







当前,现有具身智能机器人数据集普通仍存在一些问题:感官模态单一、任务复杂度不足与标准化缺失等核心问题。
-
感官模态单一:过度依赖视觉模态,多模态融合缺失;触觉与力觉反馈数据严重不足,触觉是机器人精细操作的关键,但现有数据集普遍缺乏此类信息。
-
任务复杂度不足:多数数据集聚焦于单一场景下的简单动作,如抓取、放置、推物等基础操作,这类任务通常只需单次决策或短程操作,缺乏对复杂逻辑推理、多步骤协作、目标关联任务的覆盖。
-
标准化缺失:包括数据格式不统一、评估指标不一致、任务定义模糊、标注方式差异等,严重制约了跨场景、跨任务、跨机器人形态的算法泛化能力。
然而,解决上述问题,构建高质量、大规模具身智能数据集仍是一项系统性的工程难题。
其一,真机数据收集需在物理环境中部署机器人执行任务,涉及高昂的时间成本与硬件资源消耗,尤其复杂交互场景(如接触力反馈采集)需精密传感器支持,进一步推高成本。
其二,现有数据集整合困难。首先,不同数据集在存储格式、标注粒度和元数据定义上缺乏统一标准,形成 “数据孤岛;其次,任务语义和物理环境参数缺乏标准化定义,导致跨数据集任务逻辑难以衔接。最后,数据集对特定硬件的强依赖形成技术壁垒,阻碍跨平台整合。只有通过标准化打破 “数据烟囱”,才能释放具身智能数据集的规模化效应。
面向未来,亟需学术界与工业界协同突破数据瓶颈,以支撑具身智能技术的跨越式发展。
短期目标:需聚焦多模态数据标准化框架的制定,推动触觉、音频、3D点云等异构数据的统一表征与高效融合。
长期目标:需构建超大规模仿真-现实联合数据集,通过高保真虚拟环境生成亿级跨任务、跨机器人形态的交互数据,并建立真实场景的镜像数据采集体系。
最终目标:通过构建"感知-决策-控制"全链路闭环的多模态数据集,驱动具身智能体实现从单一技能模仿到复杂任务自主泛化的能力跃迁,为通用具身智能基础大模型的研发奠定坚实的数据基础。
接下来,文章重点介绍5家(1家国外+4家国内)主流的具身智能开源数据集:Open X-Embodiment、RoboMIND、AgiBot World、RH20T和AIRO。

5家具身智能开源数据集基本情况梳理
一、Open X-Embodiment
1. 基础内容
数据集名称:Open X-Embodiment
发布时间:2023年10月
发布者:谷歌DeepMind联合斯坦福大学、上海交通大学、英伟达、纽约大学、哥伦比亚大学、东京大学、日本理化研究所、卡内基梅隆大学、苏黎世联邦理工学院、伦敦帝国理工学院等21个机构(34个实验室)。

数采机器人类型:涵盖单臂机器人、双臂机器人和四足机器人等22种不同类型的机器。
数据集规模:整合了60个已有数据集,涵盖311个场景、 100 多万条真实机器人轨迹,包括527种技能、160266项任务。
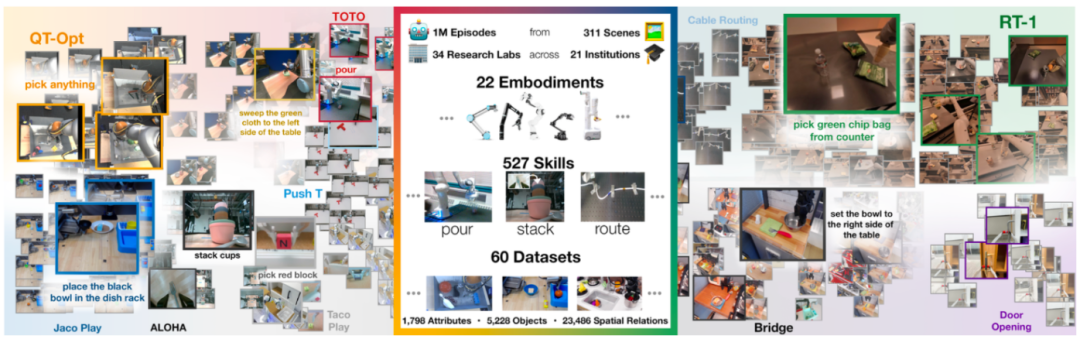
数据集格式:所有源数据集统一转化为RLDS格式,便于下载和使用。
-
该格式能够适应不同机器人设置的各种动作空间和输入模态,比如不同数量的 RGB 相机、深度相机(RGB-D相机)和点云数据。
-
支持在所有主流深度学习框架中进行高效的并行数据加载。
2. 数据集分布情况
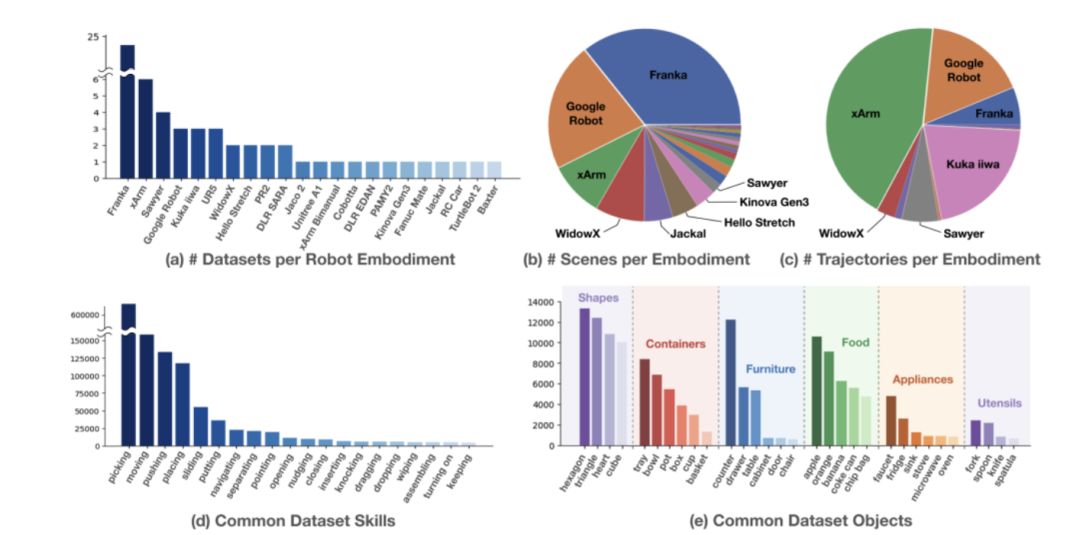
1)数采机器人类型:数据集中涉及到的机器人包括单臂、双臂和四足机器人,图 (a) 展示了 22 种类型机器人数据集的分布情况,其中,Franka、xArm和Sawyer机器人占多数。
2)场景分布:图 (b) 展示了机器人在不同场景的分布情况,Franka机器人占据主导地位,其次是Google Robot和xArm。
3)轨迹分布:图 (c) 则展示了每个形态机器人的轨迹分布情况,xArm轨迹数量占比最高,其次是Google Robot、Franka、 Kuka iiwa 、Sawyer和WidowX。
4)技能分布:由图(d)可以看出,技能上主要集中在Picking(抓)、Moving(移动)、Pushing(推)、Placing(放)等基础技能,整体呈现长尾分布。尾部分布有Wiping、Assembling、Turning on等更高难度的技能。
5)物品类型,图 (e) 展示了机器人所用的物品,包括家用电器、食品和餐具等多种类型物品。
3. 数据集测试验证
1)模型选择:RT1和 RT2
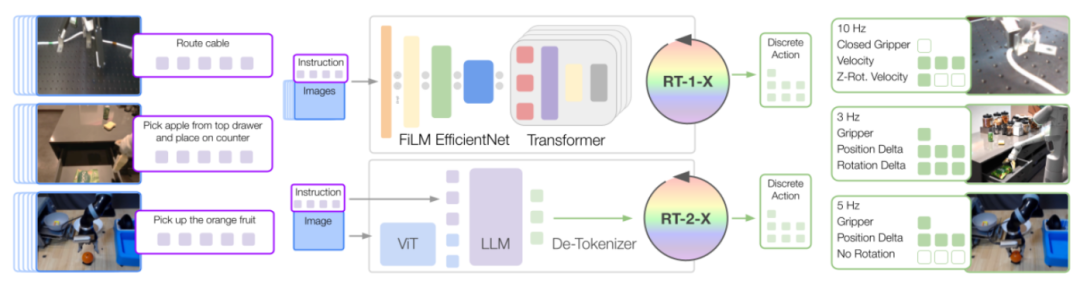
a. RT-1 是一个基于 Transformer 架构的 3500 万参数网络,专为机器人控制设计。其输入包含 15 帧历史图像 和 自然语言指令。
