







一、卡尔曼滤波
参考:
- 对Kalman Filter的一点简单的理解
- 【图解】卡尔曼滤波器是如何工作的
- 卡尔曼滤波、扩展卡尔曼滤波、无迹卡尔曼滤波以及粒子滤波原理
- 自动驾驶中无迹卡尔曼滤波器的应用(Unscented-Kalman-Filter) (重要全面!!)
1.1、卡尔曼滤波的思想
通过一个例子理解下卡尔曼滤波的思想。通俗理解卡尔曼滤波(无人驾驶感知融合的经典算法)
1 假设你现在有一辆车,并且已知小车在初始状态的位置如下图所示(小车的位置服从正态分布,比如可能位于正态分布的均值附近),横坐标为小车前进坐标。
有人会问,为什么是正态分布而不是确定点呢?因为在这里我们给出的是它此刻的状态估计量,对于地图上的物体,我们无法确切得出其具体的位置信息,即便你使用GPS来定位也始终会有一定的误差。因此你只能通过系统的输入(如小车的速度)和系统的输出(GPS给定的位置信息)来估算它当前的状态(真实的位置信息)。

2 然后,根据初始时刻小车的位置,我们可以预测出它在下一个时间步长的可能的位置分布。下图中可以看出,它的正态分布函数明显比上一时刻来的更宽一些。这是因为在小车运动过程中会不可避免地遇到一些随机因素的干扰,如坑洼、风、轮子打滑等,因此我们估算的位置值的不确定性变大,小车实际经过的距离与模型预测的距离不同。

3 到此刻为止,上述过程均是由我们的数学模型推算估计出来的结果,但实际上,相同的数据也可以通过传感器测量来获取,而测量值往往也呈正态分布(总之,频率派里未知值是一个确定的值,在贝叶斯派里,未知值都是一个概率分布,此点不用皱眉,很快你会有更深刻的认知),并且与我们的模型预测值有所不同,如下图中红色正态分布曲线所示,方差表示噪声测量中的不确定性。

4 这个时候咋办呢?可能你会脱口而出:将数学模型的预测值与传感器的测量值相互结合起来来获得小车的最佳位置估计值,怎么结合呢?加权平均再迭代!具体到这个例子中,咱们把这两者的概率密度函数相乘得出了当前时刻的最佳状态估计值,如图中灰色正态分布曲线所示,这就是卡尔曼滤波的核心思想,因此卡尔曼滤波也经常被称作传感器融合算法。

再然后,我们把前面的时间信息换一下,比如我们知道了上一时刻即k-1时刻小车的位置估算值,并且通过数学模型预测得到了k时刻的位置估算值,然后将其与小车传感器的测量值进行结合,得到了当前k时刻小车的最佳位置估算值。
问题的提出以及系统线性与非线性(参见SLAM中的EKF,UKF,PF原理简介)
1.2、基本公式推导(方法1 - 加权方法)
1.2.1 针对机器人的位置和速度建模
假如你开发了一款小型机器人,它可以在树林里自主移动。我们可以通过一组状态变量来描述机器人的状态,包括位置和速度:
下面,我们需要机器人需要明确自己的位置以便进行导航。怎么确定位置呢?
首先,我们给机器人安了一个GPS传感器,但精度只在10m。考虑到对于在机器人所处的树林里有很多溪谷和断崖,如果机器人对位置误判了哪怕只是几步远的距离,它都有可能掉到坑里,所以仅靠这个精度的GPS来定位是不够的。
我们得有更多的办法确定位置。比如我们可以获取到一些机器人的运动的信息:驱动轮子的电机指令。如果没有外界干扰,仅仅是朝一个方向前进,那么下一个时刻的位置只是比上一个时刻的位置在该方向上移动了一个固定距离。但如果有外界干扰呢?比如逆风行驶,轮子打滑,滚落颠簸地形……所以轮子转过的距离并不能完全表示机器人移动的距离,这就导致通过轮子转动预测机器人的位置不会非常准确。
如此,相当于
- GPS传感器会告知我们一些关于机器人状态的信息,但是GPS可能不准;
- 另外,通过轮子转动可以预知机器人运动的距离,可同样也有一定的不准确度(受外力干扰)。
行到水穷处换个思路:如果我们综合“GPS + 轮子转动预测”两者的信息呢?是否可以得到比只依靠单独一个信息来源更精确的结果?显然,这就是卡尔曼滤波要解决的问题。
针对上边的系统,我们建立包括位置和速度的系统状态:

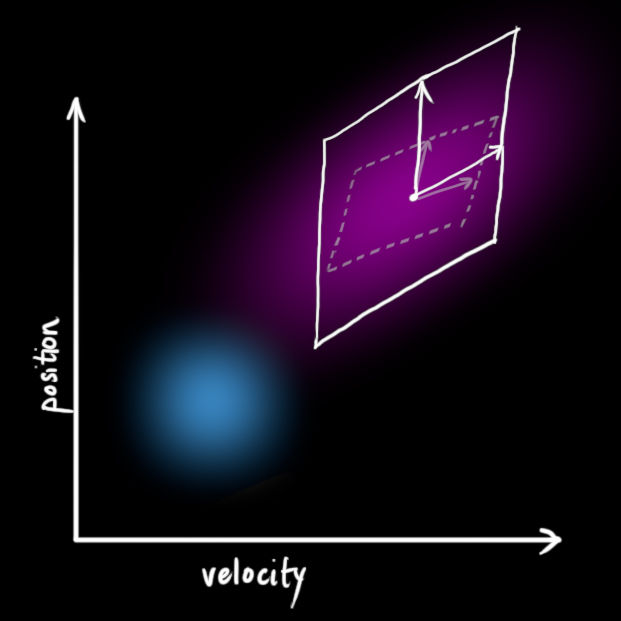
我们不知道位置和速度的准确值,但是我们可以列出一个准确数值可能落在的区间范围。在这个区间范围里,一些数值组合的可能性要高于另一些组合的可能性。

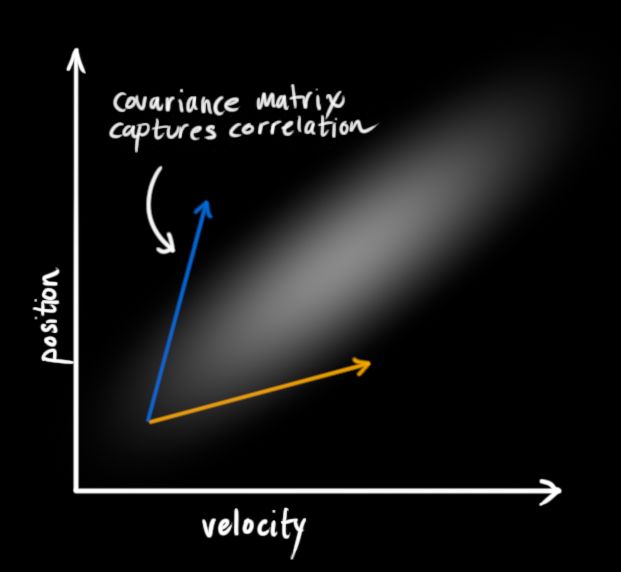
卡尔曼滤波假设所有的变量(在我们的例子中为位置和速度)是随机的且符合正态分布。每个变量有一个均值u 代表了随机分布的中心值(代表这是可能性最大的值),和一个方差 ,用于衡量不确定度。
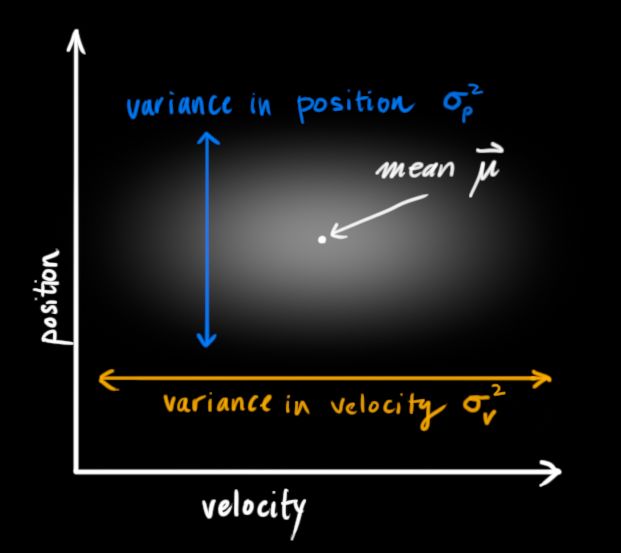
在上图中,位置和速度是不相关的,这意味着我们不能从一个变量推测另一个变量。
实际上呢,位置和速度是相关的。比如已知上一个状态的位置值,现在要预测下一个状态的位置值:
- 如果机器人的速度很快,一定的时间内,机器人可能移动得很远;
- 相反,如果速度很慢,同样的时间内,机器人会移动的很近。
这种关系在跟踪系统状态时很重要,因为它给了我们更多的信息:一个测量值告诉我们另一个测量值可能是什么样子。
为了捕获这种相关性,我们可以使用协方差矩阵(见说明)。简而言之,矩阵中的每个元素(协方差)表示了第
个变量和第
个变量之间的关系(协方差矩阵是对称的,即交换下标
和
并无任何影响)。
对离散随机变量来说,期望定义如下(见知乎)
