






来源丨泡泡机器人SLAM
点击进入—>3D视觉工坊学习交流群
标题:Learning-based Localizability Estimation for Robust LiDAR Localization
作者:Julian Nubert, Etienne Walther, Shehryar Khattak and Marco Hutter(苏黎世联邦理工大学 ETHZ)
来源:IROS 2022
编译:曹明
审核:阮建源 王志勇

摘要

基于激光雷达的定位与建图系统是许多现代机器人系统中的核心组成部分。其直接继承了环境的深度与几何信息,从而允许精确的运动估计与实时生成高质量的地图。然而,不充分的环境约束会导致定位失败,这种情况经常发生在诸如隧道等对称的场景中。本文的工作准确地解决了这个问题,通过神经网络法来检测机器人的周围环境是否发生退化。我们特别关注于激光雷达的帧间匹配,因为其是许多激光雷达里程计的至关重要的部件。与之前的方法不同的是,我们的方法直接根据原始的点云测量来检测定位失败的可能,而不是在配准过程中检测。此外,之前的方法在泛化能力上有所局限,因为需要人为调节退化检测的阈值。我们提出的方法通过从一系列不同的环境中学习来使得网络在各个场景中都表现得更好,从而避免了这个问题。此外,该网络专门针对模拟数据进行训练,避免在具有挑战性和退化且通常难以访问的环境中进行艰巨的数据收集。所提出的方法在未经任何修改的情况下,在具有挑战性的环境和两种不同的传感器类型上进行的实地实验中进行了测试。观察到的检测性能与最先进方法在专门调整阈值后的性能相当。

主要贡献

提出一种基于学习的方法,来检测单帧点云在六个自由度上是否发生退化。
提出一种验证方法,来验证四足机器人在挑战性与退化场景下的定位能力。
所有部分都经过完备的设计与实现,包括数据集的采集与生成。相关的部分均会在机器人社区开源。

方法论

1. 问题建模
本文想检测机器人在某个时刻的定位能力:(localizability)。这可以通过一个6维的向量表示:
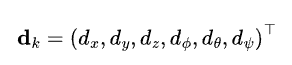
其中,x, y, z表示平移方向上的分量,Φ,θ,ψ表示旋转方向上的分量(欧拉角表示)。向量d_k的每个分量都是二值的(0或者1,其中0表示该分量上的定位信息可靠,1则表示不可靠)。
估计d_k的过程可以构建为一个多标签二值分类问题,并且通过一个神经网络分类器得到结果。
2. 训练数据生成
按照上述的问题建模方式,一个重要的点是如何生成带有标签的训练数据?具体而言,对一个点云,如何评估它在六个自由度上的退化情况?
本文提出的方法是加扰动然后看配准误差的方式。对于某个点云s以及采集到它时机器人的位姿T,生成M个子点云,生成一个子点云的方式为:
1. 对位姿进行扰动,扰动的值通过对0均值高斯分布进行采样,每个维度上的高斯分布的δ为:
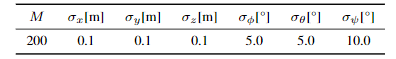
2. 根据扰动后的位姿,在仿真环境中,通过光线投射来获得一个新的子点云。
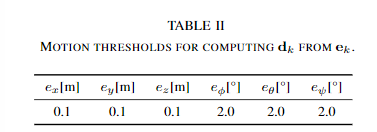
将这M个子点云与原始点云进行配准,配准方法为点到面的ICP方法。计算每个子点云配准得到的transform与原始扰动的transform的差值e,分解到六个维度上取绝对值,并相加求平均值得到e_p。通过评估e_p在6个维度上是否超过特定的阈值,来判断原始点云是否容易在特定的维度上发生退化。6个维度上的阈值为:
3. 网络结构
上一步获得了带有标签的点云,这一步则是通过网络来学习并训练。本文所采取的网络结构基于3D ResUNet(见论文Fully convolutional geometric features),其具体网络结构为:
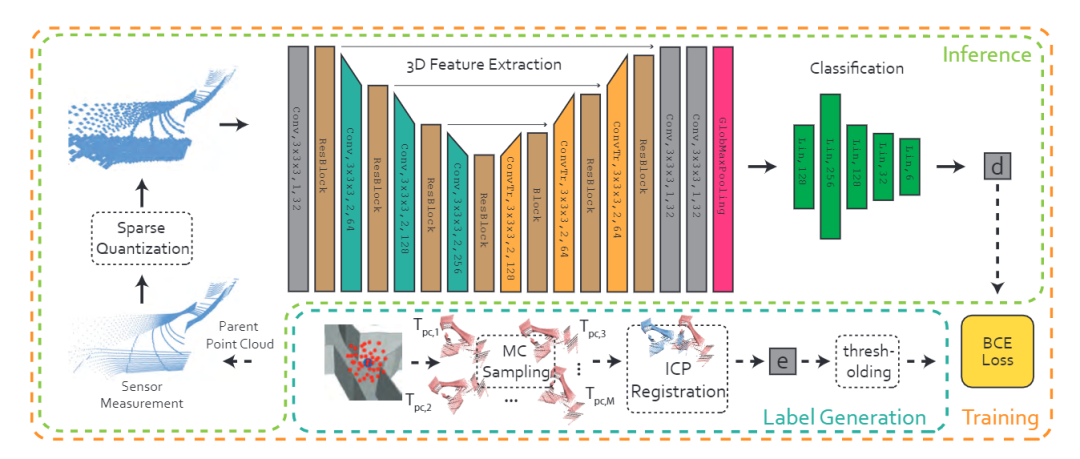
分类网络则是一个5层的MLP,输出是一个6维的向量。
该网络的损失函数定义为:
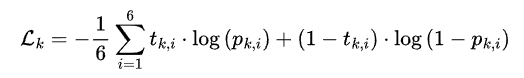
其中,t表示第k个点云在第i个分量上的标签,而p则表示网络预测的对应的概率值。
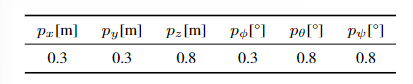
由于网络预测的是一个概率值,在使用时本文通过对各个维度设置不同的阈值来确定各个维度是否发生退化,其值为

