






 本文提出DFCattention,一种针对边缘设备设计的高效、简单且擅长捕捉全局空间信息的注意力模块。将其应用到轻量化模型GhostNet中,形成GhostNetV2,实验证明在保持高精度的同时,显著提高推理速度。在ImageNet等数据集上,GhostNetV2表现出更好的性能和计算效率。
本文提出DFCattention,一种针对边缘设备设计的高效、简单且擅长捕捉全局空间信息的注意力模块。将其应用到轻量化模型GhostNet中,形成GhostNetV2,实验证明在保持高精度的同时,显著提高推理速度。在ImageNet等数据集上,GhostNetV2表现出更好的性能和计算效率。
论文见:
https://arxiv.org/abs/2211.12905
MindSpore代码:
https://gitee.com/mindspore/models/tree/master/research/cv/ghostnetv2
引言
智能手机等边缘设备计算资源有限,在设计模型时,不仅需要考虑模型的性能,更要考虑其实际的推理速度。计算机视觉领域爆火的Transformer模型在多个任务取得了很高精度,但在端侧设备上运行速度较慢,难以满足实时性的要求。经典的自注意力(self-attention)模块的计算复杂度较高,计算量随着输入分辨率的增加以二次方的速度增长。
尽管目前主流的局部注意力模块(将图像切分为多个区域,在每个区域内分别部署注意力模块)降低了理论复杂度,但图像切分需要大量变换张量形状的操作(比如reshape、transpose等),在端侧设备上会产生很高的时延。比如,将局部注意力模块和轻量化模型GhostNet结合,理论复杂度只增加了20%,但是实际的推理时延却翻了2倍。因此,为轻量化小模型专门设计硬件友好的注意力机制非常有必要。
DFC attention: 基于解耦全连接层的注意力模块
一个适用于端侧小模型的注意力模块应当满足3个条件:
-