每帧图像通过 ImageNet 预训练的 EfficientNet提取视觉特征,自然语言指令则通过 Universal Sentence Encoder (USE)转换为嵌入向量。
视觉与语言表征通过 FiLM 层(Feature-wise Linear Modulation)融合,生成 81 个视觉-语言联合表征令牌(vision-language tokens)。这些令牌随后输入到仅含解码器的 Transformer 架构 中,最终输出离散化的动作令牌(tokenized actions)。
b. RT-2 是一个基于大规模互联网视觉-语言数据和机器人控制数据训练的视觉-语言-动作模型(Vision-Language-Action Models, VLAs)。
RT-2 将离散化的动作编码为文本形式的符号(token),例如,一个动作可能表示为“1 128 91 241 5 101 127”。通过这种方式,任何预训练的视觉语言模型(Vision-Language Models, VLM )均可通过微调适配机器人控制任务,从而继承其主干网络的表征能力,并迁移其部分泛化特性。
在论文中,重点研究 RT-2-PaLI-X 变体,其主干网络由视觉模型 ViT(Vision Transformer)和语言模型 UL2构成,并基于 WebLI数据集(覆盖互联网多模态数据)进行了大规模预训练。
2) 训练数据使用
所使用数据集:实验中使用的混合数据来自9种机械臂的采集数据,共12个子数据集。
12个数据集包括:RT-1、QT-Opt、Bridge、Task Agnostic Robot Play、Jaco Play、Cable Routing、RoboTurk、NYU VINN、Austin VIOLA、Berkeley Autolab UR5、TOTO和Language Table。
备注:在训练RT-1-X 和 RT-2-X 时,并未使用 Open X-Embodiment 的全部数据。数据仅涵盖了 22 个机械臂中的 9 个,以及 60 组子数据集中的 12 组,总计 1,131,788 条数据。作者在论文中解释,这是因为数据集处于持续增长状态,在开展 RT-X 相关实验时,这 12 组数据即为当时数据集的全部内容。
其中,RT-1-X仅使用上述机器人数据混合集进行训练;RT-2-X采用与原 RT-2类似的联合微调(co-fine-tuning)策略,以约 1:1 的比例混合原始视觉语言模型(VLM)数据与机器人数据。
在推理阶段,每个模型均以机器人所需的运行速率(3-10赫兹)执行:RT-1在本地运行,而RT-2托管于云服务并通过网络请求调用。这种部署方式确保了不同架构模型的运行效率需求都能得到满足。
数据格式统一:由于不同机器人的观测空间和动作空间差异显著。因此,在使用时,将其粗略对齐:
-
输入:一段窗口历史图像(统一分辨率)和自然语言指令(language embedding with USE);
-
输出:7维末端执行器动作离散量(6D for EE: x, y, z, roll, pitch, yaw and 1D for gripper)外加对轨迹状态的说明(terminate_episode)。
3)实验验证过程
a. 跨具身的分布内性能评估
“分布内性能”指模型在训练数据分布范围内(即已见过的任务或场景)的表现。目的在于通过测试模型在分布内任务上的表现,可判断模型是否成功整合了多源异构数据的能力。
实验设计
通过对比小规模数据集领域与大规模数据集领域,期望能够验证两个假设:
-
小规模数据领域,跨数据集迁移学习(如利用其他机器人的大规模数据)可以显著提升模型性能;
-
大规模数据的领域,模型性能可能接近瓶颈,改进空间有限。
其中,小规模数据集评估选用:Kitchen Manipulation、Cable Routing、NYU Door Opening、AUTOLab UR5和Robot Play 共5个数据集。并且,在评估测试时,仅对比RT-1-X模型性能;
大规模数据集评估选用:Bridge数据集(对应WidowX机器人)和RT-1数据集(对应Google Robot)。并且,在评估测试时,同时评估RT-1-X与RT-2-X模型。
备注:所有模型均通过全量X-具身数据集进行协同训练。
另外,实验中设置双重基线(基准)对比:
-
原生方法模型:由数据集创建者开发的专用模型,仅使用对应数据集训练。
-
独立训练RT-1:仅使用目标数据集单独训练的RT-1模型。
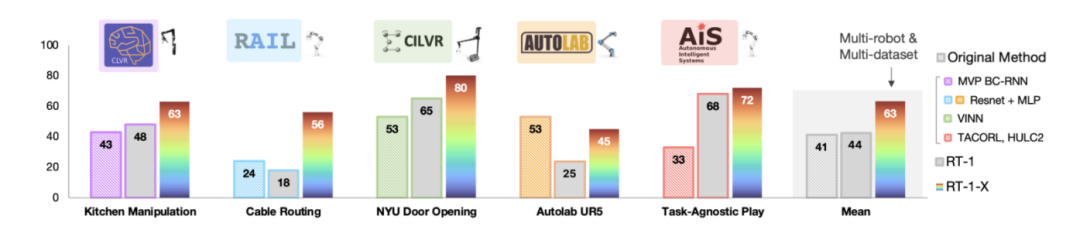
实验结果显示
-
