







其他推理框架可能不支持AdaptivePooling操作,该操作仅存于PyTorch中
PyTorch官方文档可知,
- AdaptivePooling可通过输入大小input_size自适应控制输出大小output_size,
- 而一般的AvgPooling/MaxPooling则是通过kernel_size、stride、padding来计算output_size,公式如下:
o u t p u t s i z e = c e i l ( ( i n p u t s i z e + 2 ∗ p a d d i n g − k e r n e l s i z e ) / s t r i d e ) + 1 output_size=ceil((input_size+2∗padding−kernel_size)/stride)+1 outputsize=ceil((inputsize+2∗padding−kernelsize)/stride)+1
因此通过input_size、output_size反推kernel_size、stride、padding,参考官方源码(https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/AdaptiveAveragePooling.cpp)将padding设为0,那么可推出去kernel_size、stride:
s
t
r
i
d
e
=
f
l
o
o
r
(
i
n
p
u
t
s
i
z
e
/
o
u
t
p
u
t
s
i
z
e
)
stride=floor(input_size/output_size)
stride=floor(inputsize/outputsize)
k
e
r
n
e
l
s
i
z
e
=
i
n
p
u
t
s
i
z
e
−
(
o
u
t
p
u
t
s
i
z
e
−
1
)
∗
s
t
r
i
d
e
kernel_size=input_size−(output_size−1)∗stride
kernelsize=inputsize−(outputsize−1)∗stride
例如,PyTorch网络的某一层含有nn.AdaptiveAvgPool2d(output_size=(14,14)),
- 它的output_size为 ( 14 , 14 ) (14, 14) (14,14),
- 该层的输入特征图大小为 10 ∗ 128 ∗ 128 10*128*128 10∗128∗128,
- 那么输出的特征图大小为 10 ∗ 14 ∗ 14 10*14*14 10∗14∗14,那么带入公式
可计算出nn.AvgPool2d(kernel_size, stride)的
- stride=(int(128/14), int(128/14)),
- kernel_size=((128-(14-1)*stride, (128-(14-1)*stride)
验证如下:
import torch
from torch import nn
input = torch.randn(10, 36, 36)
AAVP = nn.AdaptiveAvgPool2d(output_size=(12,12))
AVP = nn.AvgPool2d(kernel_size=(3,3), stride=(3,3))
output_AAVP = AAVP(input)
output_AVP = AVP(input)
链接:https://blog.csdn.net/github_28260175/article/details/103436020
实际情况
GAP
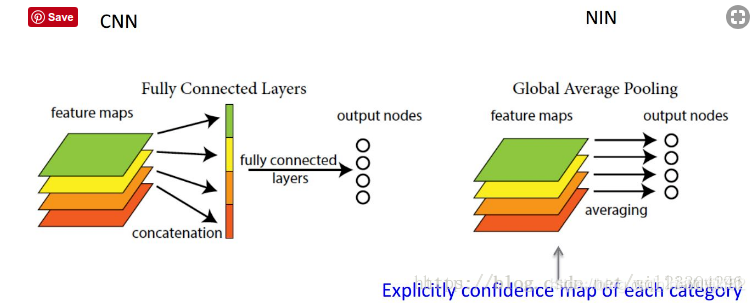
