






英文题目:YOLO-World: Real-Time Open-Vocabulary Object Detection
阅读一下CVPR2024的这篇文章
摘要:YOLO已经是一种高效且实用的工具,但是依赖于预定义和训练的对象类别,这会限制他们在开放场景中的应用。为了解决这一限制,本文引入YOLO-World,通过视觉-语言建模在大规模数据集上的预训练,增强了YOLO的开放词汇检测能力。设计了一种叫做RepVL-PAN的网络和区域-文本对比损失,促进视觉和语言信息之间的交互。我们的方法在零样本下高效的检测广泛对象。
1. 引言:
目标检测在多个领域中都得到了广泛的使用,虽然这些方法取得了成功,但是只能处理固定词汇的目标检测,在COCO数据集的80个类别,一旦定义和标记了对象类别,训练好的检测器只能检测这些特定的类别,会限制其能力和适用性。
近期的一些工作已经探讨了普遍存在的视觉-语言模型来解决开放词汇检测问题,通过从语言编码器提炼词汇知识,但是由于训练数据的缺失以及词汇多样性有限受到限制。还有工作将目标检测训练定义为区域级视觉-语言预训练,但是在现实场景中的检测仍然存在困难,主要有两个原因:(1)计算负担重;(2)边缘设备的部署复杂。
本文提出YOLO-World,旨在实现高效开放词汇物体检测。具体而言,YOLO-World遵循标准的YOLO框架,使用预训练的CLIP文本编码器对输入文本进行编码。提出RepVL-PAN网络连接文本特征和图像特征,从而实现更好的视觉语义表示,在推理过程中,将文本编码器进行移除,将文本嵌入重新参数化为RepVL-PAN的权重实现高效的部署。
2. 相关工作
2.2 开放词汇目标检测
开放词汇目标检测是现代目标检测的新趋势,旨在检测预定义类别之外的对象,