方法论

1. 消融实验
在该实验中,将特征提取网络换为Point-Net,并且比较了更换前后的各项分类性能:
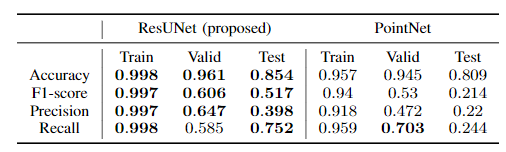
从表格中可以得出,在大部分指标中,ResUNet均高于PointNet。
2.实地实验
在三个场景中进行了场地实验:隧道、开阔户外与城镇场景。采用的SLAM框架为CompSLAM(见论文Complementary multi–modal sensor fusion forresilient robot pose estimation in subterranean environments)。这个框架中,所用的评估退化的方式是Ji Zhang的论文“On Degeneracy of Optimization-based State Estimation Problems”中提到的方法(该论文在泡泡机器人-点云时空中亦有详细翻译,有兴趣同学可以自行搜索)。CompSLAM在检测到激光雷达出现退化后,切换为VIO的结果进行递推,而在没有退化的场景中,用VIO的结果作为LOAM的先验进行帧间配准。本文将该方法替换为所提出的基于学习的方法,并与原始版本的CompSLAM进行比较。
a. 隧道场景:
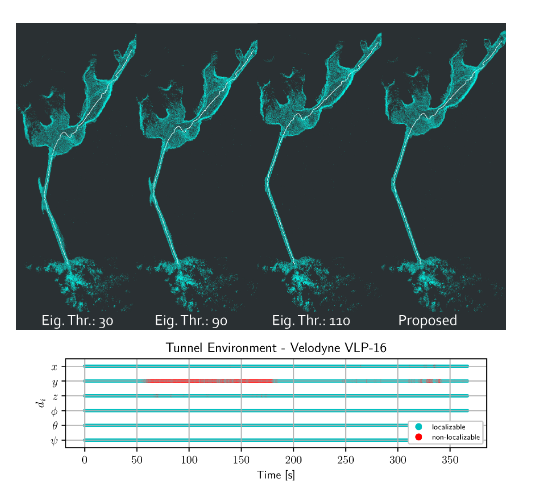
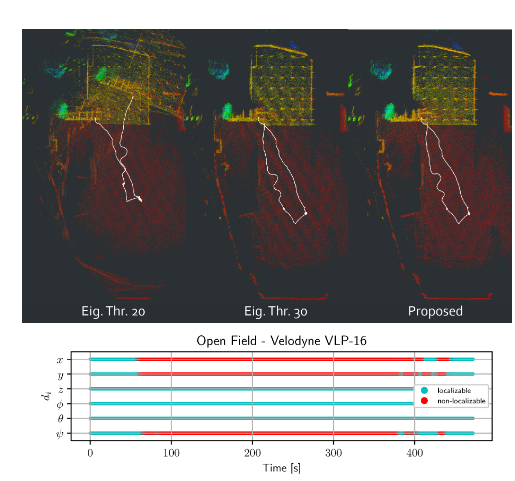
下图给出了隧道场景中的建图效果。其中左边三幅图为Ji zhang的方法采用不同阈值后的结果,最右则为本文提出的结果。而下面的条状图则表示各个维度出现退化的时间。可以看出,本文提出的方法与Ji Zhang的方法在阈值为110时的效果类似。
b. 开放户外场景:
同隧道场景。
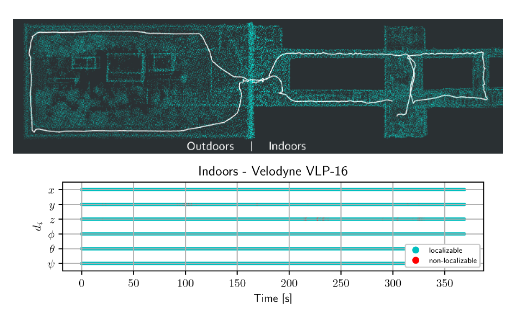
c. 城市场景:
这个场景中没有做对比试验,而是仅仅测试了提出的方法。测试场景为咖啡店的内部与外部。机器人从室内走到室外并且回到室内,可以看到建图保持了较好的一致性,并且学习到的6维向量表示全程都没有发生退化情况
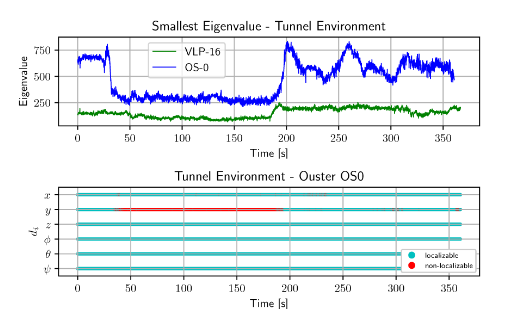
3. 泛化实验
对于隧道场景,利用VLP-16与Ouster 128线的激光雷达进行测试。从下图中可以看出,利用Ji zhang的方法(即求一个特定矩阵的最小特征值),对于两个传感器,其最小特征值的差别是巨大的。然而本文所提出的方法仍能比较好的检测到隧道的特定段发生了退化,并且与场地实验中的隧道实验保持一致。