小规模数据集:如下图所示,RT-1-X模型在5个数据集中的4个上表现优于仅使用单一数据集训练的基准模型。RT-1-X的平均成功率比原始方法或RT-1高出50%。由于RT-1与RT-1-X具有相同的网络架构,这表明RT-1-X性能的提升可归因于对机器人数据混合集的联合训练。
-
大规模数据集:如下表所示,在大规模数据场景,RT-1-X未能超越仅使用特定具身数据集训练的RT-1基线,表明该模型类别存在欠拟合问题。然而,在Bridge数据集,斯坦福的IRIS评估中,RT-2-X(55B)模型同时超越了原生方法模型和RT-1。这在一定程度上说明,对于具有足够参数规模的模型来讲,通过混合数据的训练,虽然改进空间有限,但仍然在能够提升模型性能。
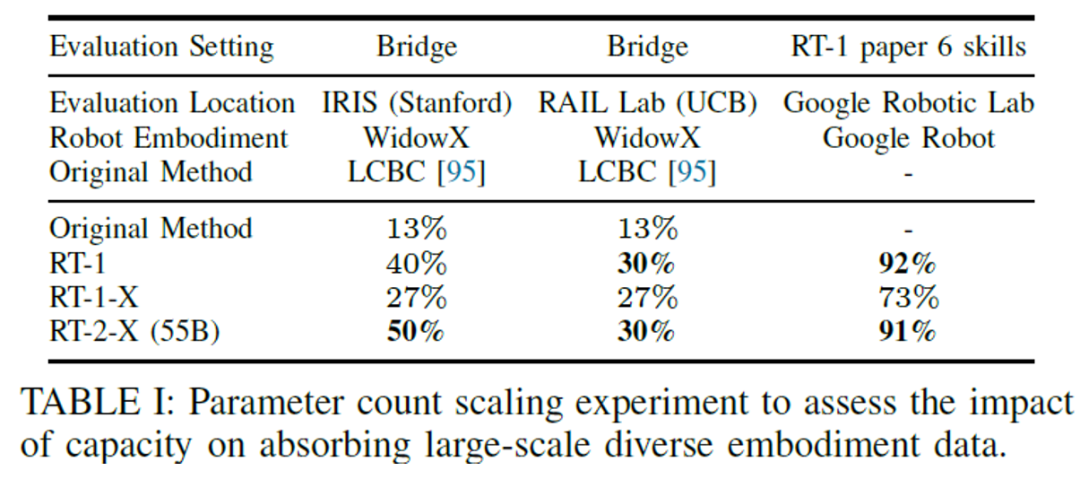
b. 分布外场景泛化能力的提升
实验目的:为了探究跨具身训练(融合多机器人数据)如何增强模型在分布外场景及复杂新指令下的泛化性能。
实验设计:本组实验聚焦大规模数据集领域,采用RT-2-X模型。主要测试内容包括:未见物体/背景/环境下的泛化测试、跨平台技能涌现评估和Bridge数据集消融实验。
实验结果:

备注:消融实验揭示设计决策对泛化能力(未见物体/背景/环境)与跨数据集技能涌现(Google Robot平台)的影响,验证网络预训练、模型参数规模及历史观测的关键作用。
—— 未见物体/背景/环境泛化测试
测试模型在全新环境、背景中操作未见物体的能力。实验结果显示,RT-2与RT-2-X表现基本持平(表II第1-2行末列),该结果符合预期,因RT-2凭借视觉语言模型(VLM)主干网络已在此类维度展现优异泛化性。
—— 跨平台技能涌现评估
为验证跨机器人知识迁移,我们在Google Robot平台执行如下图所示任务。这些任务涉及RT-2数据集中未包含、但存在于WidowX机器人Bridge数据集中的物体与技能。表II"技能涌现评估"列显示:对比第1-2行,RT-2-X较RT-2性能提升约3倍,表明即使对于已有海量数据的机器人,整合其他平台训练数据仍可拓展其任务执行范围。实验结果证实,跨平台协同训练使RT-2-X控制器获得该平台原始数据集之外的附加技能。

备注:该图为评估跨具身迁移能力,研究者在Google Robot平台测试RT-2-X对Bridge数据集独有技能(非Google Robot原生数据集内容)的掌握情况。
—— Bridge数据集消融实验
从RT-2-X训练集中移除Bridge数据(第3行),结果显示保留任务性能显著下降,证实WidowX数据迁移是RT-2-X在Google Robot上获得新技能的关键因素。
c. 架构设计影响分析
通过消融实验量化不同设计决策对RT-2-X泛化能力的影响。关键发现包括:
-
历史观测信息:引入短期图像历史可显著提升泛化性能(第4 vs 5行);
-
网络预训练:基于网络数据的预训练对大型模型性能至关重要(第4 vs 6行);
-
模型参数规模:55B模型较5B模型在技能涌现评估中成功率显著更高(第2 vs 4行);证明更大参数规模的模型能够促进跨机器人数据迁移;
-
微调策略:协同微调与独立微调在泛化与技能涌现评估中表现相当(第4 vs 7行),归因于RT-2-X使用的机器人数据多样性远超以往历史数据集。
参考网址
-
论文链接:https://arxiv.org/pdf/2310.08864v8
-
项目主页 :https://robotics-transformer-x.github.io/
二、RoboMIND
1. 基础信息
数据集名称:RoboMIND
发布时间:2024年12月
发布方:国家地方共建具身智能机器人创新中心与北京大学计算机学院联合发布
数采机器人:单臂机器人(Franka Emika Panda 、UR5e )、双臂机器人(AgileX Cobot Magic V2.0 ) 和 人 形 机 器 人 (天工 ,配备5指灵巧双手)
数据集规模:包含10.7万条机器人轨迹(任务成功的轨迹),涵盖479种任务、96种物体类别和38种操作技能;

另外,数据集中还包括机器人做任务失败案例(包括人类操作者的原因导致执行失败的案例和机器人本身原因导致执行失败案例)中的5000条轨迹,每个失败案例都附有详细的故障原因。通过分析失败案例,不仅能够改进模型,反过来还能指导改进数据采集方法,提高数据质量。
2. 数据集特点
1)数采机器人形态多样化
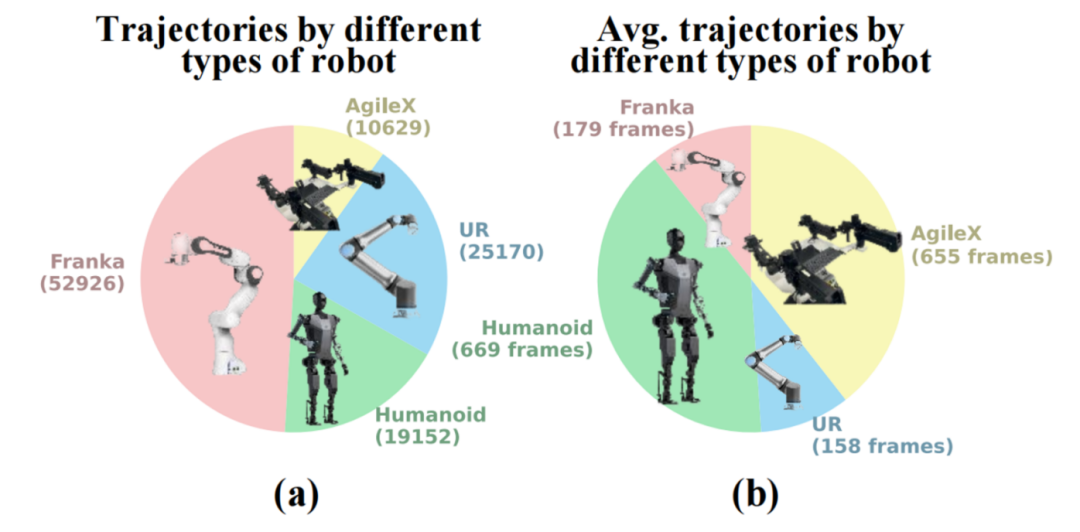
在RoboMIND数据集中,不同类型机器人的所采集的数据轨迹占比如下:
