







 文章探讨了车道线检测在自动驾驶中的重要性,比较了2D和3D检测方法,着重介绍了3D-LaneNet和Gen-LaneNet等算法,以及它们在处理非平坦道路和复杂拓扑方面的改进。同时,文章强调了数据集的挑战和合成数据与时间传感器融合在3D车道线检测中的作用。
文章探讨了车道线检测在自动驾驶中的重要性,比较了2D和3D检测方法,着重介绍了3D-LaneNet和Gen-LaneNet等算法,以及它们在处理非平坦道路和复杂拓扑方面的改进。同时,文章强调了数据集的挑战和合成数据与时间传感器融合在3D车道线检测中的作用。
车道线检测是自动驾驶中最基本和关键的安全任务之一。这一重要感知任务的应用范围从 ADAS(高级驾驶员辅助系统)功能如车道保持到更高级别的自主任务,如与高清地图和轨迹规划的融合。给定在自动驾驶车辆上收集的输入 RGB 图像,车道线检测算法旨在在图像上提供结构化线的集合,每条线代表 3D 车道线的 2D 投影。这种算法本质上是二维的,因为输入和输出都驻留在同一个图像空间中。
另一方面,Monocular 3D Lane Line Detection旨在从单个图像直接预测道路场景中车道的 3D 布局。具体来说,3D 车道线检测算法在相机坐标系的 3D 度量空间中输出一系列结构化的车道线。最近,学术界和工业界已经在探索这项任务的可行性和应用方面做出了一些努力。
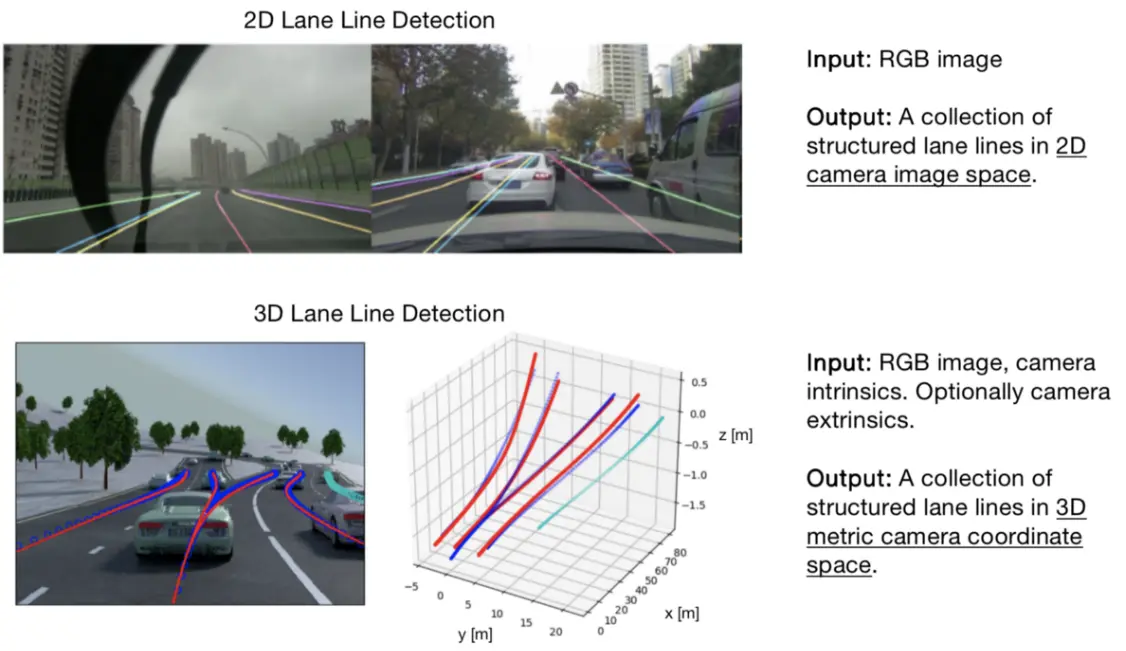
2D 和 3D Lane Line Detection 的比较(来源:CurvedLanes和3D LaneNet)
将 2D 车道线检测提升到 3D
一种简单的方法是使用逆透视映射 (IPM) 将 2D 车道检测结果重新投影回 3D 空间。IPM 是一种单应变换,可将透视图像变形为鸟瞰 (BEV) 图像。但是,IPM 假定地面平坦,并且是静态且经过良好校准的相机外在因素。在现实世界的驾驶环境中,道路很少是平坦的,并且由于速度变化或崎岖不平的道路,相机外在因素对车身运动很敏感。
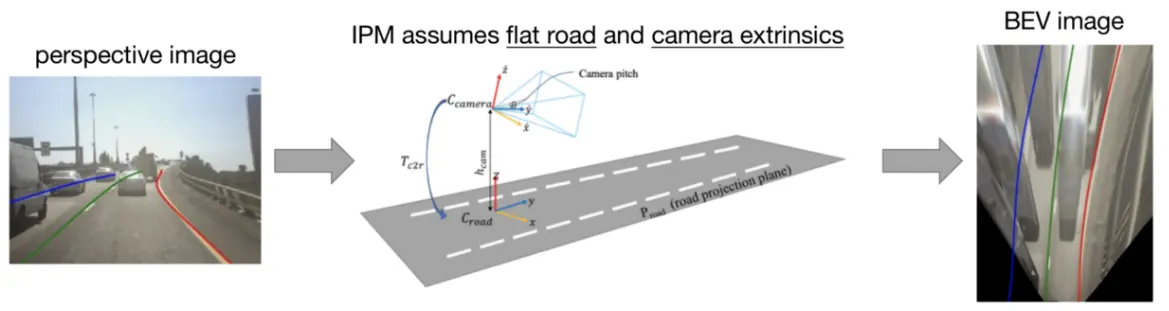
IPM 将透视图像中的信息投影回 3D 空间(图像取自3D-LaneNet)
因此,正确的方法是恢复检测到的 2D 车道线上每个点的深度。如果我们在推理时可以使用激光雷达等主动 3D 测量设备,则通过将 3D 测量分配给车道线点,2D 到 3D 的提升相对简单。如果我们在推理时只有相机图像,理论上,我们可以利用单目深度估计的最新进展来为车道线点分配深度值。虽然这种方法是通用的,但它的计算量很大。这篇博文回顾了更轻量级的方法来直接预测车道线点的 3D 位置。
与其他单目 3D 任务的关系
单目 3D 车道线检测是对其他单目 3D 任务的补充,这些任务可以从单个 RGB 图像预测驾驶环境的 3D 信息,例如单目 3D 对象检测和单目 BEV 分割。也许并不奇怪,如何从单目图像中准确地恢复环境深度是这些领域的核心。
二维车道探测网络
在我们深入研究 3D 车道线检测算法之前,一个重要的 2D 车道线检测算法是重新审视LaneNet(Towards End-to-End Lane Detection: an Instance Segmentation Approach , IV 2018)。它的 2D 车道线检测性能已经被许多新算法超越,但在当时还是相当创新的,它的许多想法构成了 3D 车道线检测的基础。
它对 2D 车道线感知的贡献是提出了一种用于车道线语义分割的分段然后聚类方法——我们稍后将在Semi-local 3D LaneNet中再次讨论这个想法。更有趣
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