对连续随机变量而言,期望的定义如下
我们仿照方差的公式来定义协方差:(这里指样本方差和样本协方差)
方差:
协方差:
(注:因为这里是计算样本的方差和协方差,因此用n-1。之所以除以n-1而不是除以n,是因为这样能使我们以较小的样本集更好地逼近总体,即统计上所谓的“无偏估计”。)
协方差表示两随机变量 X,Y 之间的相关性问题
协方差矩阵
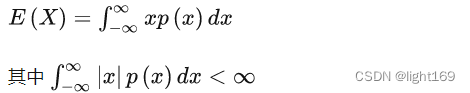
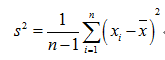
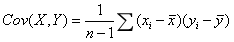
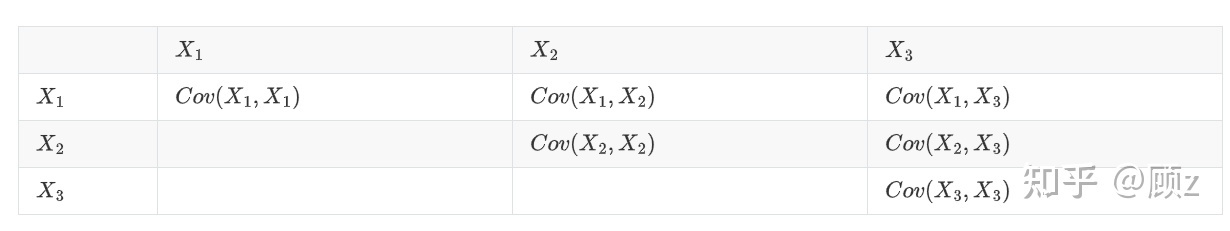
协方差矩阵通常表示为Σ,它的元素则表示为 ,从而有
1.2.2 利用矩阵进一步描述系统状态
为了把以上关于状态的信息建模为正态分布,所以在k时刻我们需要两个信息:最佳预估值 (均值,也就是u),和它的协方差矩阵
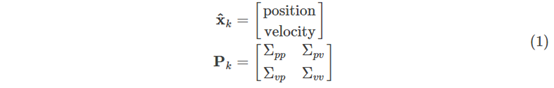
(这里我们只记录了位置和速度,但只要和问题相关,我们可以把任何数据变量放进系统状态里)
接下来,我们要通过k-1时的状态来预测下一个状态
(k时)。但我们不知道
的准确值,怎么办呢?预测函数会对k-1时刻所有
可能值的范围进行预测,然后得出一个k时刻新值
的分布范围。