评价与未来工作

1. 个人评价
这项工作的创新在于直接对点云进行退化的评估,而不是根据配准的结果。数据的生成与训练的方式都比较直接易懂,并且实验的效果也很好。
这个方法是应用在类似于LOAM的系统上的,因此制作训练集的时候,只用单帧点云的匹配结果来生成退化label。对于类似于Fast-LIO这样直接进行scan-map配准的方法,这种制作训练集并训练的方式不一定可靠:因为在一些场景下,可能出现scan-scan配准退化,但scan-map不一定是退化的(local map有更丰富的信息)。解决这个问题的途径之一,可以在训练的时候也采用scan-map的配准方法来评价配准误差。
2. 未来工作
本文的作者提出的未来工作有:
1)网络直接出6x6的位姿协方差矩阵。
2)根据退化信息来决定优化的时候,仅仅优化部分维度而不是所有维度。
Abstract
Abstract— LiDAR-based localization and mapping is one ofthe core components in many modern robotic systems dueto the direct integration of range and geometry, allowing forprecise motion estimation and generation of high quality mapsin real-time. Yet, as a consequence of insufficient environmentalconstraints present in the scene, this dependence on geometrycan result in localization failure, happening in self-symmetricsurroundings such as tunnels. This work addresses precisely thisissue by proposing a neural network-based estimation approachfor detecting (non-)localizability during robot operation. Specialattention is given to the localizability of scan-to-scan registra-tion, as it is a crucial component in many LiDAR odometryestimation pipelines. In contrast to previous, mostly traditionaldetection approaches, the proposed method enables early de-tection of failure by estimating the localizability on raw sensormeasurements without evaluating the underlying registrationoptimization. Moreover, previous approaches remain limitedin their ability to generalize across environments and sensortypes, as heuristic-tuning of degeneracy detection thresholds isrequired. The proposed approach avoids this problem by learn-ing from a collection of different environments, allowing thenetwork to function over various scenarios. Furthermore, thenetwork is trained exclusively on simulated data, avoiding ardu-ous data collection in challenging and degenerate, often hard-to-access, environments. The presented method is tested duringfield experiments conducted across challenging environmentsand on two different sensor types without any modifications.The observed detection performance is on par with state-of-the-art methodsafterenvironment-specific threshold tuning.
本文仅做学术分享,如有侵权,请联系删文。
点击进入—>3D视觉工坊学习交流群
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
3D视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
2.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
3.国内首个面向工业级实战的点云处理课程
4.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
5.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
6.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
7.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
16.透彻理解视觉ORB-SLAM3:理论基础+代码解析+算法改进
重磅!粉丝学习交流群已成立
交流群主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、ORB-SLAM系列源码交流、深度估计、TOF、求职交流等方向。
扫描以下二维码,添加小助理微信(dddvisiona),一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿,微信号:dddvisiona
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、源码分享、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答等进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,6000+星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看,3天内无条件退款

高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

















 632
632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









