







文章目录
背景
1、最近的APA项目以及slam项目科研计划都推进到研究嵌入式平台的阶段
2、智能平台方案替换美系方案的工作是必然,最近国内芯片商接触频繁
3、算法方案商的合作中也在思考未来的智能驾驶的智能平台方案
1.智能平台角度
1.1 通用并行计算架构cuda方案
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。还有一个叫做cudnn,是针对深度卷积神经网络的加速库。
这个方案在短时间内L4,L5 的方案部署都是较好的。
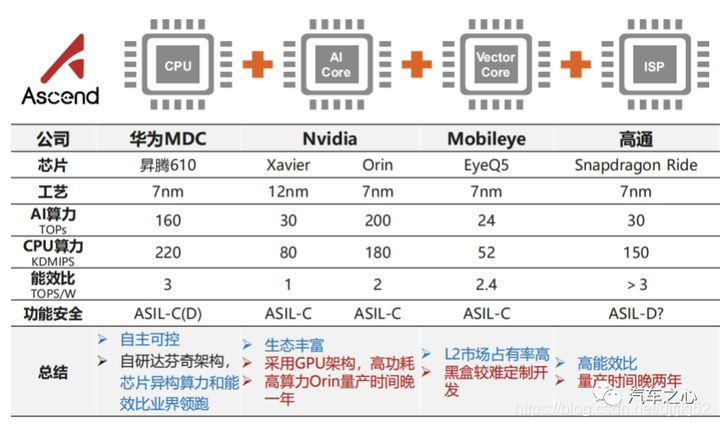
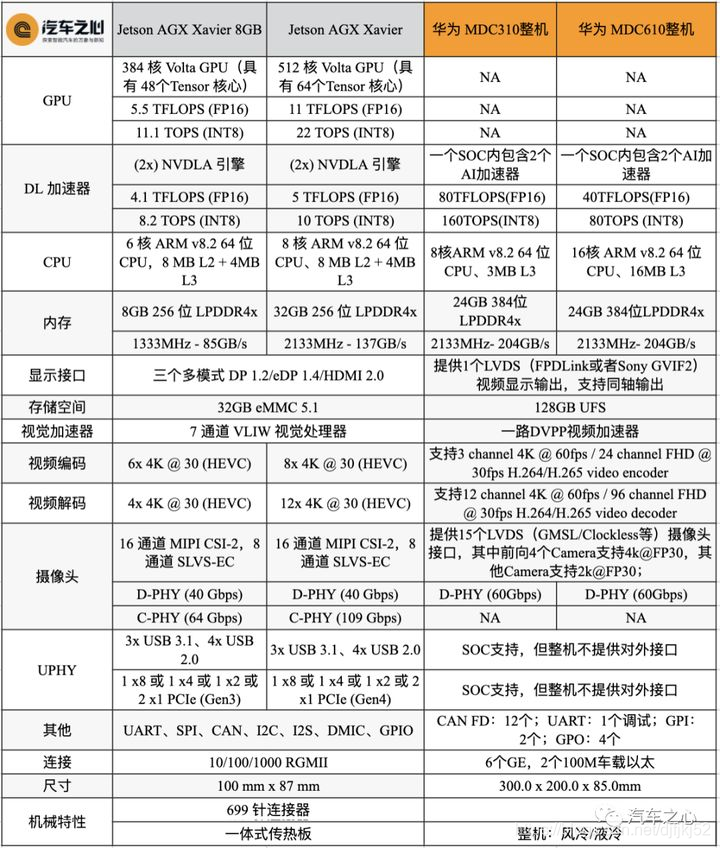
- NVIDIA DRIVE AGX Xavier ( 30 Tops)
- NVIDIA DRIVE AGX Orin™内置Orin芯片(200 Tops), L2 级到 L5 级完全自动驾驶汽车开发的兼容架构平台。由于 Orin 和 Xavier 均可通过开放的 CUDA、TensorRT API、NvMedia,Driveworks及各类库进行编程,因此开发者能够快速从目前的Xavier平台到Orin平台快速移植AV算法。并将于 2022 年开始投产
- NVIDIA Ampere架构也在进一步提升DRIVE平台的计算性能。
- 下一代DRIVE Pegasus Robotaxi自动驾驶平台。该平台凭借两个Orin SoC和两块NVIDIA Ampere GPU,可实现2000 TOPS的性能
华为MDC智能驾驶计算平台也具有L4,L5的能力
- MDC300 的算力在 64 Tops ,四颗华为昇腾(每颗芯片 16 Tops,大规模的低精度浮点型运),一颗的鲲鹏芯片(ARM,集成系统,一般擅长进行高精度浮点型串型运算),一颗是 TC397(MUC, ASIL-D)
- MDC600 ( 160 Tops)
特斯拉 HW3.0 FSD 控制器。
- FSD 的 HW3.0 有两个相同的计算单元构成,每个计算单元上面有 2 块运算芯片,每块算力位 36 Tops,设备总算力位 4 x 36 Tops = 144 Tops。但是由于采用的是双机热备的运行方式,实际可用的算力是 72 Top。在功能安全上,FSD 的 2 个计算单元每 20ms 同步一次运行状态与处理数据,通过交叉验证以保证故障冗余安全。
参考图:
1.2自研IP核方案,TI TDA4,地平线BPU,黑芝麻BSNN (NPU)等
采集自己的IP深度学习加速核,前期在FPGA上验证开发IP核。
一般设计时,DDR 与ARM 之间有cache;神经网络加速器NPU与DDR之间没有cache。arm与NPU交互需要首先刷新内存。
需要关注latency 核DDR带宽优化的取舍。
一般目前的地平线J3 黑芝麻A1000 不支持3D卷积(医学领域常用),BERT,NLP等(该信息需要与最新的文档保持,这里仅仅是目前了解的信息)
2. 嵌入式定点模型部署方案
定点一般4bits,8bits,16bits
2.1、MXNET 与,tensorflow,pytorch 量化训练方案
1、有利于模型精度
2.2、caffe,tensorflow,pytorch,ONNX 浮点-定点转换方案
1、有利于设计开发
2.3 未来更可能的部署方案
1、目前如果可以,建议采样api 加自定义层(如果支持)的方案,复杂但最直接。有利于调试。注意:在自研IP核的方案上无法实现自定义OP;在cuda方案可以实现自定义OP。
2、利用caffe 部署,应该是面向过去的粗颗粒度的方案
3、先转换成ONNX模型,然后浮点转定点,然后部署。其中,转换成ONNX的时候可能会由于自定义OP导致,ONNX中生成较多小OP,影响效率以及框架兼容性下降。可以考虑利用框架中的API自定义或者寻找替代相似OP。一般自研IP不支持API自定义深度学习网络层
2.4 关于ONNX转换的一些问题
自定义层的替换,或者API实现;胶水OP;不支持OP回退CPU等问题。专门一篇文章讲讲相关风险点。
注意:部署中前处理,后处理都需要去掉后生成ONNX网络,有利于部署。前处理对于图像一般有CV或者IPU等加速器实现(resize,crop,金字塔);对于激光雷达可能需要用arm出来。后处理一般放到arm上运行.
工具链角度
现阶段,对于面向量产的智能驾驶域控制器开发来说,已经有非常完备的工具链支持了。
包括:
- Adaptive AutoSAR 的配置工具 ARTOP、
- 代码开发/部署工具 Development Studio、
- 神经网络模型转换运行工具 ,
- Classic AutoSAR 的 Tasking 编译工具和配套的 MCU 二次开发包等等。


















 194
194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











