







这些天做一个英中排版项目,遇到一个问题,感觉很有典型意义:在memoQ中的译文本来已经定稿了,都导入Indesign开始排版了,客户又突然要求修改两个关键术语的译法,总共有几百处,但又不是所有和这两个术语对应的译文都修改,也就是说,原来的译法是“多到多”,修改后的译法还是“多到多”!
逐个搜索、确认、修改,当然是可以的,但人生苦短(马瘦毛长),都2202年了,还手工进行这种低级操作,太悲催了!上state of the art 流程!!
第一步,从前后两个版本的译文,整理一个修改对照表。这个对照表最后要用于专门的批量搜索和替换工具,用脚本对Indsign文件进行自动修改。为了防止overshoot(把不该替换的内容替换掉),以及undershoot(本来需要替换的内容未被替换掉),就要求修改的内容有一定的上下文,这个上下文不能太多,也不能太少。
我跟客户交换的文件是从memoQ导出的双列(双语)RTF格式,段段对照,下面是前后版本的截图:
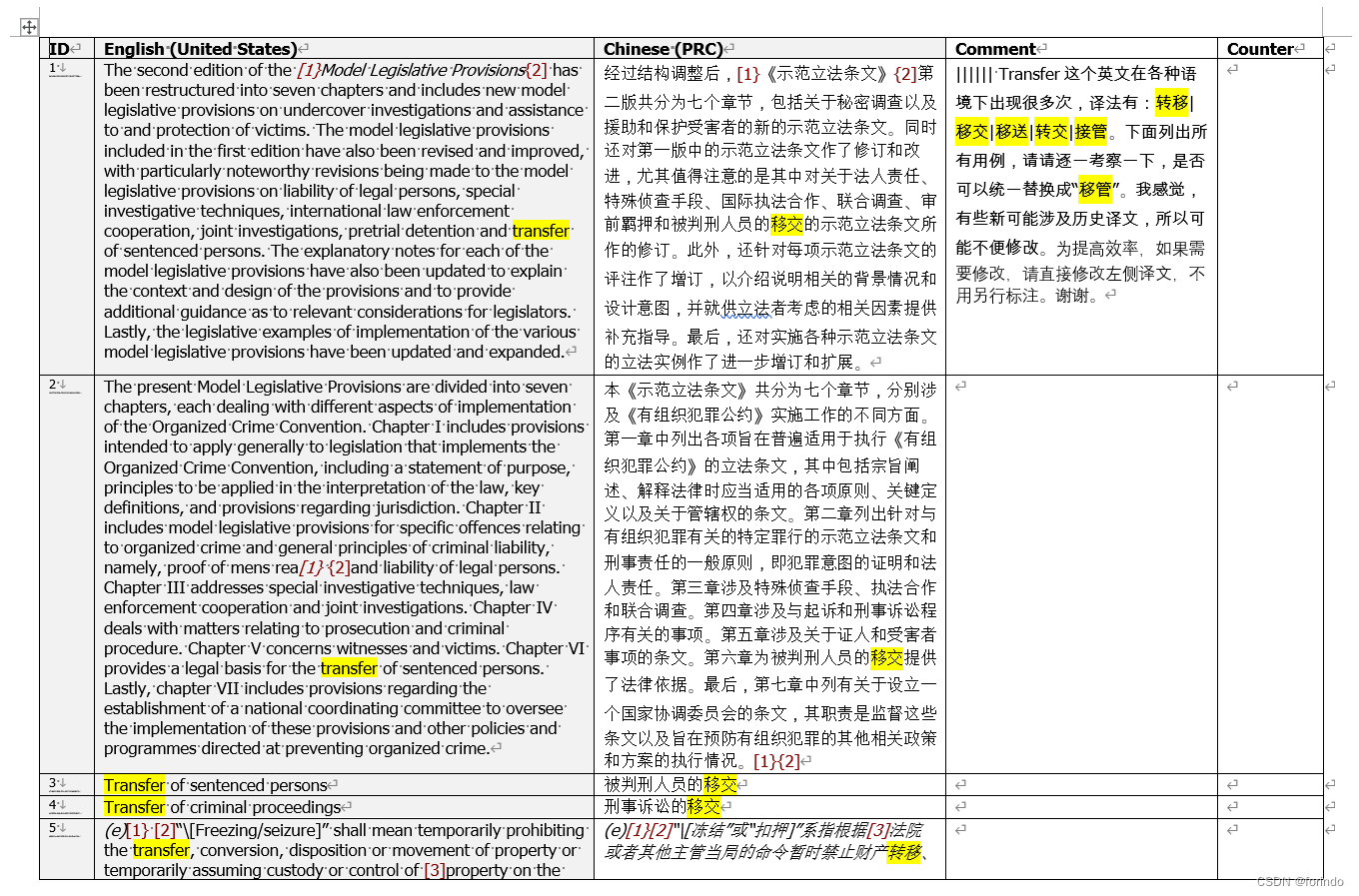
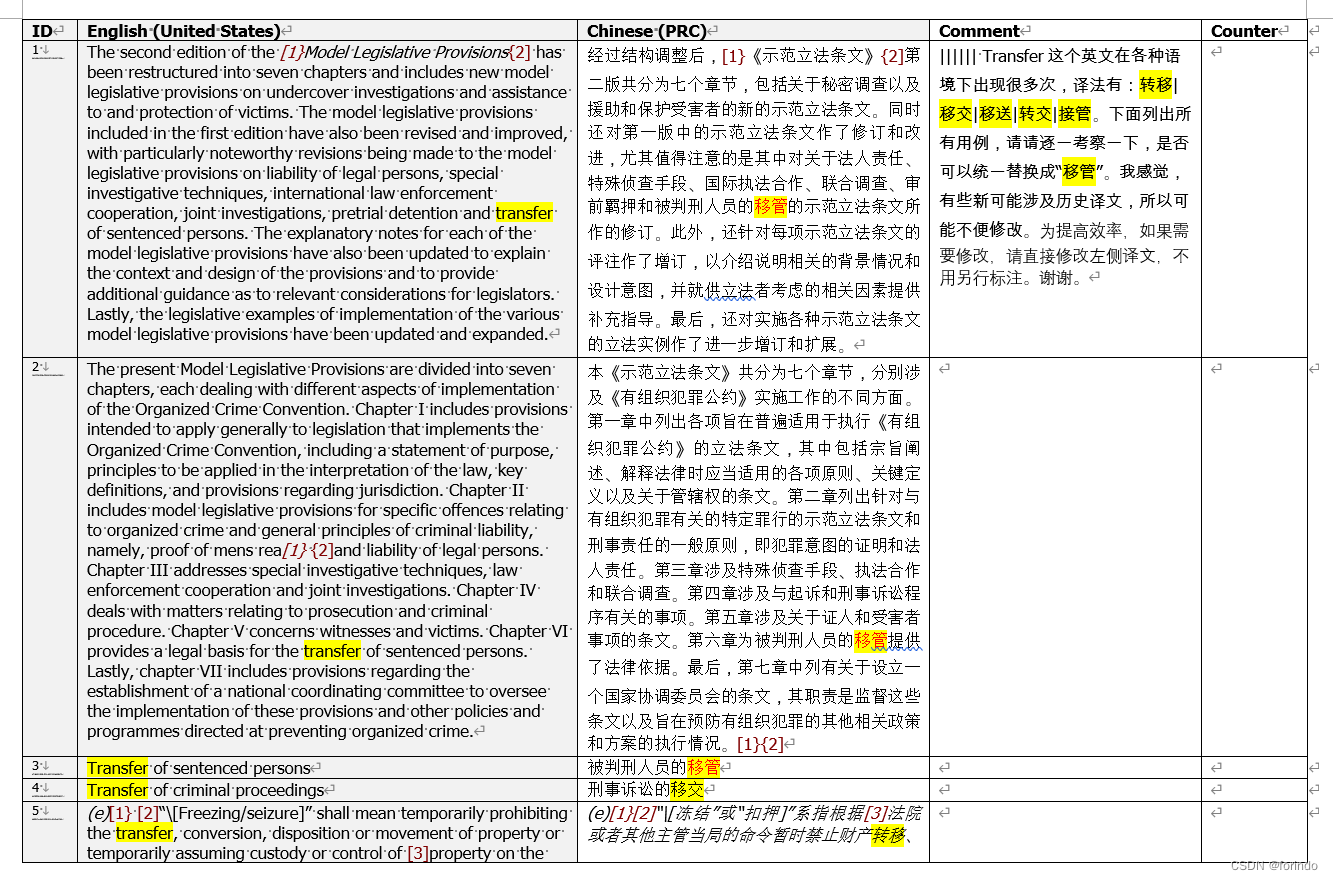
其中,前三个句段中的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1957
1957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









