







在上一篇文章【点云处理】点云法向量估计及其加速(1) 中我们为点云表面法线计算作了理论铺垫,从这一篇开始结合示例代码实际体验点云法线的计算过程,以及在加速方面进行一些尝试。
使用PCL自带NormalEstimation类计算点云法线
pcl自带NormalEstimation的计算过程如下:
对点云P中的每个点p
1.计算p点的最近邻K个元素;
2.计算p点的表面法线n;
3.检查n的方向是否一致指向视点,如果不是则翻转;【示例代码】
#include <time.h>
#include <cmath>
#include <functional>
#include <ros/ros.h>
#include <sensor_msgs/PointCloud2.h>
#include <pcl/console/time.h>
#include <pcl/kdtree/kdtree.h>
#include <pcl/features/normal_3d_omp.h>
#include <pcl_conversions/pcl_conversions.h>
int main(int argc, char** argv) {
ros::init(argc, argv, "n_lidar_normal");
ros::NodeHandle node;
pcl::NormalEstimation<pcl::PointXYZ,pcl::Normal> normal_est;
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud(new pcl::PointCloud<pcl::PointXYZ>);
const boost::function<void (const boost::shared_ptr<sensor_msgs::PointCloud2 const>&)> callback =[&](sensor_msgs::PointCloud2::ConstPtr msg_pc_ptr) {
pcl::fromROSMsg(*msg_pc_ptr, *cloud);
typename pcl::search::KdTree<pcl::PointXYZ>::Ptr kdtree_ptr(new pcl::search::KdTree<pcl::PointXYZ>);
pcl::PointCloud<pcl::Normal>::Ptr normal_ptr(new pcl::PointCloud<pcl::Normal>);
clock_t t1,t2;
t1 = clock();
normal_est.setInputCloud(cloud);
normal_est.setSearchMethod(kdtree_ptr);
normal_est.setViewPoint(0,0,0);
normal_est.setKSearch(10); //neighbour size
normal_est.compute(*normal_ptr);
t2 = clock();
auto cost_time = (float)((t2-t1)*1000/CLOCKS_PER_SEC);
printf("cloud size:%zu, cost time:%.2f ms\n", cloud->size(), cost_time);
};
ros::Subscriber pc_sub = node.subscribe<sensor_msgs::PointCloud2>("/BackLidar/lslidar_point_cloud", 1, callback);
ros::spin();
return 0;
}
【运行结果】
以上示例代码中设置k近邻的大小为10, 运行结果如下。单帧点云的计算时间几乎都超过了1000ms,效率较低。所有计算集中在一个cpu核上,造成该核负载过高。
cloud size:23749, cost time:1348.00 ms
cloud size:26791, cost time:1494.00 ms
cloud size:17848, cost time:995.00 ms
cloud size:43233, cost time:2457.00 ms
cloud size:32185, cost time:1814.00 ms
cloud size:46526, cost time:2638.00 ms
cloud size:26791, cost time:1518.00 ms
cloud size:17848, cost time:996.00 ms
cloud size:43233, cost time:2470.00 ms
cloud size:56268, cost time:3229.00 ms
cloud size:36209, cost time:2043.00 ms
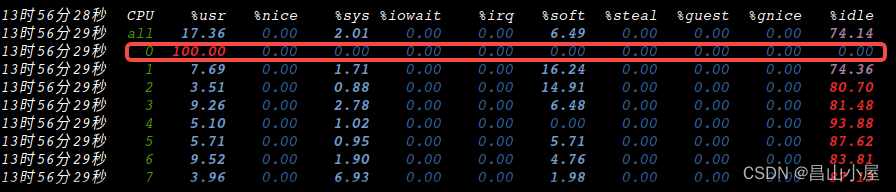
使用OpenMP加速法线估计
pcl提供了一个点云表面法线的附加实现程序,它使用多核/多线程开发规范,利用OpenMP来提高计算速度。它的类名为pcl::NormalEstimationOMP,其接口100%兼容单线程的pcl::NormalEstimation。我们姑且一尝试一下。
【示例代码】
#include <time.h>
#include <cmath>
#include <functional>
#include <ros/ros.h>
#include <sensor_msgs/PointCloud2.h>
#include <pcl/console/time.h>
#include <pcl/kdtree/kdtree.h>
#include <pcl/features/normal_3d_omp.h>
#include <pcl_conversions/pcl_conversions.h>
int main(int argc, char** argv) {
ros::init(argc, argv, "n_lidar_openmp_normal");
ros::NodeHandle node;
pcl::NormalEstimationOMP<pcl::PointXYZ,pcl::Normal> normal_est;
normal_est.setNumberOfThreads(8); //设置OpenMP线程数
normal_est.setViewPoint(0,0,0); //设置视点,默认就是(0,0,0)
normal_est.setKSearch(10); //设置K近邻大小
pcl::PointCloud<pcl::PointXYZ>::Ptr cloud(new pcl::PointCloud<pcl::PointXYZ>);
const boost::function<void (const boost::shared_ptr<sensor_msgs::PointCloud2 const>&)> callback =[&](sensor_msgs::PointCloud2::ConstPtr msg_pc_ptr) {
pcl::fromROSMsg(*msg_pc_ptr, *cloud);
typename pcl::search::KdTree<pcl::PointXYZ>::Ptr kdtree_ptr(new pcl::search::KdTree<pcl::PointXYZ>);
pcl::PointCloud<pcl::Normal>::Ptr normal_ptr(new pcl::PointCloud<pcl::Normal>);
clock_t t1,t2;
t1 = clock();
normal_est.setInputCloud(cloud);
normal_est.setSearchMethod(kdtree_ptr);
normal_est.compute(*normal_ptr);
t2 = clock();
auto cost_time = (float)((t2-t1)*1000/CLOCKS_PER_SEC);
printf("cloud size:%zu, cost time:%.2f ms\n", cloud->size(), cost_time);
};
ros::Subscriber pc_sub = node.subscribe<sensor_msgs::PointCloud2>("/BackLidar/lslidar_point_cloud", 1, callback);
ros::spin();
return 0;
}
【运行结果】
cloud size:34365, cost time:2043.00 ms
cloud size:17848, cost time:1125.00 ms
cloud size:21231, cost time:1285.00 ms
cloud size:32271, cost time:1956.00 ms
cloud size:46526, cost time:2723.00 ms
cloud size:43233, cost time:2541.00 ms
cloud size:19196, cost time:1156.00 ms
cloud size:20268, cost time:1254.00 ms
cloud size:20216, cost time:1258.00 ms
cloud size:47956, cost time:2834.00 ms
cloud size:19737, cost time:1246.00 ms
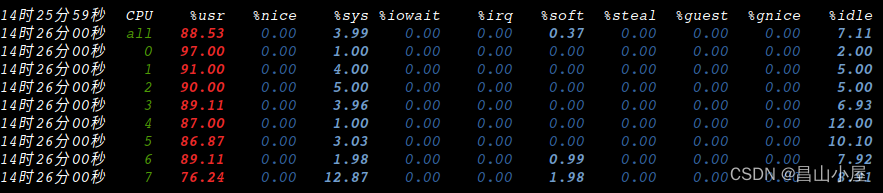
多核确实被利用起来了,但是单帧处理速度并没有明显的提速。问题出在哪里?















 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