基于单臂机器人Franka Emika Panda的数据轨迹有52926条,占比将近50%,其中,分别为超过26,070条基于数字孪生环境的模拟轨迹和26,856条通过人类遥操作收集的真实场景轨迹。
基于拥有灵巧双手的人形机器人“天工”采集的数据轨迹有19152条,占比为17.8%,该数据用于支持人类复杂操作技能的训练。
基于双臂机器人AgileX Cobot Magic V2.0的数据轨迹有25170条,占比为23.3%,该数据用于支持协调技能和更长期任务的训练。
基于单臂机器人UR5e的数据轨迹有10629条,占比为9.9%。(参看下图a)
2)任务长度多样化
Franka Emika Panda机器人平均轨迹长度为179帧;UR5e机器人平均轨迹长度为158帧。这两款单臂机器人执行任务的轨迹相对较短(少于200个时间步),适合用于训练基础技能。相比之下,人形机器人“天工”(平均轨迹长度为669帧)和双臂机器人AgileX Cobot Magic V2.0(平均轨迹长度为655帧)执行任务的轨迹相对较长(超过500个时间步),更适合用于长时间跨度的任务训练以及技能组合。(不同形态机器人的平均轨迹长度可参看下图b)
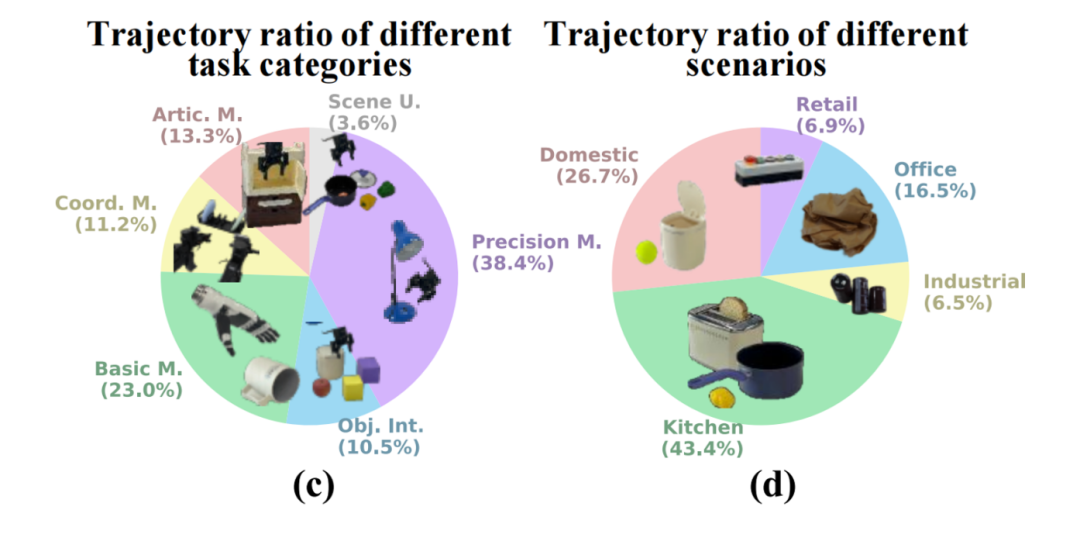
3)任务类型多样性
根据任务的语言描述,综合考虑动作、对象和和轨迹范围等因素,将整个数据集中的任务类型分为六大类:
-
铰链式操作(Artic. M. - Articulated Manipulations ):开关抽屉、门,转动物体等。
-
协调操作(Coord. M. - Coordination Manipulations):这里主要指双臂机器人的协同。
-
基础操作(Basic M. - Basic Manipulations):抓、握、提、放等最基本的操作。
-
多物体交互(Obj. Int.- Multiple Object Interactions):比如推一个物体撞另一个物体。
-
精密操作(Precision M. - Precision Manipulations):比如倒水、穿针引线等需要精确控制的操作。
-
场景理解(Scene U. - Scene Understanding):比如从特定位置关门,或者把不同颜色的积木放到对应颜色的盒子里。
在这6大类型任务中,精密操作型任务占比最高,达38.4%;基础操作型任务紧随其后,占比23.0%;而场景理解型任务占比最少,仅为3.6% 。通过细致的分类,研究人员将整个数据集划分成479项具体的任务,涵盖了从简单到复杂,从短时到长时的各种操作。(不同任务类型占比可参看下图c)
4)物品类别多样性
RoboMIND数据集包含了厨房、家庭、零售、办公室以及工业五大场景里面96种不同的物品类别。其中,厨房场景下采集的数据轨迹占比最高,达到43.4%;家庭场景次之,轨迹占比为26.7%;零售场景的轨迹占比最少,为6.9%。多样化的物体种类增加了数据集的复杂性,有助于训练模型在各种环境下执行操作的通用操控策略。(不同场景下的数采轨迹占比可参看下图d)
3. 数据集实验验证
RoboMIND数据集实验验证分为基于单任务模仿学习模型的评估和基于VLA视觉语言动作模型的评估两类。
-
对于单任务模仿学习模型,通过ACT、Diffusion Policy和 BAKU三种主流的模仿学习算法来评估任务的成功率。
-
对于VLA视觉语言动作模型,通过评估OpenVLA、RDT-1B 和CrossFormer三种主流的VLA模型的泛化能力和任务成功率。
1)单任务模仿学习模型
在实现任务设计上,Franka、Tien Kung、AgileX和UR5e分别执行15个、10个、15个和5个任务,共45个任务,既有简单任务,也有复杂任务。
在模型选择上,选用了ACT 、Diffusion Policy和BAKU 三种常用的模仿学习算法。首先,为每个数据集从头开始训练单任务模型。然后,待模型训练完成后,将其直接部署到实际环境中进行评估。最后,通过任务的成功率来评估每个模型的性能。
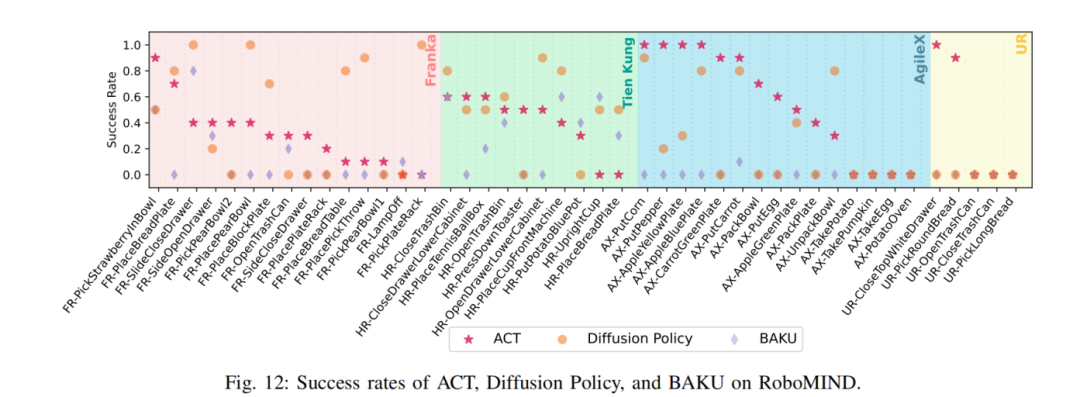
实验结果显示:
-
ACT在AgileX的15项任务中的表现最好,平均成功率达到了55.3%。优于 Franka(30.7%)、UR5e(38.0%) 和 天工(34.0%)。
-
Diffusion Policy也展示了其学习复杂任务的能力,在Franka和天工的多个任务中超越了ACT。然而,BAKU在大多数任务中的成功率较低。
整体来看,RoboMIND数据集对于提升单任务模仿学习模型的性能具有比较明显的效果。
2)VLA视觉动作语言模型
在实现任务设计上,从上面提到的单任务模仿学习实验中挑选了15个由不同类型机器人完成的任务。