我们可以通过一个状态转移矩阵来表示这个预测过程,
把k-1时刻所有可能的状态值转移到一个新的范围内(它从原始预测中取每一点,并将其移动到新的预测位置),这个新的范围代表了系统新的状态值可能存在的范围,如果k-1时刻估计值的范围是准确的话。
考虑到匀速状态下,S(路程)=v(速度)x t(时间),我们通过下述公式来描述这个"预测下个状态"的过程(别忘了,):

进而整理为矩阵则是:
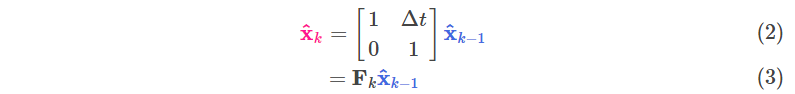
我们现在有了一个预测矩阵,可以简单预测下个状态,但怎么更新协方差矩阵呢?
试想,如果我们对每个点进行矩阵A转换,它的协方差矩阵Σ会发生什么变化,比如

结合(4)和(3)( 协方差矩阵):

1.2.3 不确定外部因素的估计:贝叶斯理论
到目前为止,我们还没有考虑到所有的影响因素,因为系统状态的改变并不只依赖上一个系统状态,外界作用力也可能会影响系统状态的变化。外界作用力分两种
- 第一种是人为指令,例如,在我们跟踪一列火车的运动状态时,火车驾驶员可能踩了油门使火车提速。
- 第二种是不受人为控制,比如2.1节提到的坑洼、风、轮子打滑等等,其所带来的变化是未知且不好预测的,没法严格确定到某个具体的值。恩,有没有熟悉的贝叶斯理论的味道了?
对于贝叶斯的理论有必要提一下(特引用我之前写的一篇贝叶斯笔记,详见参考文献5)
先看两个例子
比如有一个袋子,里面装着若干个白球和黑球,请问从袋子中取得白球的概率θ是多少?”
频率派的人会想都不用想而立马告诉你,取出白球的概率
就是1/2,要么取到白球,要么取不到白球,即θ只能有一个值,而且不论你取了多少次,取得白球的概率θ始终都是1/2,即不随观察结果X 的变化而变化。
贝叶斯的理论则认为取得白球的概率是个不确定的值,因为其中含有机遇的成分。
再比如,一个朋友创业,你明明知道创业的结果就两种,即要么成功要么失败,但你依然会忍不住去估计他创业成功的几率有多大?你如果对他为人比较了解,而且有方法、思路清晰、有毅力、且能团结周围的人,你会不由自主的估计他创业成功的几率可能在80%~90%这个区间范围。这种不同于最开始的“非黑即白、非0即1”的思考方式,便是贝叶斯式的思考方式。
换言之
- 频率派把需要推断的参数θ看做是固定的未知常数,即概率虽然是未知的,但最起码是确定的一个值,同时,样本X 是随机的,所以频率派重点研究样本空间,大部分的概率计算都是针对样本X 的分布;
- 而贝叶斯派的观点则截然相反,他们认为参数是随机变量,而样本X 是固定的,由于样本是固定的,所以他们重点研究的是参数的分布。
针对第一种外力,在我们机器人例子中,导航软件可能发出一些指令启动或者制动轮子。这个好解决,通过一个控制向量 来描述这些信息,把它添加到我们的预测方程里作为一个修正。
假如我们通过发出的指令得到预期的加速度a,根据速度-加速度公式,以及加速度-位移公式
,上边的运动方程可以变化为:

再次整理为矩阵则是:

称作控制矩阵,
称作控制向量(当没有任何外界动力影响的系统时,则可以忽略该项)。
针对第二种外力,则相对麻烦些了,比如受到风力影响或轮子打滑、地面上的坑坑洼洼、突起异物都使得我们跟踪的物体的速度发生不可控的变化。
怎么办呢?可以把“世界”中的这些不确定性统一建模,在预测步骤中增加一个不确定项。

相当于原始状态中的每一个点可以都预测转换到一个范围,而不是某个确定的点。转换为数学表达是: 中的每个点移动到一个符合协方差
的高斯分布里(也就是蓝色的高斯分布移动到紫色高斯分布的位置),或者说,把这些不确定的外部因素描述为协方差为
的高斯噪声,具体根据预测的传感器噪声来定(比如imu或者轮速计):

这个紫色的高斯分布拥有和原蓝色的高斯分布相同的均值,但协方差不同。
对 简单叠加,可以拿到扩展的协方差,这样就得到了预测步骤的完整表达式:

解释下上面(7)中的那两个式子
- 新的最佳估计是在原最佳估计的基础上,通过已知的外部影响校正得到的预测值。
- 新的不确定性则综合了原不确定性和不确定的外部因素的影响得到的预测。
到这里,我们得到了一个模糊的估计范围,一个通过 和
描述的范围。如果再结合我们传感器的数据呢?
1.2.4 数学模型之外再通过测量值修正预测值
实际生活当中,我们经常会用到不止一种手段来多方论证我们的预测结果,上节我们通过建立数学模型预测,此外,我们可能还有一些传感器来测量系统的状态。
当然,我们可能有好几个传感器,比如一个测量位置一个测量速度,每个传感器可以提供一些关于系统状态的数据信息(每个传感器检测一个系统变量并且产生一些读数)。

考虑到传感器测量的范围和单位可能与我们跟踪系统变量所使用的范围和单位不一致,所以需要对传感器做下建模:通过矩阵。
初学者刚看到这的时候可能会有疑问,这个到底是干啥用的?
通过上文1.1节,我们已经知晓,卡尔曼滤波实质就是将预测状态量的高斯分布和观测量的高斯分布做融合,生成一个新的高斯分布。
而很快你会通过下文发现,这个新的高斯分布的均值和方差是两个独立的高斯分布的相关参量的加权,这个加权就是卡尔曼增益,但是预测状态量和观测量可能维度不同,需要将他们同时转换到一个向量空间中,所以观测量有了线性变换矩阵
,相当于状态域通过
为避免降低本文的可读性,再举个例子,比如车速可以映射到轮速计的转速,车速到转速的转换关系就可以通过

