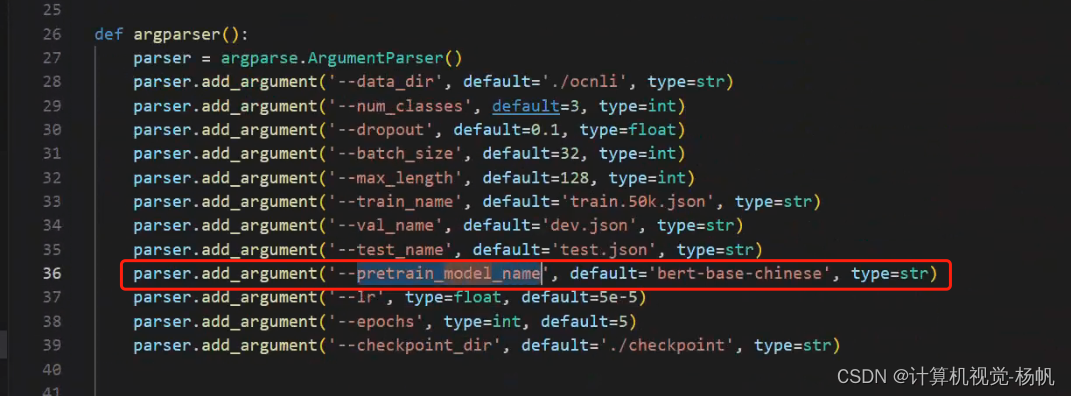
通过 --pretrain_model_name 来传递你的模型
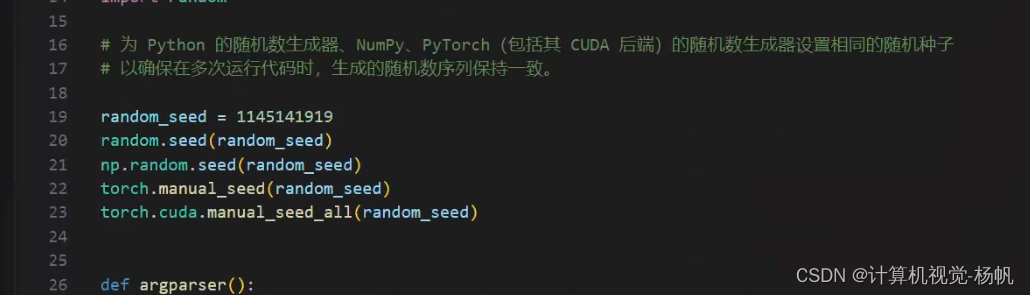
2.2 固定随机种子,保证输出的数据一致
2.3 增加了另一个数据集进行联合训练

中文自然语言推理数据集(A large-scale Chinese Nature language inference and Semantic similarity calculation Dataset):https://github.com/pluto-junzeng/CNSD?tab=readme-ov-file

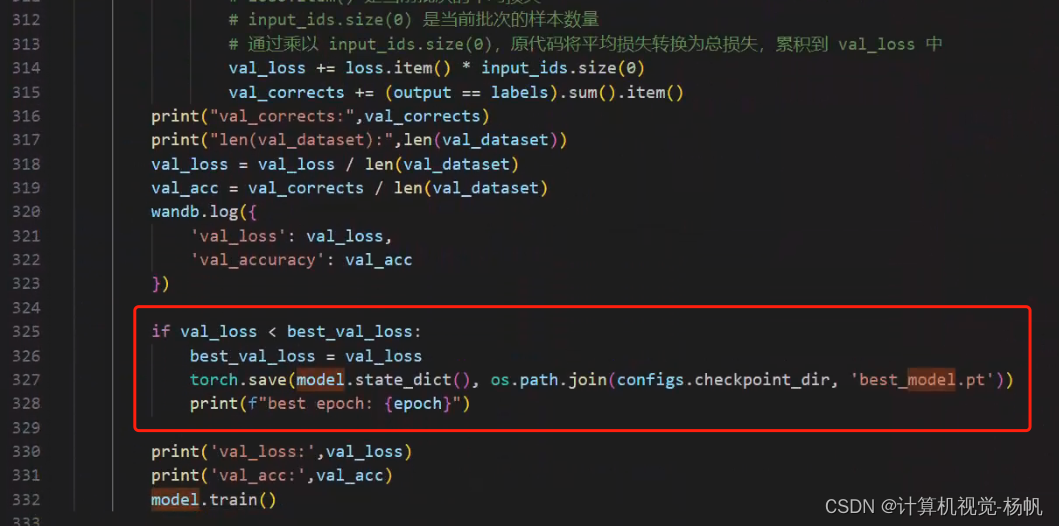
2.4 模型测试时选择最好的一个模型而非最后一个
3 实验结果
参数设置:dropout=0.3、batch_size=32、max_length=128、lr=5e-5、epochs=5、train.50k.json
roberta模型:71.57%
Chinese-SNLI 550k到训练集中,共550+50=600k的数据
准确率:70.23%
Chinese-SNLI 550k按照5%的概率取样到训练集集中。共27.5+50=77.5k的数据
准确率:72.1%
Chinese-SNLI 550k按照10%的概率取样到训练集集中。共55+50=105k的数据
准确率:71.37%
MacBERT模型:73.23%
Chinese-SNLI 550k按照10%的概率取样到训练集集中。共55+50=105k的数据
准确率:71.6%
structbert-large-zh模型:76.83%
chinese-roberta-wwm-ext-large模型:















 1297
1297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









