







如果想更深入地了解GPU的设计细节、实现细节,可阅读GPU厂商定期发布的白皮书和各大高校、机构发布的论文。推荐一个GPU解说视频:A trip through the Graphics Pipeline 2011: Index,虽然是多年前的视频,但比较系统、全面地讲解了GPU的机制和技术。
- Part 1:
Introduction; the Software stack.- Part 2:
GPU memory architecture and the Command Processor.- Part 3:
3D pipeline overview, vertex processing.- Part 4:
Texture samplers.- Part 5:
Primitive Assembly, Clip/Cull, Projection, and Viewport transform.- Part 6:
(Triangle) rasterization and setup.- Part 7:
Z/Stencil processing, 3 different ways.- Part 8:
Pixel processing – “fork phase”.- Part 9:
Pixel processing – “join phase”.- Part 10:
Geometry Shaders.- Part 11:
Stream-Out.- Part 12:
Tessellation.- Part 13:
Compute Shaders.
GPU基本概念
硬件层面:
- SP(Streaming Processor):流处理器, 是GPU最基本的处理单元,在fermi架构开始被叫做CUDA core。
- SM(Streaming MultiProcessor): GPU中最小的执行单元。一个SM由多个CUDA core组成。
软件层面:
- Kernel:在GPU上执行的函数。
- thread:一个CUDA的并行程序会被以许多个threads来执行。
- Block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
- Grid:Kernel 所对应的线程集合,由多个Block组成。
- Warp:是最基本的执行单元,一个warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。
GPU架构是围绕一个流式多处理器(SM)的扩展阵列搭建的。通过复制这种结构来实现GPU的硬件并行。
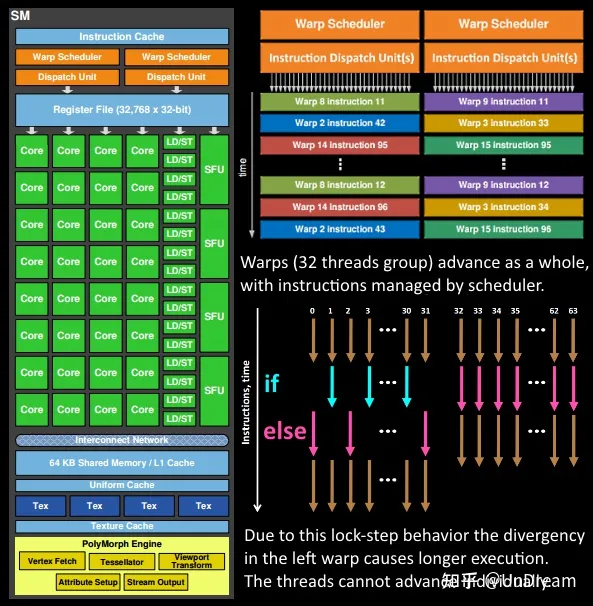
- 先大概看一下SM包含的模块,熟悉一下:
- Instruction Cache:指令缓存,缓存了该SM里Warps的指令;
- Warp Scheduler:线程束调度器;
- Dispatch Unit:指令分发器,根据Warp Scheduler的调度向核心发送该Warp的指令;
