







CRUD = create read update delete
1. write
- cluster level: 发送到所有节点,但是满足consistancy即可,write操作仅仅与receiving node 打交道。
- node level:
- 首先写入内存中,然后刷入disk(SSTables)。
- 每次flush都会创建一个新的SSTables.
- 所有数据先按照顺序写入,然后会被重新整理,这个重新组织的过程叫做Compaction。
- 每次写入操作,都会附带时间戳
2. insert
insert操作要求all primary key columns的value
insert操作只能一条一条record
insert和update没啥区别,如果insert是一个已经存在的record,就是在update
insert数据的时候可以带着TTL插入。
看几个例子:
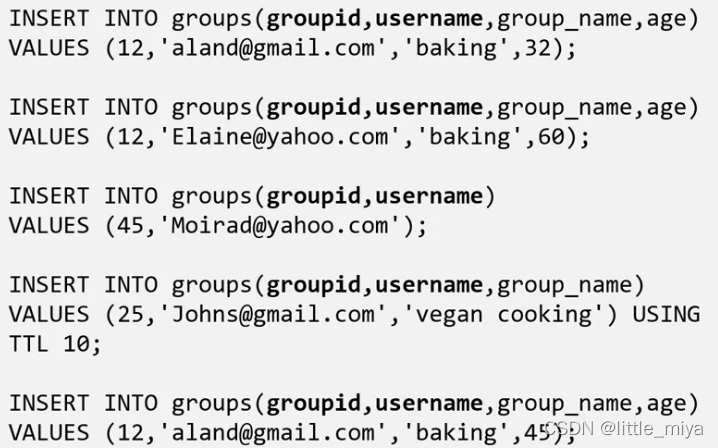
cassandra默认在写入操作之前不会进行读取。
lightweight transactions 可以通过if 关键字实现写之前读取。但是添加了if之后的语句执行速度至少是原有的5倍。尽量少用。
举个例子:
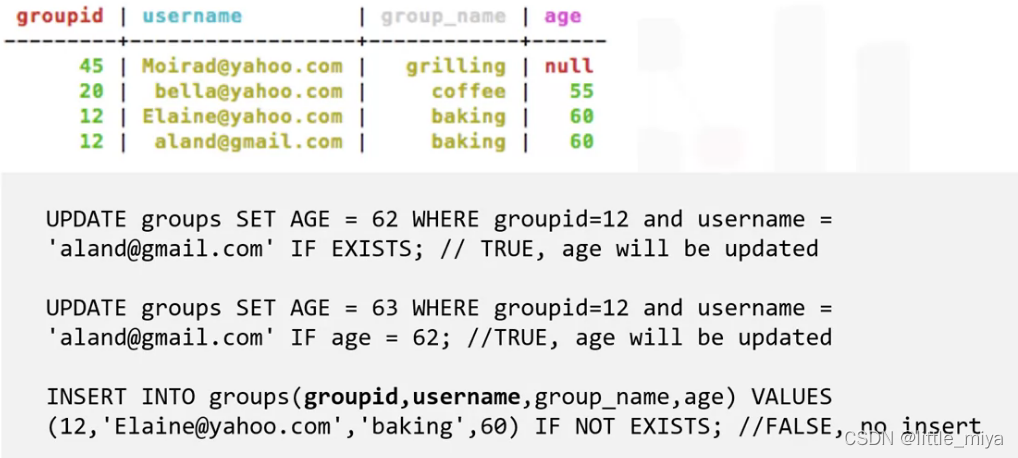
第一个第二个正常update,但是第三个插入失败,因为已经存在。
3. read
read 查询指令首先发送到receiving node, 这个node根据read操作中consistengcy的要求,在cluster中进行协调查找,同时修复一些node中数据的不一致,依据时间戳。
-
cluster- level 的read,只在replicas(基于consistency setting)操作
-
必须通过partition key开始query:限制读取操作于特定的包含想要数据的node
-
查询依据 Primary Key columns的顺序
-
primary key的顺序是: PartitionKey,ClusteringKey1, ClusteringKey2
所以,下图中蓝色部分的查询都没问题,但是红色的查询语法不ok:

原因是,如果不指定PartitionKey,query的请求将会被发送到cluster中所有的nodes. 如果你的cluster中有1000个node,查询的速度慢的将会令人害怕。
所以:
Always start your queries with the partition key!!!
4. DELETE
-
可以在record, cell, range, partition level进行。
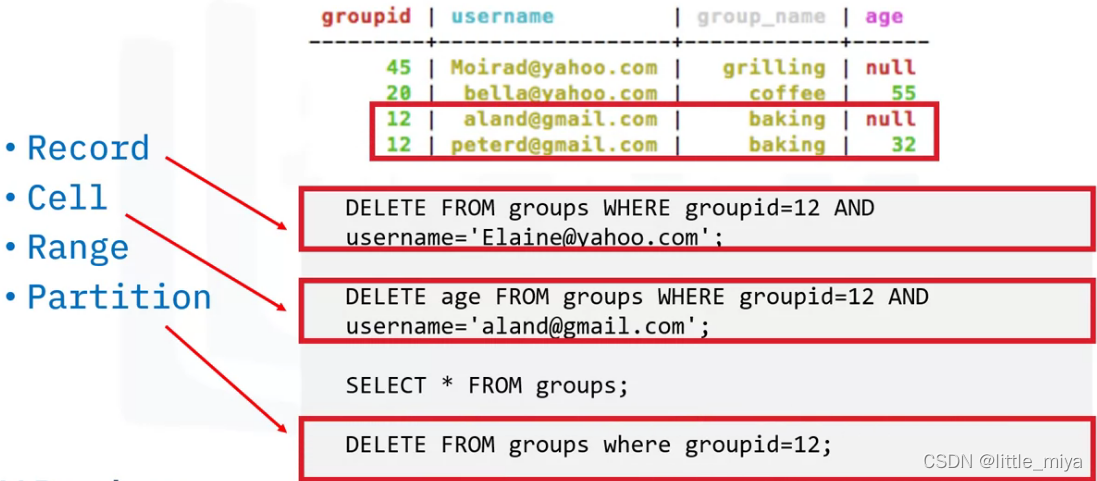
-
Cassandra的删除操作对性能影响大
-
Tombstones: 用于记录delete的value(表示数据已被删除,以及删除的时间),可以阻止从deleted data 进行读取操作。
-
tombstones are deleted at
gc_grace_secondsduring compaction process. 默认是十天,可以在table level自定义。















 255
255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









