








13.4 将元数据添加到 TensorFlow Lite 模型
TensorFlow Lite元数据为模型描述提供了标准,元数据是关于模型做什么及其输入/输出信息的重要信息来源。元数据由如下两者元素组成:
- 在使用模型时传达最佳实践的可读部分
- 代码生成器可以利用的机器可读部分,例如 TensorFlow Lite Android 代码生成器 和 Android Studio ML绑定功能。
在TensorFlow Lite托管模型和TensorFlow Hub上发布的所有图像模型中,都已经被填充了元数据。
13.4.1 具有元数据格式的模型
带有元数据和关联文件的TFLite模型的结构如图13-9所示。
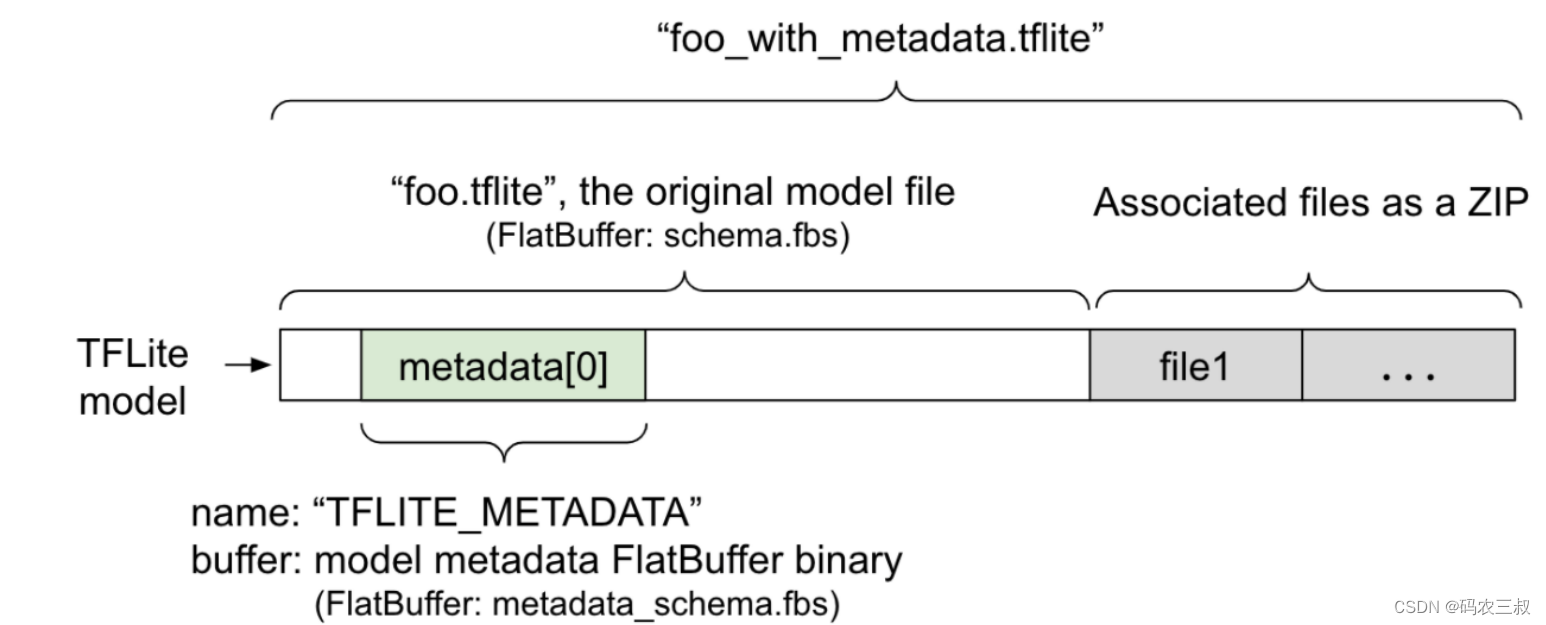
图13-9 带有元数据和关联文件的TFLite模型
模型中的元数据定义了metadata_schema.fbs,它存储在TFLite 模型架构的 metadata 字段中 ,名称为“TFLITE_METADATA”。某些模型可能包含相关文件,例如分类标签文件。这些文件使用 ZipFile “附加”模式( mode)作为 ZIP 连接到原始模型文件的末尾。TFLite Interpreter 可以像以前一样使用新的文件格式。
在将元数据添加到模型之前,需要安装tflite-support工具:
pip install tflite-support13.4.2 使用Flatbuffers Python API添加元数据
要为TensorFlow Lite任务库中支持的ML任务创建元数据,需要使用TensorFlow Lite元数据编写库中的高级API 。模型元数据的架构由如下三个部分组成:
- 模型信息:模型的总体描述以及许可条款等项目。
- 输入信息:所需的输入和预处理(如规范化)的描述。
- 输出信息:所需的输出和后处理的描述,例如映射到标签。
由于此时生成的TensorFlow Lite仅支持单个子图,所以在显示元数据和生成代码时,TensorFlow Lite 代码生成器 和 Android Studio ML 绑定功能 将使用ModelMetadata.nameandModelMetadata.description实现,而不是使用SubGraphMetadata.nameand SubGraphMetadata.description实现。
(1)支持的“输入/输出”类型
在设计用于输入和输出的 TensorFlow Lite 元数据时,并没有考虑到特定的模型类型,而是考虑了输入和输出类型。模型在功能上具体做什么并不重要,只要输入和输出类型由以下或以下组合组成,TensorFlow Lite 元数据就支持这个模型。
- 功能:无符号整数或 float32 的数字。
- 图像:元数据目前支持 RGB 和灰度图像。
- 边界框:矩形边界框。
(2)打包相关文件
TensorFlow Lite模型可能带有不同的关联文件,例如,自然语言模型通常具有将单词片段映射到单词ID 的 vocab 文件;分类模型可能具有指示对象类别的标签文件。如果没有相关文件(如果有),模型将无法正常运行。
我们可以通过元数据 Python 库将关联文件与模型捆绑在一起,这样新的 TensorFlow Lite 模型将变成了一个包含模型和相关文件的 zip 文件,可以用常用的zip工具解压。这种新的模型格式继续使用相同的文件扩展名“.tflite.”,这与现有的 TFLite 框架和解释器兼容。
另外,关联的文件信息可以被记录在元数据中,根据文件类型和文件附加到对应的位置(即ModelMetadata、 SubGraphMetadata和TensorMetadata)。
(3)归一化和量化参数
归一化是机器学习中常见的数据预处理技术,归一化的目标是将值更改为通用标度,而不会扭曲值范围的差异。模型量化是一种技术,它允许降低权重的精度表示以及可选的存储和计算激活。在预处理和后处理方面,归一化和量化是两个独立的步骤,具体说明如表4-1所示。
表4-1 归一化和量化
| 正常化 | 量化 | |
| MobileNet 中输入图像的参数值示例,分别用于 float 和 quant 模型。 | 浮动模型: - mean:127.5 -std:127.5 量化模型: - mean:127.5 - std:127.5 | 浮点模型: - zeroPoint:0 - scale:1.0 定量模型: - zeroPoint:128.0 - scale:0.0078125f |