- Register File:寄存器,编译好的机器码如ADD r1 r2 r3,这些r开头的就是一个个寄存器,给Core提供计算参数或者存储输出结果,上图的SM中有3万多个32bit的寄存器,Warp中每个任务都会分配私有的寄存器;
- Core:计算核心,负责浮点数和整数的计算;
- SFU:Special Function Units,执行特殊数学计算(sin、cos、log等);
- LD/ST:Load/Store,访存单元,加载和存储数据;
- L1 Cache:一级缓存,片上内存,即该内存是位于芯片内部的,速度很快;
- Shared Memory:共享内存,片上内存;
- Tex与Texture Cache:纹理单元用于采样纹理,纹理缓存;
- PolyMorph Engine:多边形引擎,用于处理顶点数据拉取、Viewport Transform等。
参考NVIDIA官网资料:Life of a triangle - NVIDIA’s logical pipeline
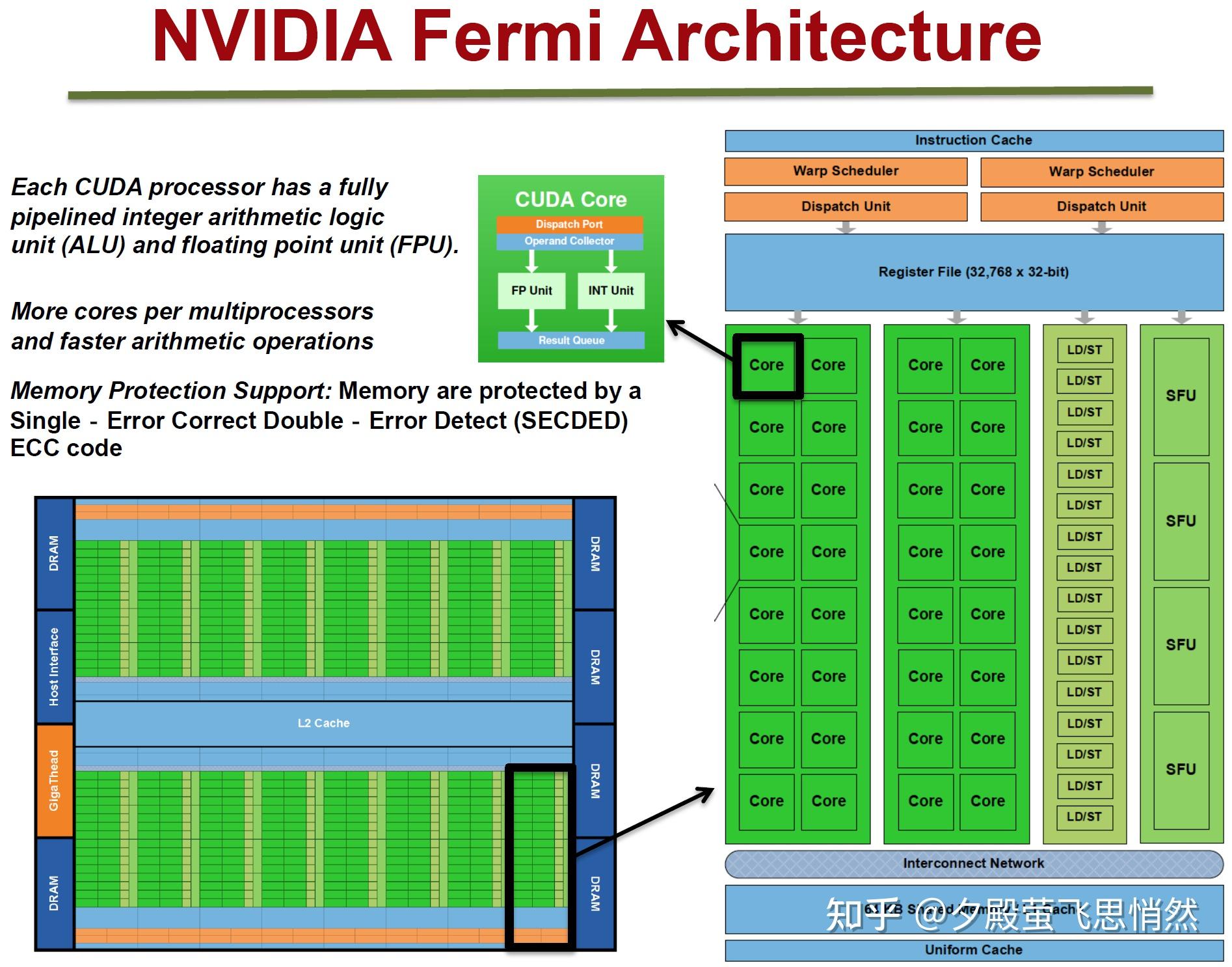
Fermi架构如上图,它的特性如下:
-
拥有16个SM
-
每个SM:
-
- 2个Warp(线程束)
- 两组共32个Core
- 16组加载存储单元(LD/ST)
- 4个特殊函数单元(SFU)
-
每个Warp:
-
- 16个Core
- Warp编排器(Warp Scheduler)
- 分发单元(Dispatch Unit)
-
每个Core:
-
- 1个FPU(浮点数单元)
- 1个ALU(逻辑运算单元)
2018年的NVidia Turing架构为例进行解析
 放大一点
放大一点
 上图是采纳了Turing架构的TU102 GPU,它的特点如下:
上图是采纳了Turing架构的TU102 GPU,它的特点如下:
- 6 GPC(图形处理簇)
- 36 TPC(纹理处理簇)
- 72 SM(流多处理器)
- 每个GPC有6个TPC,每个TPC有2个SM
- 4,608 CUDA核
- 72 RT核
- 576 Tensor核
- 288 纹理单元
- 12x32位 GDDR6内存控制器 (共384位)
单个SM的结构图如下:

每个SM包含:
64 CUDA核
8 Tensor核
256 KB寄存器文件
可用主观看出,一个商业级别的GPU 包含的东西比 寒武纪的深度学习加速卡 的会复杂一点,在图像的处理,浮点运算的考虑上更加丰富。
参考
GPU的内存相对与CPU会更复杂一些,主要是为了适应不同数据的访问效率而做了很多存储分化。
深度学习可好玩了:cuda编程笔记(四):存储系统结构10 赞同 · 0 评论文章
GPU架构方面可以看下面这篇文章:
https://blog.csdn.net/weixin_51971301/article/details/124703677
https://zhuanlan.zhihu.com/p/629678819

















 3204
3204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