在机器人选择上,选择单臂机器人Franka、人形机器人天工、双臂机器人AgileX进行评估试验。
-
单臂机器人Franka :选择评估的任务包括常见抓取和放置、推拉基础操作任务,以及需要精确操控的更细致的任务,例如抓取不同大小的物体和准确地定位机械臂以打开垃圾桶盖等。
-
人形机器人“天工”:选择评估的任务包括两类,一类与Franka选择的任务相似,旨在评估模型在不同类型机器人上的表现。第二类涉及使用人形机器人的灵巧双手执行精确操作,例如翻转烤面包机的开关来烘烤面包,以评估模型在定位和操控方面的准确性。
-
双臂机器人AgileX:需要协调动作的双臂任务,如左臂从架子上取下盘子,右臂将苹果放在盘子上。
在模型选择上,选择OpenVLA、RDT-1B 和CrossFormer 这三种比较主流的VLA模型进行评估。实验采用官方预训练的VLA模型,在上述所选择的3种类型的机器人上对模型进行多任务数据集的微调,并通过为每个任务进行10次试验来评估它们在每个单独任务上的性能,以确定所实现的泛化程度。
对于OpenVLA模型,仅在Franka单臂机器人上进行了测试。对于RDT-1B和CrossFormer模型,在3种类型的机器人上均进行了测试。
参考网址
-
论文链接:https://arxiv.org/pdf/2412.13877.pdf
-
项目主页:https://x-humanoid-robomind.github.io/
三、AgiBot World
1. 基础信息
数据集名称:AgiBot World
发布时间:2024年12月
发布方:智元机器人联合上海人工智能实验室、国家地方共建人形机器人创新中心以及上海库帕思
数采机器人:100个同构型的机器人(专业数采本体Genie-1),该机器人配备6自由度灵巧手,全身拥有32个主动自由度;安装了8个环绕式布局的摄像头,可实现360°全方位环境感知;手臂自由度为7,最大单臂负载为5kg;同时末端增加了六维力传感器和触觉传感器,能够感知到微小力变化。
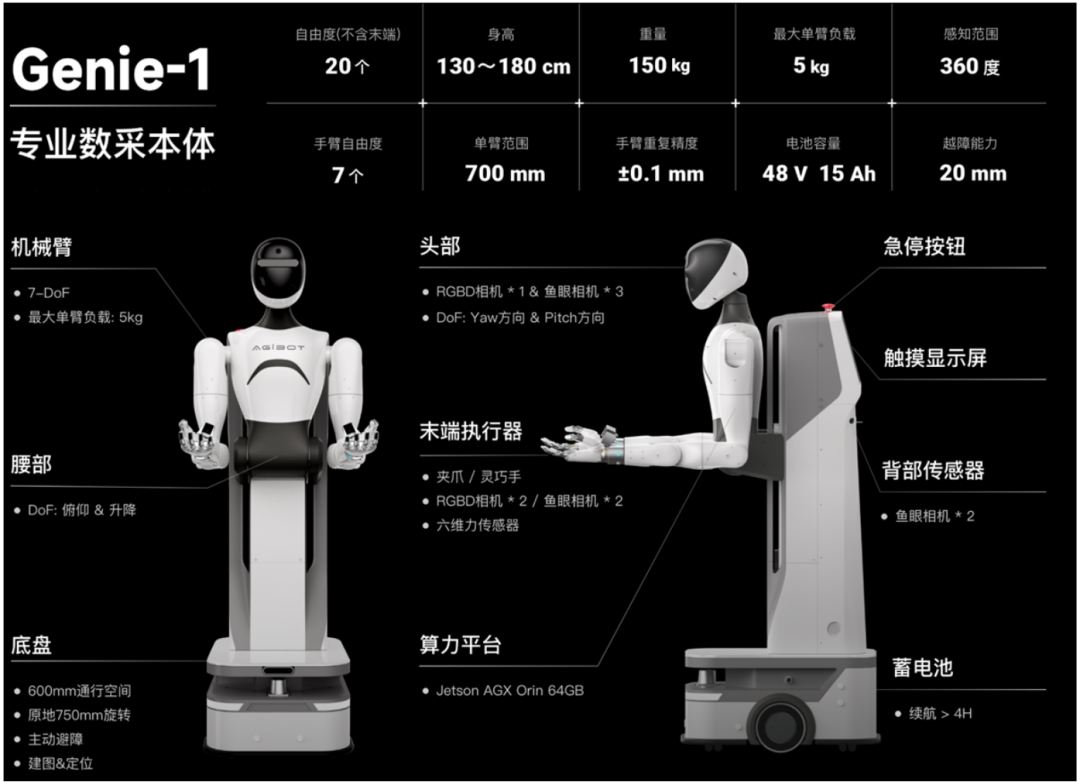
智元机器人专业数采本体:Genie-1(图片来源:AgiBot World项目主页)
数据采集遥操设备:全身动捕套装+ VR

数据集遥操设备(图片来源:AgiBot World项目主页)
数据集规模:超过百万级真机数据,涵盖5大领域中的100 余种真实场景、80余种技能、3000多种物品。从基础的抓取、放置、推、拉等操作,到搅拌、折叠、熨烫等精细长程、双臂协同复杂交互,几乎涵盖了日常生活所需的绝大多数动作需求。其中,80%的任务为长程任务,时长集中在60s-150s之间,且涵盖多个原子技能。
2. 数据集分布
1)真实场景数据分布
AgiBot World真机数据集诞生于智元自建的大规模数据采集工厂与应用实验基地,空间总面积超过 4000 平方米,包含 3000 多种真实物品,复刻了家居、餐饮、工业、商超和办公五大核心场景,数据集中涵盖的场景具备多样化和多元化特点,从抓取、放置、推、拉等基础操作,到搅拌、折叠、熨烫等复杂动作。
其中,家居场景数据占比最高,为40%;餐饮场景和工业场景次之,均为20%;剩下的办公室场景和超市场景各占10%。
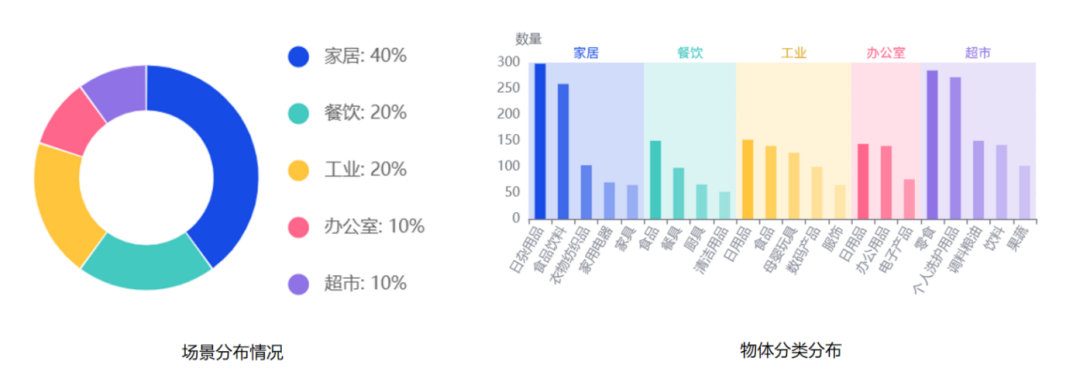
数据集场景分布和物体分类分布情况(图片来源:AgiBot World项目主页)
2)仿真场景数据分布
2025年2月,智元机器宣布推出自主研发的大型仿真框架——AgiBot Digital World,同时开源上线仿真数据集 —— AgiBot Digital World Dateset,涵盖5大类场景、180+品类具体物品、9种常见材质、12种核心技能。
仿真数据集涵盖家居、商超、办公、餐饮和工业五大类型场景。其中,家居场景仿真数据最为丰富,占36%的比重,商超场景紧随其后,占比为21%,其他三类场景(餐饮、工业和办公室)各占14.3%。
仿真场景包含超过180种具体物品,材质方面包括木质、地毯、石制等9种主要材料。在技能方面,仿真数据集整合了12种核心操作技能。从最基础的抓取、放置,到更复杂的插入、倾倒等动作。
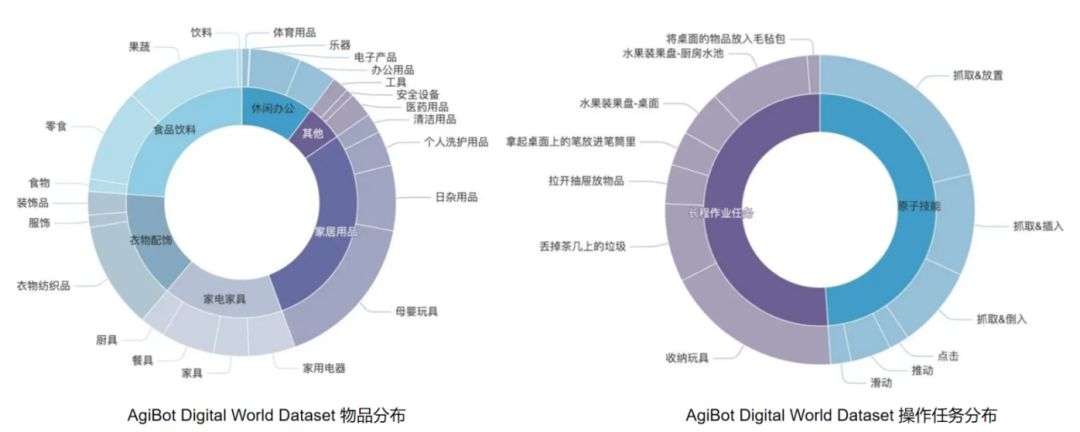
AgiBot Digital World Dateset物品分布和操作任务分布情况(图片来源:智元机器人官网)
参考网址
-
论文链接:https://arxiv.org/pdf/2503.06669
-
项目主页:https://agibot-world.com/
-
真机数据开源地址:
https://opendatalab.com/OpenDriveLab/AgiBot-World/
-
仿真数据开源地址:https://huggingface.co/datasets/agibotworld/AgiBotDigitalWorld
四、RH20T
1. 基础信息
数据集名称: RH20T
发布时间:2023.07
发布方:上海交通大学
开源目标:构建大规模、多样化、多模态的机器人操作数据集,推动复杂技能的一步模仿学习与基础模型研究。
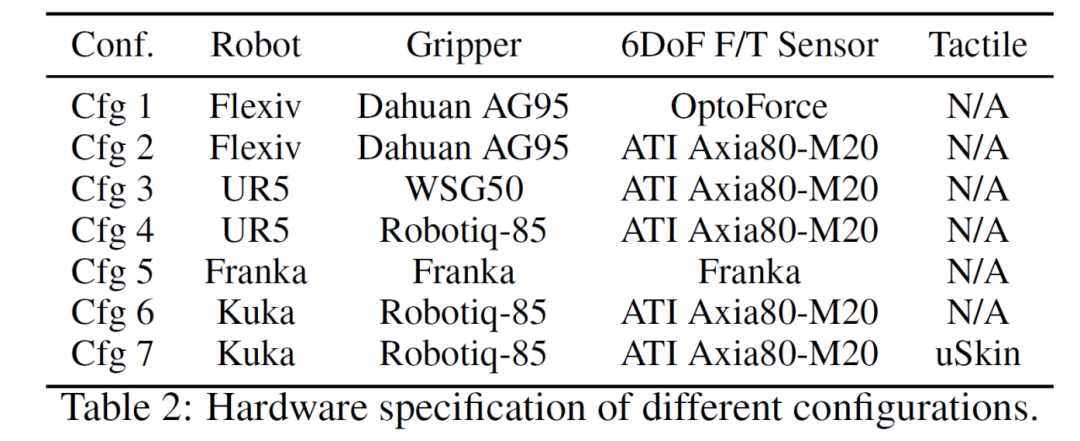
数采机器人:使用4种主流机械臂(UR5、Franka、Kuka和Flexiv)、4种夹爪(Dahuan AG95、WSG50、Robotiq-85和Franka)、3种力传感器(OptoForce 、ATI Axia80-M20和Franka),共7种机器人硬件配置组合。
备注:Franka机器人的本体、夹爪和力传感器均为思灵机器人自研产品。
数据集规模:数据集总数据量达20TB,包含超 11 万个高接触度机器人操作序列与等量的11万个人类演示视频,共计超 5000 万帧图像。该数据集包含视觉、触觉、音频等多模态信息,覆盖147种任务(如切割、折叠、旋转等接触密集型操作)与42种技能(涵盖抓取、放置、装配等技能),从日常基础操作到复杂技能均有涉及。平均每项技能包括 750 次机器人操作,为机器人学习与技能优化提供了丰富的实践样本。

备注:147 项任务中,70 个由研究人员自主提出,均为常见且可实现的任务;另外77个则从 RLBench(48个)和 MetaWorld(29个)中选取而来。
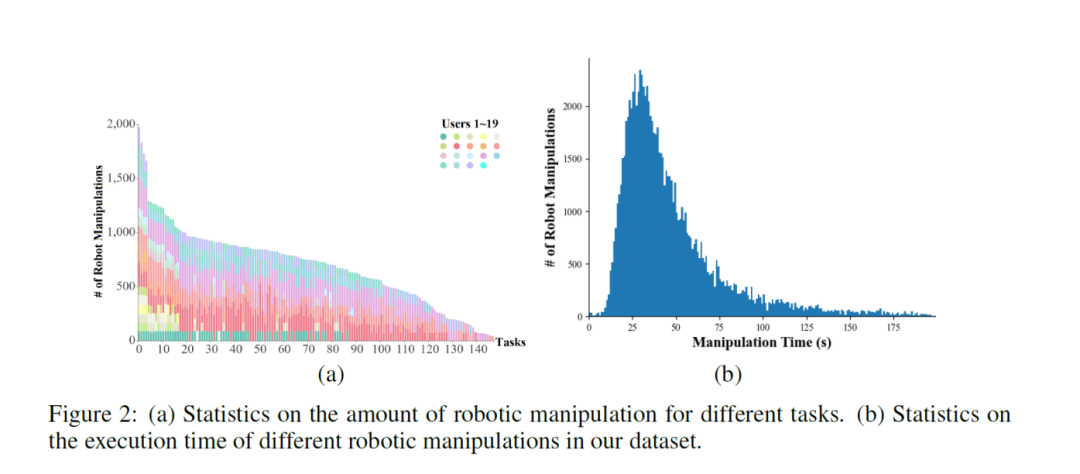
图2(a)展示了数据集中不同任务的操作数量分布,呈现相对均匀的分布特征。
图2(b)展示了数据集中每条序列的操作时间统计,多数序列时长为10至100秒。
2. 数据采集与处理
1)数据采集装置:每个平台包含1个带力矩传感器的机械臂、夹爪、1-2个夹爪内置摄像头、8-10个全局摄像头、2个麦克风、触觉设备、踏板及数据采集工作站。
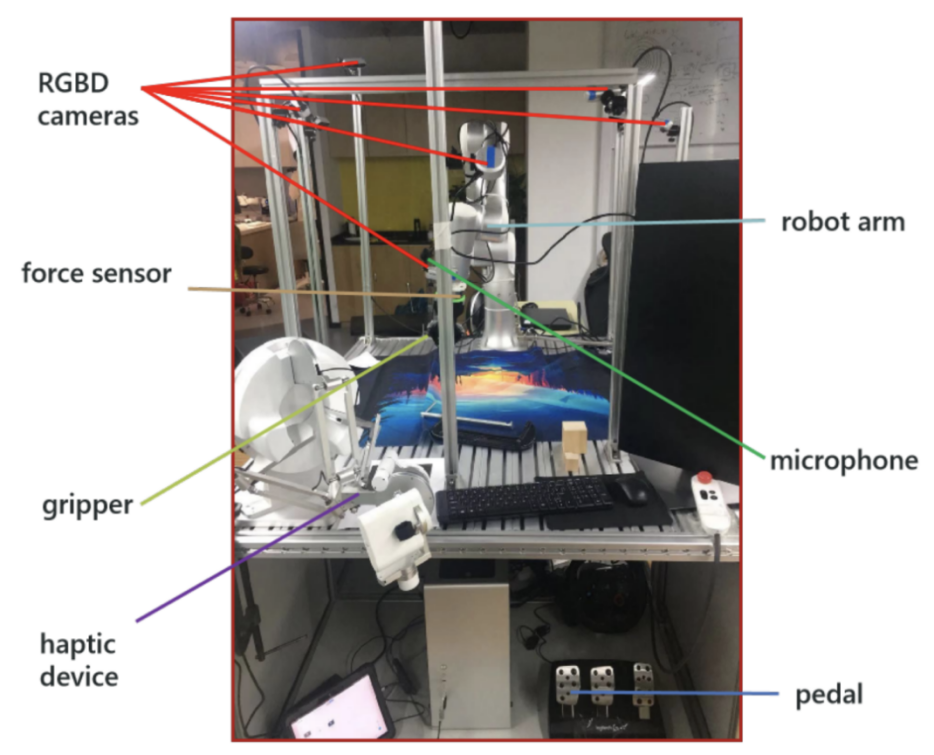
数据集采集平台
2)数据处理:对数据集进行了预处理,以提供统一的数据接口。首先,将所有机器人与力传感器的坐标系对齐,并对不同力传感器进行精准调零。随后,将末端执行器的笛卡尔位姿和力扭矩数据转换至各摄像头的坐标系中。另外,为确保相机校准质量,研究人员对每个场景进行了人工验证。
3. 数据集特点
1)多模态数据
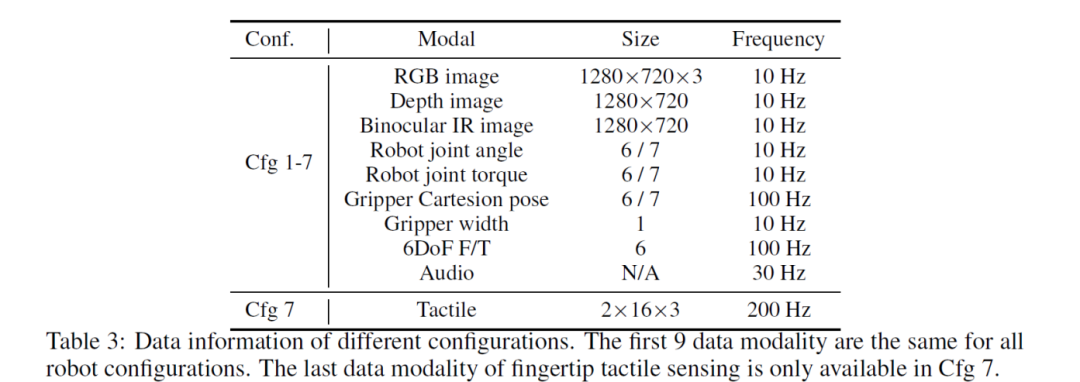
该数据集涵盖视觉、触觉、音频以及本体感知等多模态信息。
-
视觉信息:RGB图像、深度图像及双目红外图像三种相机的视觉信息;
-
触觉信息:提供机器人腕部的六自由度力/扭矩测量,部分序列还包含指尖触觉信息;
-
音频信息:包括夹爪内部与全局环境的声音记录;
-
本体感知信息:涵盖关节角度/扭矩、末端执行器的笛卡尔位姿及夹爪状态。
2)树状层级结构组织
结构组织原则:数据集以任务内部相似性为基础构建树状结构,节点层级反映任务的抽象程度。如下图所示,根节点代表最广泛的任务类别,随着层级下移,节点逐渐细分到具体任务。叶子节点代表最细粒度的任务实例,具有最近共同祖先的叶子节点在语义和执行方式上更相似。
例如:根节点代表最高层级的任务分类,如“插拔操作” 这类任务大类;中间节点则依据任务间的相似性逐层细分,例如从 “插拔插座” 进一步细化为 “插拔 USB 设备”;叶节点作为最底层,对应具体的任务实例,像将 “插拔 USB 设备” 再次细分为 “插拔 USB Type-C 设备” 。
每个任务通过组合不同层级的叶子节点生成数百万个<人类演示,机器人操作> 数据对。例如,两个叶子节点若在较高层级共享共同祖先,其配对数据可体现任务间的泛化性;而低层级的配对则聚焦具体细节。
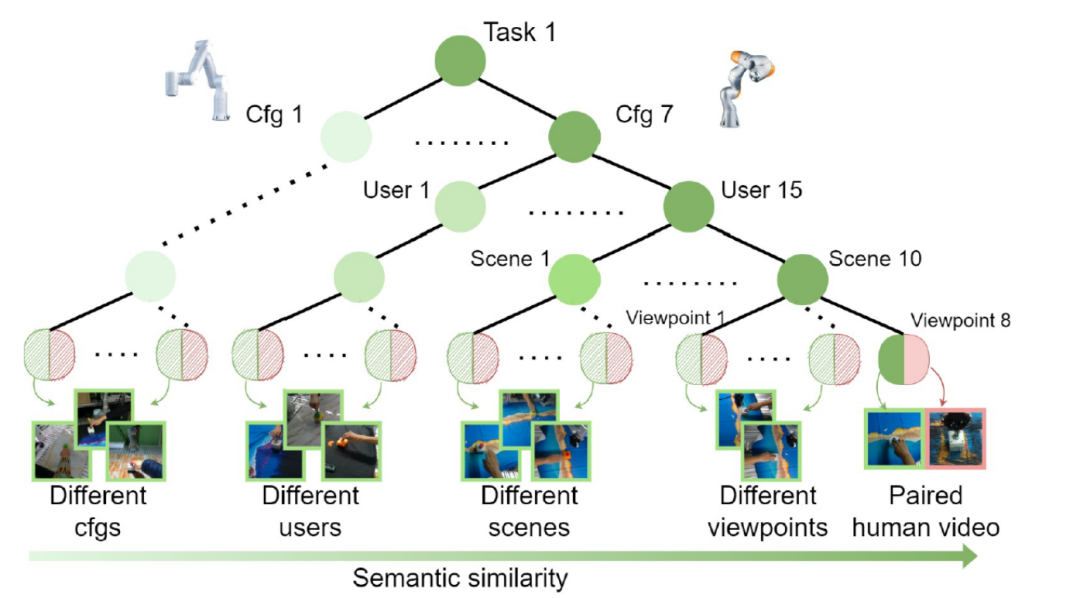
数据集树状结构示例
3)机器人操作数据与人类演示视频数据配对
RH20T数据集通过树状结构组织之间的任务相似性,并利用跨层级叶节点配对构建密集的多样化数据对,旨在解决机器人操作中视角、场景、硬件差异带来的泛化挑战。这种设计为训练通用型机器人基础模型提供了结构化支持。
-
多模态配对:一个机器人操作序列(红色叶节点)可与多个不同视角、场景、操作者的人类示范视频(绿色叶节点)配对。
-
跨层级配对:通过选择不同层级的共同祖先,可生成数百万对<人类示范,机器人操作>数据。共同祖先越近,叶节点关联性越强(例如“插拔USB-A”与“插拔USB-C”比“插拔插座”更相似)。