global average pooling 与 average pooling 的差别就在 “global” 这一个字眼上。global 与 local 在字面上都是用来形容 pooling 窗口区域的。 local 是取 feature map 的一个子区域求平均值,然后滑动这个子区域; global 显然就是对整个 feature map 求平均值了。
链接:https://blog.csdn.net/qq_23304241/article/details/80292859
代码验证
利用现有的pooling API实现全局平均池化的效果。
首先我们简单理解全局平均池化操作。
如果有一批特征图,其尺寸为 [ B, C, H, W], 我们经过全局平均池化之后,尺寸变为[B, C, 1, 1]。
也就是说,全局平均池化其实就是对每一个通道图所有像素值求平均值,然后得到一个新的1 * 1的通道图。
明白这个思路之后,我们就可以很容易实现全局平均池化了。
利用自适应平均池化就可以快速实现。或者自适应最大池化也可以,一样
链接:https://blog.csdn.net/CVSvsvsvsvs/article/details/90495254
In [1]: import torch
In [2]: a = torch.rand([1, 2048 ,32 ,32])
In [3]: a.size()
Out[3]: torch.Size([1, 2048 ,32 ,32])
In [4]: b = torch.nn.functional.adaptive_avg_pool2d(a, (1,1)) # 自适应池化,指定池化输出尺寸为 1 * 1
In [5]: b.size()
Out[5]: torch.Size([1, 2048 , 1, 1])
池化padding
这里主要分析最大池化和平均池化两个函数,函数中padding参数设置和矩阵形状计算都与卷积一样,但需要注意的是:
-
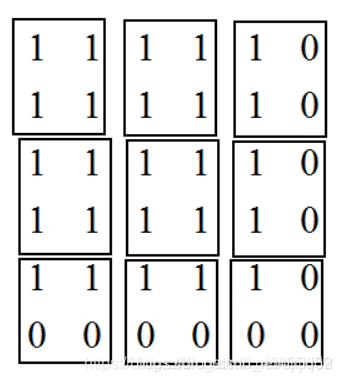
当padding=‘SAME’,计算avg_pool时,每次的计算是除以图像被filter框出的非零元素的个数,而不是filter元素的个数,如下图,第一行第三列我们计算出的结果是除以2而非4,第三行第三列计算出的结果是除以1而非4;
-
当计算全局池化时,即与图像矩阵形状相同的过滤器进行一次池化,此情况下无padding,即在边缘没有补0,我们直接除以整个矩阵的元素个数,而不是除以非零元素个数(注意与第一点进行区分)
填充0,还是1
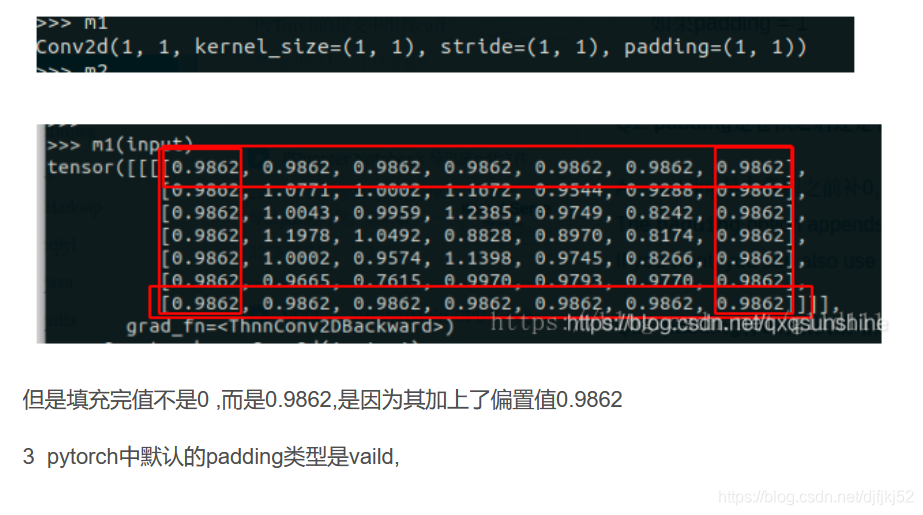
padding实在卷积操作之前的, 可以进行补0操作,也可补其他的.
其中padding补0 的策略是四周都补,如果padding=1,那么就会在原来输入层的基础上,上下左右各补一行,如果padding=(1,1)中第一个参数表示在高度上面的padding,第二个参数表示在宽度上面的padding.如下图:
池化层中都会加入padding操作的作用
(1) 池化层的作用体现在降采样,保留图像的显著特征,降低图像维度,使得特征图变小,简化网络.,增大kernel的感受野, 同时,也会提供一些旋转不变性. 但是特征图变小,有可能会影响到网络的准确度(措施:可以通过增加特征的深度来弥补,如深度变成原来的2倍)
(2) 卷积会带来的两个问题(1,卷积运算后,输出图像的尺寸会缩小; 2 越是边缘的像素点,对输出的影响就越小,卷积的时候移到边缘就结束了,但是中间的像素点有可能会参与多次计算,但是边缘的像素点可能只参与一次计算…因此可能会丢失边缘信息.)
padding的用途: 保持边界信息;可以对有差异的图片进行补齐,使得图像的输入大小一致;在卷积层中加入padding ,会使卷基层的输入维度与输出维度一致; 同时,可以保持边界信息 …

















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