| 什么时候调用? | Inputs输入:如果在训练中对输入数据进行了归一化处理,则推理的输入数据也需要进行相应的归一化处理。 Outputs输出:输出数据一般不会被标准化。 | 浮点模型不需要量化。 量化模型在前/后处理中可能需要也可能不需要量化。这取决于输入/输出张量的数据类型。 -float tensors:不需要在前/后处理中进行量化。 - int8/uint8 张量:需要在预处理/后处理中进行量化。 |
| 公式 | normalized_input = (input - mean) /std | 输入量化: q = f / scale + zeroPoint 输出去量化: f = (q - zeroPoint) * scale |
| 参数在哪里 | 由模型创建者填充并存储在模型元数据中,如 NormalizationOptions | 由 TFLite 转换器自动填充,并存储在 tflite 模型文件中。 |
| 如何获取参数? | 通过 MetadataExtractorAPI [2] | 通过 TFLite TensorAPI或MetadataExtractorAPI 实现 |
| float 和 quant 模型共享相同的值吗? | 是的,float 和 quant 模型具有相同的归一化参数 | 浮点模型不需要量化。 |
| TFLite 代码生成器或 Android Studio ML 绑定在数据处理中会自动生成吗? | 是 | 是 |
在处理 uint8 模型的图像数据时,有时会跳过归一化和量化步骤。当像素值在 [0, 255] 范围内时,这样做是可以的。但一般来说,应该始终根据适用的归一化和量化参数处理数据。如果在元数据中设置NormalizationOptions参数,TensorFlow Lite 任务库可以为我们解决规范化工作,量化和反量化处理总是被封装。
请看下面的例子,演示在图像分类中创建元数据的过程。
(1)首先创建一个新的模型信息,代码如下:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""为图像分类器创建元数据"""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")(2)输入/输出信息
接下来介绍如何描述模型的输入和输出签名,自动代码生成器可以使用该元数据来创建预处理和后处理代码。创建有关张量的输入或输出信息的代码如下:
#创建输入
input_meta = _metadata_fb.TensorMetadataT()
#创建输出
output_meta = _metadata_fb.TensorMetadataT()(3)图片输入
图像是机器学习的常见输入类型,TensorFlow Lite元数据支持颜色空间等信息和标准化等预处理信息。图像的尺寸不需要手动指定,因为它已经由输入张量的形状提供并且可以自动推断。实现图片输入的代码如下:
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats(4)使用 TENSOR_AXIS_LABELS实现标签输出,代码如下:
#创建输出信息
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file](5)创建元数据 Flatbuffers,通过如下代码将模型信息与输入输出信息结合起来。
#创建子图信息
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()(6)接下来将元数据和相关文件打包到模型中,在创建元数据 Flatbuffers后,通过以下populate方法将元数据和标签文件写入 TFLite 文件。
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()可以将任意数量的关联文件打包到load_associated_files模型中,但是,至少需要打包元数据中记录的那些文件。在这个例子中,打包标签文件是强制性的。
(7)可视化元数据
可以使用Netron来可视化元数据,或者可以使用以下命令将元数据从 TensorFlow Lite 模型读取为JSON格式的MetadataDisplayer:
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
#可选:将元数据写入JSON文件
with open(export_json_file, "w") as f:
f.write(json_file)
















 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