对长距离空间信息的建模能力强。相比CNN,Transformer性能强大的一个重要原因是它能够建模全局空间信息,因此新的注意力模块也应当能捕捉空间长距离信息。
-
部署高效。注意力模块应该硬件友好,计算高效,以免拖慢推理速度,特别是不应包含硬件不友好的操作。
-
概念简单。为了保证注意力模块的泛化能力,这个模块的设计应当越简单越好。

图:DFC attention。分别沿着垂直、水平两个方向捕捉长距离信息。
相比自注意力机制,具有固定权重的全连接 (FC) 层更简单、更容易实现,也可用于生成具有全局感受野的注意力图。详细的计算过程如下所示。
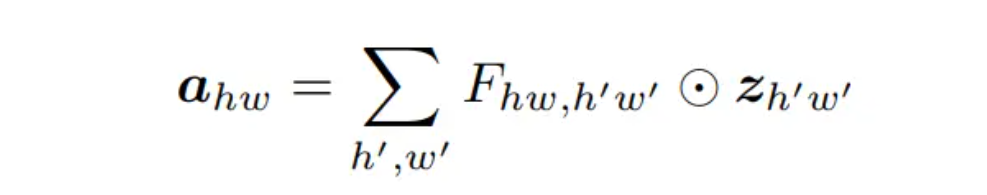
公式(1)
在(1)中,生成的特征图a和输入特征的每一个点都直接相关,能够捕捉到全局感受野。但由于输入输出特征上任意两个点都是直接连接的,计算量也很大。
本文把全连接层沿着水平和垂直两个方向解耦,分别使用两个全连接层来聚合这两个方向的长距离信息,就可以大幅降低计算复杂度,这样的注意力模块被称为 decoupled fully connected (DFC) attention。
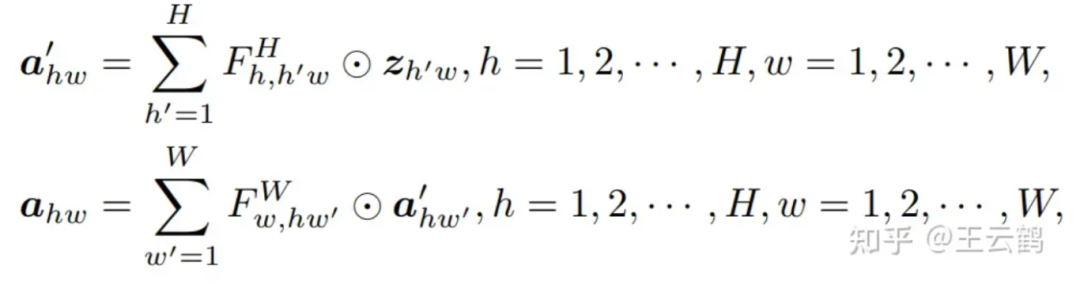
公式(2)
上式表示了 DFC attention的一般形式,分别沿水平和垂直方向聚合特征。通过共享部分变换权重,可以方便地用卷积实现,从而省去十分耗时的reshape、transpose等操作。为了处理具有不同分辨率的输入图像,卷积核的大小也可以与特征图的大小解耦,即使用大小为1×K_H 和 K_W×1 的两个depthwise卷积作用到于输入特征上。这种策略被TFLite 和 ONNX 等部署工具支持得很好,可以在移动设备上进行快速推理。
GhostNetV2:
将DFC attention插入到轻量化网络GhostNet中可以提升表征能力,从而构建出新型视觉骨干网络 GhostNetV2。
为了弥补Ghost 模块建模空间依赖能力的不足,本文将DFC attention和Ghost 模块并联。即:
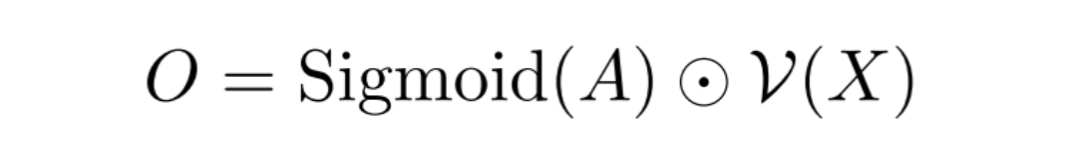
这里Sigmoid是归一化函数,A是attention map, V()表示Ghost模块,X是输入数据。如下图所示,两路特征相乘得到最终的输出。
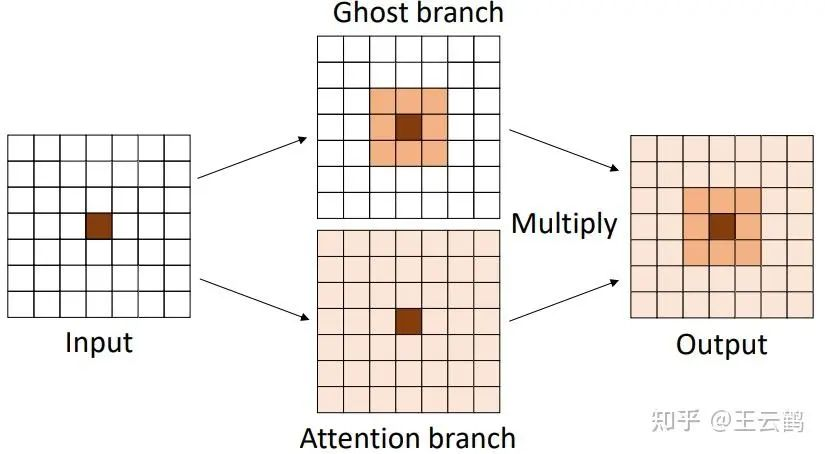
图:DFC attention与Ghost模块并联
为了减小DFC attention模块所消耗的计算量,本文对DFC这条支路上的特征进行下采样,在更小的特征图上执行一系列变换。同时,本文发现,对一个逆bottleneck结构而言,增强“expressiveness”(bottleneck中间层)比“capacity”(bottleneck输出层)更加有效,因此在GhostNetV2只对中间特征做了增强。GhostNetV2的bottleneck如下图所示。
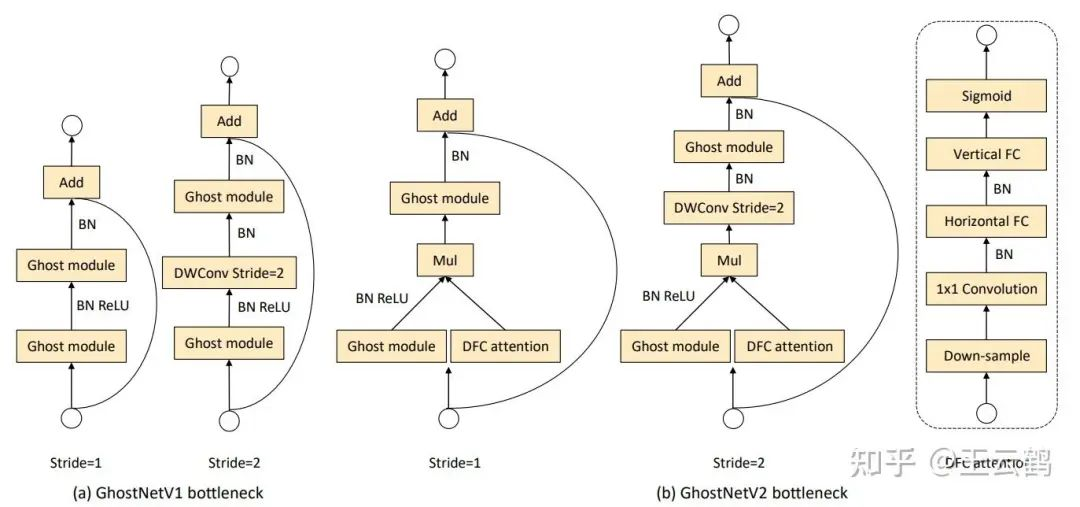
图:GhostNetV1和GhostNetV2
实验结果
本文在ImageNet图像分类、COCO目标检测、ADE语义分割等数据集上进行了实验。相比其他架构,GhostNetV2取得了更快的推理速度和更高的精度。
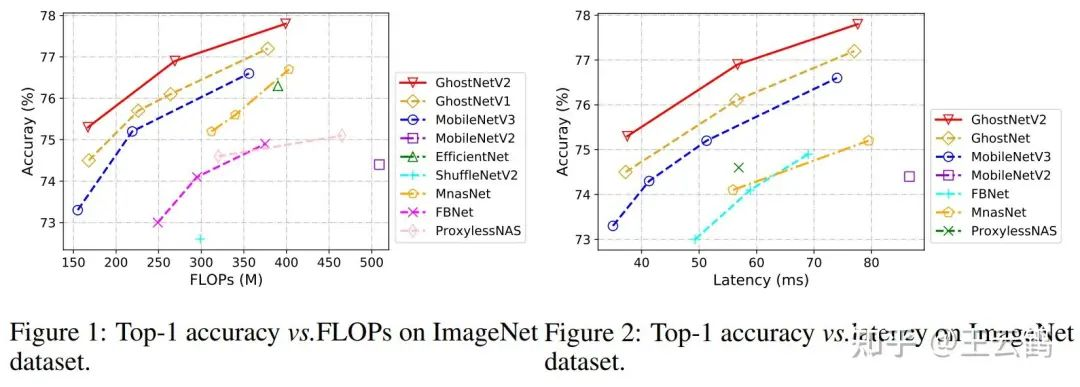
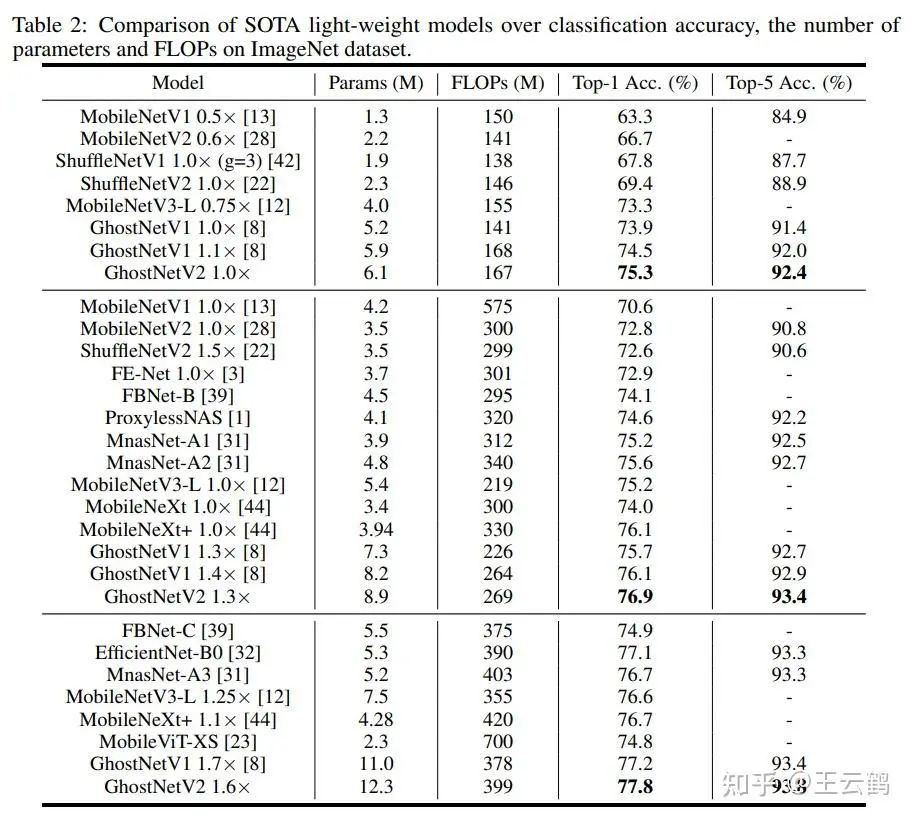
下面是ImageNet的实验结果,无论是理论计算量、还是端侧设备上的实测速度,GhostNetV2优于现有方法。
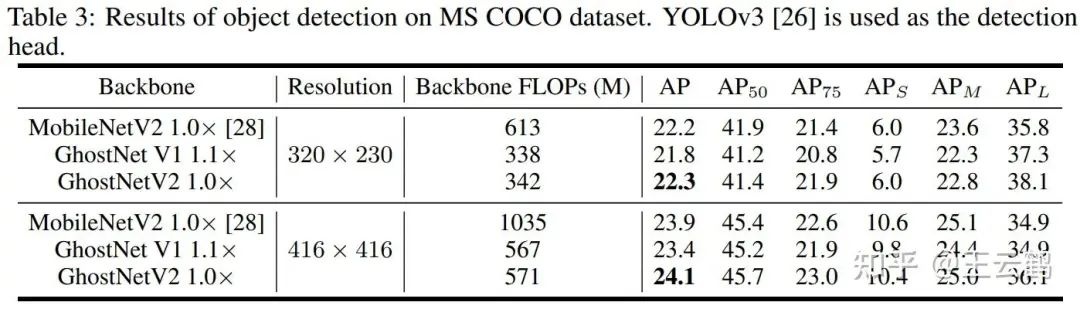
GhostNetV2也可以作为骨干模型,用于目标检测、语义分割等下游任务。结果如下:

















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