(a)传统的目标检测器,只能检测由训练数据集预先定义的固定词汇中的对象,固定词汇限制了开放场景的扩展,(b)之前的开放词汇检测器,倾向于开发大型重量级的检测器用于开放词汇检测,同时将图像和文本作为输入进行预测,这对于实际应用是耗时的,(c)轻量级检测器强大的开放词汇性能,不再使用在线词汇,而是提出了一种提示-检测范式,用于高效的推理,用户根据提示生成一系列提示,这些提示将被编码为离线词汇,可以重新参数化为模型的权重来部署和进一步实现加速。
3. 方法
3.1 预训练公式:区域-文本对
传统的目标检测是通过实例标注进行训练的![]() ,这些标注是边界框(Bi)和类别标签(ci)构成的,在本文中,将实例标注重新定义为区域-文本对
,这些标注是边界框(Bi)和类别标签(ci)构成的,在本文中,将实例标注重新定义为区域-文本对![]() ti是区域Bi对应的文本,ti可以是类别名称,名词短语或者物体描述。YOLO-World采用图像I和文本T(一组名词)作为输入,并预测边界框Bk以及相应的物体嵌入ek。
ti是区域Bi对应的文本,ti可以是类别名称,名词短语或者物体描述。YOLO-World采用图像I和文本T(一组名词)作为输入,并预测边界框Bk以及相应的物体嵌入ek。
3.2 模型架构
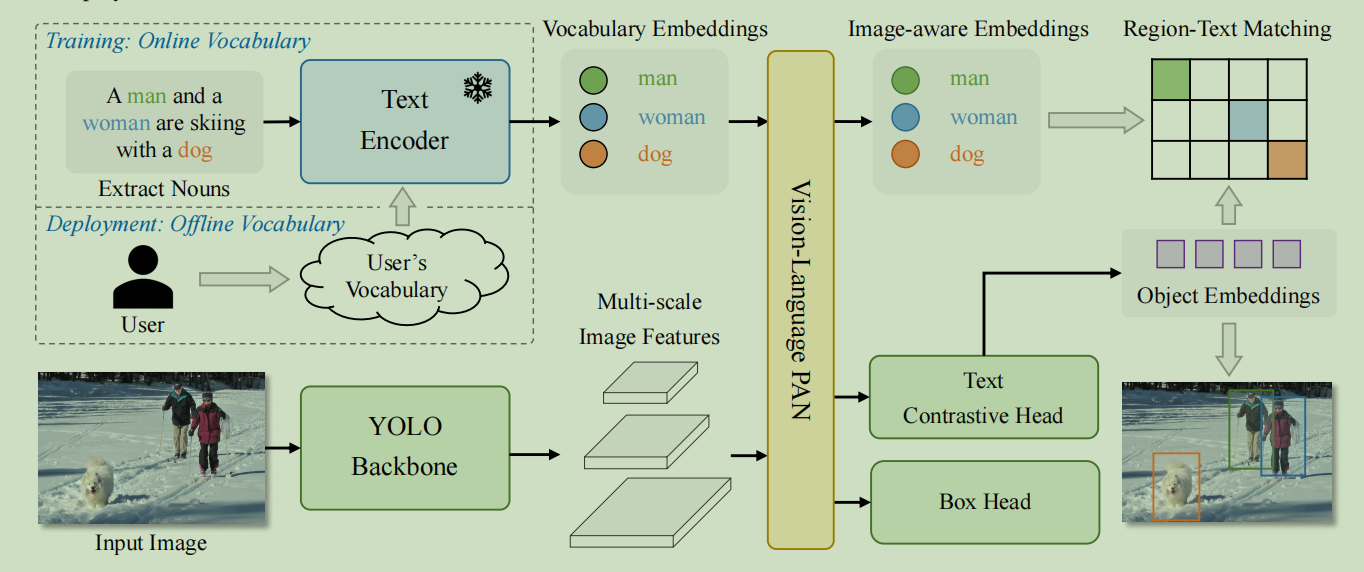
包括一个YOLO检测器,一个文本编码器,一个RepVL-PAN组成,给定输入文本,文本编码器将文本编码为文本嵌入,YOLO中的图像编码器从输入图像中提取多尺度特征,然后利用RepVL-PAN利用图像特征和文本嵌入之间的跨模态融合来增强文本和图像表示。
YOLO检测器:利用YOLOI-v8开发
文本编码器:给定文本T,使用CLIP预训练的Transformer文本编码器提取相应的文本嵌入
![]() ,C是名词数量,D是嵌入维度,
,C是名词数量,D是嵌入维度,
文本对比头部,采用两个3×3娟姐解耦头部来回归边界框![]() 和对象嵌入
和对象嵌入![]() ,K是对象的数量,提出一个对比头部来获得对象-文本相似度skj:
,K是对象的数量,提出一个对比头部来获得对象-文本相似度skj:
![]()
在线词汇训练:在训练过程中,我们为每个包含 4 张 图像的拼贴样本构建一个在线词汇表。具体来说,我 们从拼贴图像中采样所有涉及的正面名词,并从相应的数据集中随机采样一些负面名词。每个拼贴样本的词汇表最多包含 M 个名词,M 默认设置为 80。
离线词汇进行推理:在推理阶段,用户可以定义一系列自定义提示,包括字幕或者类别,然后使用文本编码器对这些提示进行编码,获得离线词汇嵌入,离线词汇允许避免对 每个输入进行计算,并提供了根据需要调整词汇的灵活性。
3.3 可重参数化的视觉-语言PAN
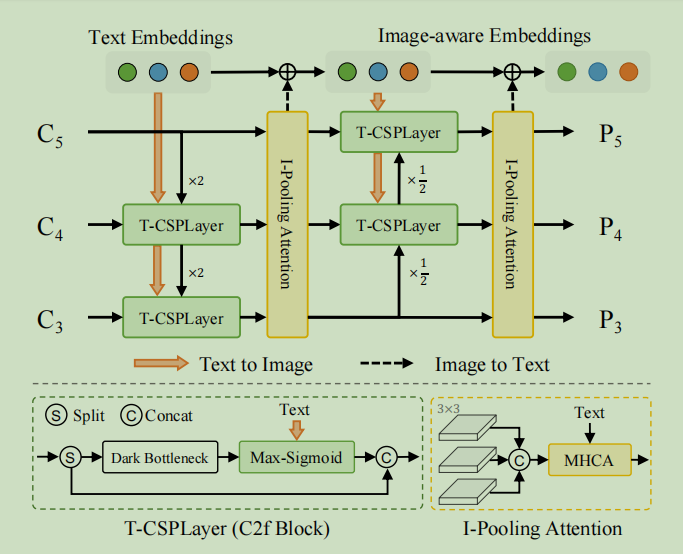
RepVL-PAN还是有自顶向下和自底向上的路径,建立多尺度图像特征(P3,P4,P5)。此外,T-CSPLayer和图像池化注意力I-PlloingAttention会进一步增强图像特征和文本特征之间的交互,从而提高开放词汇能力的视觉语义表示。
这篇文章主要是拓展知识面去阅读,我做的是传统的目标检测,这种开放词汇的目标检测并不涉猎,感兴趣的去阅读原文,代码仓库:AILab-CVC/YOLO-World: [CVPR 2024] Real-Time Open-Vocabulary Object Detection

















 262
262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