另外,研究人员为每个机器人操作序列提供相应的人类演示视频和语言描述,以增强任务语义理解。
参考网址
-
论文链接:https://arxiv.org/abs/2307.00595
-
项目主页:https://rh20t.github.io/
-
数据集:https://rh20t.github.io/#download
五、ARIO(All Robots In One)
1. 基础内容
数据集名称:ARIO(All Robots In One)
发布时间:2024年8月
发布方:鹏城实验室与松灵机器人、南方科技大学、中山大学联合发布
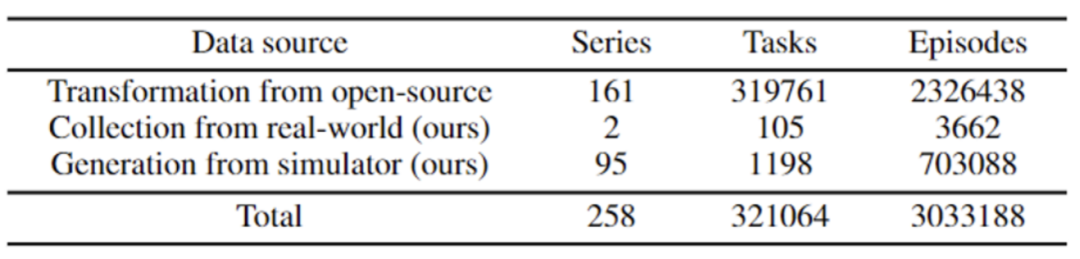
数据集规模:共有258 个场景系列(Series),321064 个任务(tasks),3033188个轨迹片段(Episodes)。这些数据来自3种方式:真实世界采集 +仿真模拟生成+开源数据集转换。
场景统计:如下图(a)所示,主要场景系列包括桌面场景(165个系列)和多种室内场景(如开放区域、多房间、客厅和厨房,共213个系列);任务数量较多的场景主要集中在桌面、厨房、家庭环境、走廊及多房间场景。轨迹片段数量较多场景主要集中在桌面、多房间、厨房、家庭环境(Households)和走廊,其中桌面场景轨迹片段数量最多,达到212.7万条。
图(b)展示了ARIO数据集中每种技能对应的系列数量、任务数量及轨迹片段数量。
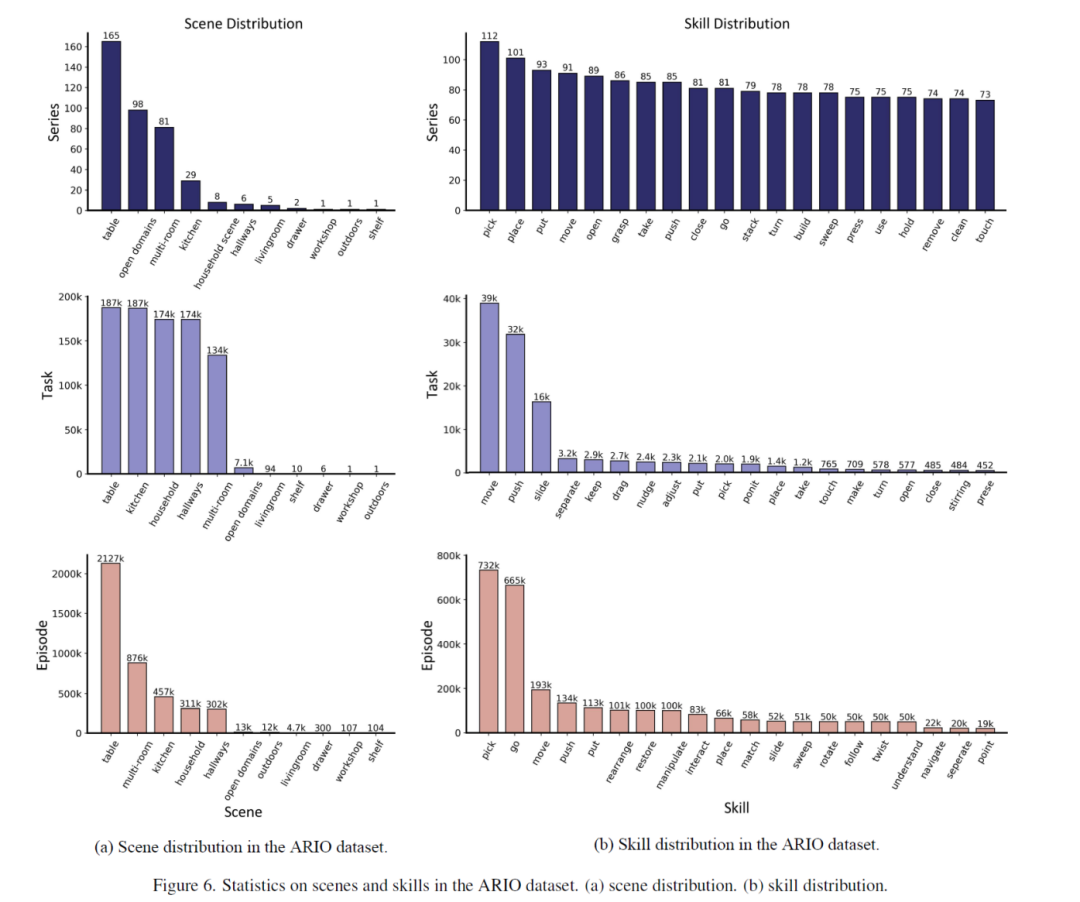
机器人参数统计:数据集统计了各种机器人相关参数,包括机器人形态(如单臂、AGV、轮式、双臂、仿人机器人)、机器人运动对象(如末端执行器、关节和基座)、机器人物理变量(如旋转角度、位置、速度、力或力矩)以及传感器类型和安装位置等。
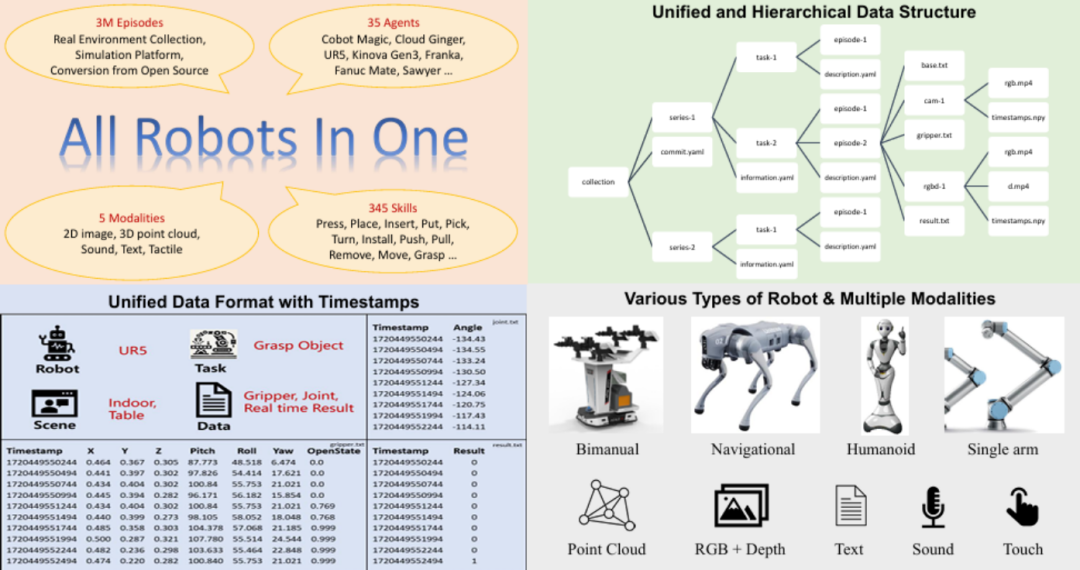
2. 数据集特点
1)多种感官模态:支持五种感官模态 —— 图像、点云、声音、文本和触觉,旨在提供更丰富和多样化的数据,以增强机器人的感知和交互能力。
2)基于时间戳的对齐机制:基于时间戳实现多传感器数据同步记录,兼容不同采样频率,以确保多模态数据的同步。具体来说,相机数据以30Hz的频率记录,激光雷达数据以10Hz记录,本体感知数据以200Hz记录,触觉数据以100Hz记录。
3)层级化数据架构:数据集采用场景系列(Series)- 任务(Tasks)- 片段(Episodes)的层次结构。Series是指同一个场景和同一个机器人采集的系列数据,如人形机器人在工厂车间采集的系列数据,可能包含不同的任务;Task是一个具体的任务,比如搬运货物,同一个任务可以重复采集多次,Episode是针对某一具体任务的一次完整采集过程。
4)标准化数据格式:统一数据结构,支持多种机器人形态(如单臂、双臂、仿人、四足、移动机器人)及操控对象,简化数据处理。
5)仿真与真实数据集成:数据集涵盖多任务、多场景及多机器人类型的仿真合成数据与真实场景采集数据,有助于提升算法模型跨硬件平台的泛化能力。
3. 数据集数据来源
ARIO数据来源:真实场景数据采集+仿真模拟生成+开源数据集转换。
-
真实场景数据采集:通过布置真实环境下的场景和任务进行真机数据采集,共采集了2个场景序列、105个任务、3662个轨迹片段(Episodes),在3种方式里面占比最少,大约为0.8%。
-
仿真模拟生成:基于MuJoCo、Habitat、SeaWave 等仿真引擎,设计虚拟场景和3D物体模型,完成任务仿真的采样与保存。采用该方式共生成95个场景序列、1198个任务、703088个轨迹片段,数据量占比为36.8%。
-
开源数据集转换:选择了3个开源的具身数据集,将其转换为符合ARIO 格式标准的数据。通过该方式获取的数据量最多,占比为62.4%,共转换成功有161个场景序列、319761个任务、2326438个轨迹片段。
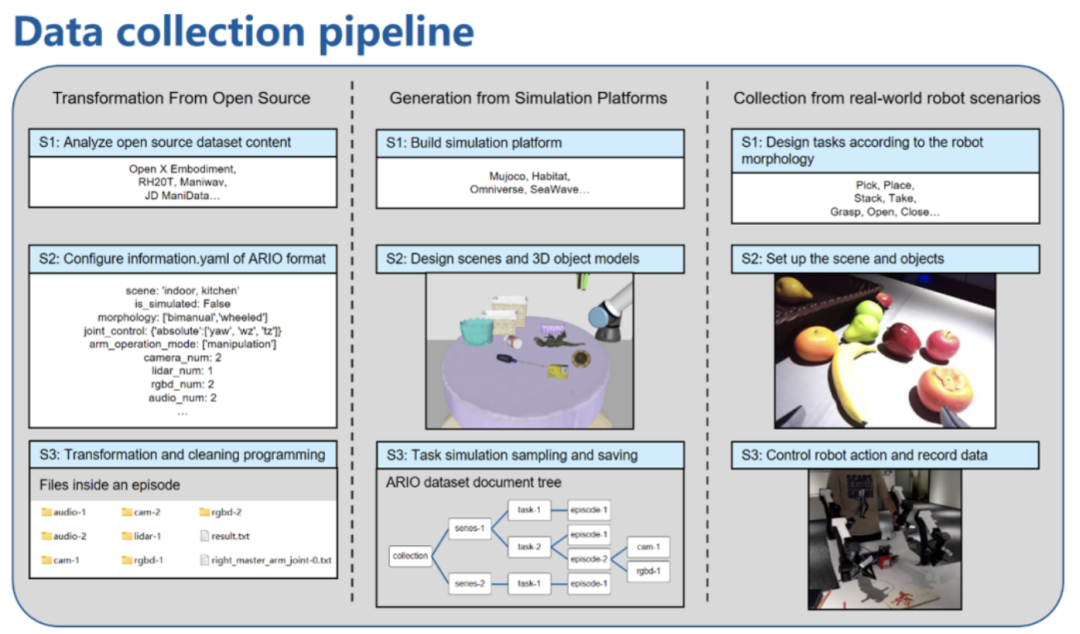
ARIO三类不同来源数据的收集流程
1)真实场景数据采集
数据采集机器人:Cobot Magic和Cloud Ginger XR-1。
a. Cobot Magic:松灵机器人旗下的一款主从双臂机器人
该平台具备以下核心组件:
-
移动底盘:采用AgileX Tracer AGV自动导航车,最大移动速度1.6 m/s,支持全向运动;
-
机械臂系统:搭载4组轻型6自由度机械臂,单臂末端负载3kg;采用主从控制架构,2组主臂通过重力补偿模式实现操作员直观示教,2组从臂实时复现主臂运动轨迹;
