







一、DML
DML: data manipulation language statements of SQL.
1. select
标准使用:
select COLUMN1, COLUMN2, ... FROM TABLE
WHERE condition
;
通常使用select的时候会有几个比较游泳的built-in function 配合使用:
count():计数,计算多少行之类的limit取多少行
举例:select * from tables LIMIT 15 OFFSET 10,从第十行后取15行distinct:剔除相同的元素,仅仅保留不同的元素,有点像数据结构中的set
2. insert、update、delete
insert:
insert into table_name(col1, col2,...)
values
(value1, value2, ...),
(value1, value2, ...)
;
如果insert多行,在values关键字后面续加多个(),()之间用逗号分割开。
update:
update table_name
set col1=value1,col2=value2, ...
where condition
;
其中where关键字限制某一行的更改,否则将会更改整列的数据
delete
delete from table_name
where condition
;
同样的,delete语句可以使用where来限制删除对应的行。
二、DDL
数据定义语言,用来定义数据库对象:库、表、列等
1. create
create table table_name(
col1 datatype,
col2 datetype,
...
);
2. alter
-- 添加一列
alter table table_name
add column col_name data_type column_constraint;
-- 删除一列
alter table table_name
drop column column_table;
-- 修改column数据类型
alter table table_name
alter column column_name set data type date_type;
-- 修改column名字
alter table table_name
rename column current_column_name to new_col_name;
3. truncate
truncate table table_name;
直接将数据截取掉,仅仅保留第一行列表头
4. drop
drop table table_name;
三、进阶select
1. group by
本质是distinct的升级版本, 比如可以通过count()给出个数,通过sum()算出每类的总数等
举例:
select dep_id, count(*) from empoloyees
group by dep_id
;
2. select from
可以使用string pattern, range, set等筛选select的数据
string pattern
举例:
- 从家庭地址中包换
elgin的雇员名字
select name from employees[
where address like '%elgin%'
;
其中%类似通配符,能够匹配0-多个任意字符。
range
关键字:
between ... and ... 针对连续
in (.., ..) 针对离散
输出所有薪资在60000-70000之间的并且depid为5的雇员信息。
SELECT *
FROM EMPLOYEES
WHERE (SALARY BETWEEN 60000 AND 70000) AND DEP_ID = 5;
selsec f_name, l_name country from Author
where country in ('AU', 'CN')
;
order by
从employee中筛选雇员,先按depid降序,再按照lastname降序
SELECT F_NAME, L_NAME, DEP_ID
FROM EMPLOYEES
ORDER BY DEP_ID DESC, L_NAME DESC;
order可以通过数字来制定order的col,比如上面的例子中,最后order部分可以写成:
order by 3 desc, 2 desc;
另外,在现实数据中通常包含很多null,所以为了避免null出现在想要的list中,通常会在oder by的最后添加nulls last关键字。
replace
在查询结果显示的时候,通常可以使用replace方法来实现文本的替换
语法:
replace(source_string, search_string, repolace_string)
举个例子,比如想要将数据列表中的百分号去掉,我们可以这样做:
select name_of_school,
replace(average_student_attendance,'%','') as average_student_attendance_rate from schools
order by average_student_attendance nulls last
limit 5;
数据转换
比如之前的例子中,我们想要找到学生出席概率低于 70% 的学校,但是该col的数据类型是varchar,所以我们需要将其转换为浮点数或小数类型才可以进行数值比较。
两种转换方法:
DECIMAL("COL_NAME")
CAST("COL_NAME" as DOUBLE)
select name_of_school, average_student_attendance from schools
where cast(replace(average_student_attendance,'%','') as double)< 70
;
四、built-in function
- sum()
- min()
- max()
- avg()
- round()
- length()
- ucase()
- lcase()
时间相关的一些内建函数:
注意操作的列的数据类型必须是时间。
时间类型可以加减
- day()
- month()
- current date: 当前时间
五、sub-queries
这部分的查询通常基于第四部分中出现的函数输出的结果,配合使用。
举例:
正确的写法:
select EMP_ID, F_NAME, L_NAME, SALARY
from employees
where SALARY < (select AVG(SALARY)
from employees);
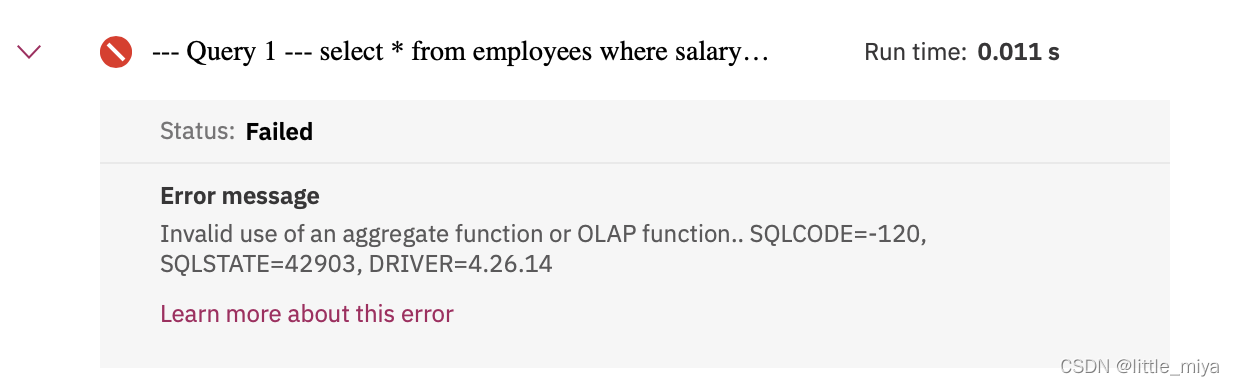
上面例子可以取出所有对应薪资少于平均薪资的员工,但是如果直接使用如下方式就会出错:
错误的写法:
select *
from employees
where salary < AVG(salary);
报错:
六、multi-tables
在多个表格之间进行工作,通常有如下几种方法:
- sub-queries (第五部分提及的)
- implicit JOIN
- JOIN operators (INNER JOIN, OUTER JOIN, etc.)
本部分只介绍第一第二种,第三种join方法会单独列出来,链接如下:
本部分使用的tables如下图所示。

sub_queries
select * from employees
where JOB_ID IN
(select JOB_IDENT from jobs where JOB_TITLE= 'Jr. Designer');
其实就是在括号中,使用另外一个tables与当前table相同的col_name来进行检索。
这种方法会用到 in关键字
implicit join
- CROSS JOIN:
SELECT column_name(s)
FROM table1, table2;
- INNER JOIN
SELECT column_name(s)
FROM table1, table2
WHERE table1.column_name = table2.column_name;
第二种inner join还可以使用alias简写table 名字,比如:
select E.EMP_ID,E.F_NAME,E.L_NAME, J.JOB_TITLE from employees E, jobs J
where E.JOB_ID = J.JOB_IDENT;














 538
538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