-
末端执行器:每支机械臂末端配置线性电机驱动的定制夹爪,主臂夹爪集成"手柄"物理控制接口,支持操作者连续调节开合状态;
-
视觉感知相机:部署3台奥比中光的Dabai RGB-D相机—— 2台从臂腕部相机+1台支架前向全局观测相机。

松灵机器人主从双臂机器人:Cobot Magic
任务设计:构建包含60+任务的层级化操作技能库,重点关注家庭场景下的桌面级精细化操作。任务分类及示例如下。

b. Cloud Ginger XR1:达闼科技旗下的一款轮式云端智能人形机器人
该机器人采用轮式全向移动底盘,拥有40余个智能关节,采用无框电机、中空对心设计。同时,装配7自由度灵巧手,与机械臂协同工作时,可实现,5kg负载下的高精度灵巧抓取,支持工具操作及其他精细动作执行。此外,机身拥有9个可扩展接口,可以轻松扩展以配备各种外设工具。
在任务设计上,共设计了拾取、放置和推移三类任务,三类任务分别采集了400条、200条和200条轨迹数据。

达闼科技人形机器人:Cloud Ginger XR1(图片来源:官方网站)
2)仿真模拟生成
ARIO数据集的模拟数据主要来自仿真平台:Habitat、MuJoCo和SeaWave。
a. 基于Habitat的目标导航(HM3D)任务 —— 目标类别:收集了6种目标类别的导航任务,每个任务关联一个目标类别;场景选择:从训练集划分中选取80个场景,并基于对应任务执行轨迹收集数据,目标是找到特定目标实例;路径规划:通过官方Habitat API实例化了一个“最短路径贪心跟随智能体”,该智能体接收指定目标位置后,将沿可行走区域的最短拓扑路径进行导航。
b. 基于MuJoCo物理引擎的机械臂操作任务 —— 设计了三个任务:目标物体抓取、篮筐精准投放以及抽屉开合操作;最终共生成包含21个交互对象的1700条轨迹片段,每条轨迹平均包含150个决策步。任务空间参数设置方面,机械臂末端执行器操作空间限定在1.2m×0.8m×0.6m的矩形工作域内,关节力矩控制频率设为20Hz,并添加了±5%的传感器噪声以提升仿真真实性。
c. 基于SeaWave的机器人操作任务 —— 研究人员将SeaWave原始数据集转换为ARIO格式。该基准测试包含基于UE5构建的仿真平台,旨在评估机器人理解与执行人类自然语言指令的能力。SeaWave任务根据指令语义复杂度与操作需求划分为四个层级:从基于简单指令的基础操作,到需要视觉感知支撑并依据抽象自然语言指令进行决策的复合型场景。
3)开源数据转换
ARIO中的开源数据转换涉及到3个数据集:Open X-Embodiment、RH20T 和 Maniwav Datasets。
a. Open X-Embodiment:该数据集包含74个子数据集,超过240万个场景片段(episodes)。研究人员开发了相应的转换工具,将该数据集中的数据转换为ARIO格式。在转换过程中,遇到了数据缺失和文档描述不清晰的问题。在尽可能保留原始数据的前提下,移除不相关或不可用的部分。通过过滤掉缺乏夹抓(gripper)和关节信息,或文档描述模糊的数据集,最终成功将62个子数据集转换为ARIO格式。
b. RH20T:该数据集记录了全面的运动学数据,包括关节角度、扭矩,以及夹爪的位置、朝向和开合状态。部分机器人夹爪还配备了指尖触觉传感器,增强了接触密集型任务中多模态数据的丰富性。在转换成ARIO格式的过程中,发现部分任务执行片段(episodes)中数据缺失(如摄像头画面或关节数据),且文档描述不够详细的问题。研究人员力求保留原始数据的完整性,仅排除任务描述完全缺失的片段,最终成功转换了12719条任务执行轨迹(episode trajectories)。
c. ManiWav:据介绍,ManiWAV团队是唯一研究声音对机器人任务成功率影响的团队。该数据集包含擦拭白板、翻转百吉饼(Bagel)、掷骰子和用尼龙搭扣胶带绑电线共4项任务,1297 条任务执行轨迹(episode trajectories)。研究人员开发了一个转换脚本,将所有公开的 ManiWAV 数据转换为 ARIO 格式,并为每个任务添加文本描述,以提高清晰度和实用性。
参考网址
-
论文链接:https://arxiv.org/pdf/2408.10899v1
-
项目主页:https://imaei.github.io/project_pages/ario/
-
数据集:https://openi.pcl.ac.cn/ARIO/AR

















 4962
4962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