把得到的传感器读数的分布范围转换为一般形式:
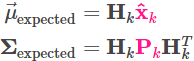
换言之,我们的传感器也是有自己的精度范围的,对于一个真实的位置和速度,传感器的读数受到高斯噪声的影响会在某个范围内波动。
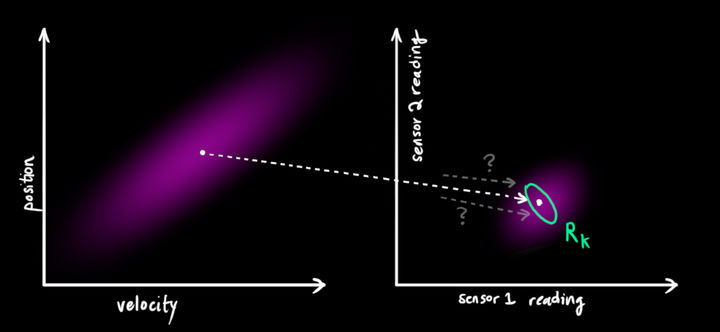
我们观测到的每个数据,可以认为其对应某个真实的状态。但是因为存在不确定性,某些状态的可能性比另外一些的可能性更高。

我们将这种测量值与真实值之间的不确定性(即观测传感器噪声)的协方差设为,均值设为
,具体根据观测传感器的噪声来定(比如相机、lidar)。
所以现在我们有了两个数据,一个来自于我们通过数学模型的预测值,另一个来自传感器的测量值。

我们必须尝试去把两者的数据预测值(粉色)与测量值(绿色)融合起来。
实际上对于任何状态,都有两个可能性:
- 传感器读数更接近系统真实状态
- 预测值更接近系统真实状态
怎么融合呢?概率论里,两个事件如果同时发展则相乘,所以我们尝试将两个高斯块(Gaussian blob)相乘试下:
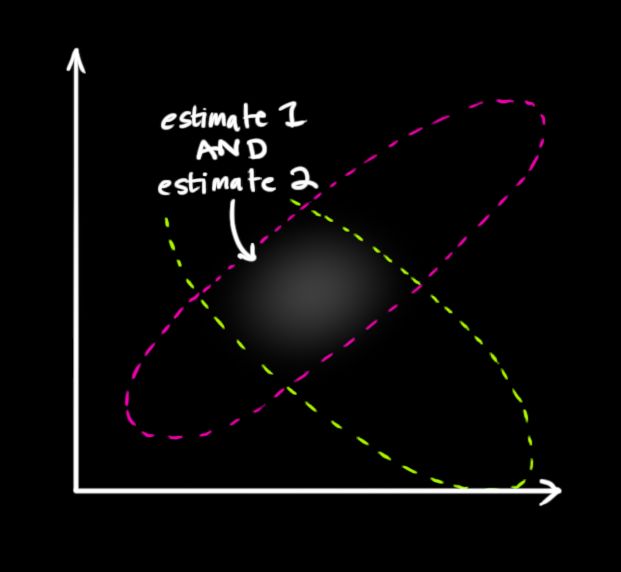
相乘之后得到的即为重叠部分,这个区域同时属于两个高斯块,并且比单独任何一个区域都要精确。这个区域的平均值取决于我们更取信于哪个数据来源,这样通过我们手中的数据得到了一个最好的估计值。
恩,又是另一个高斯块。
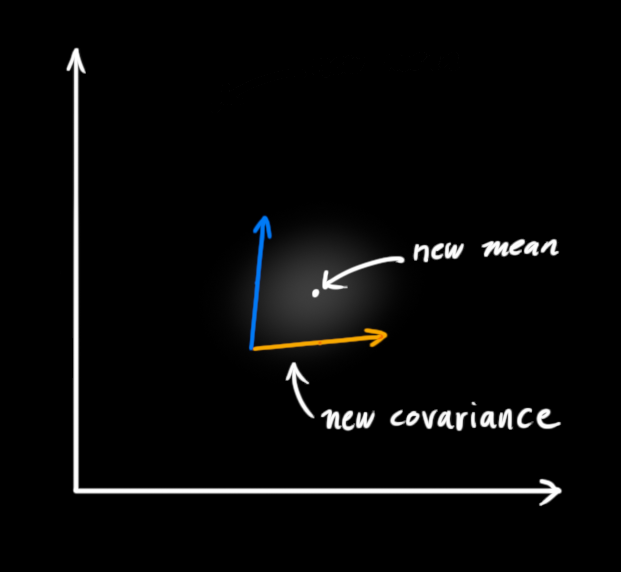
事实证明,当你把两个高斯分布相乘时(各自的均值和协方差矩阵相乘),你会得到一个拥有独立均值和协方差矩阵的新高斯分布。最后剩下的问题就不难解决了:新高斯分布的均值和方差均可以通过老的均值方差求得!
1.2.5 融合两个高斯斑:卡尔曼增益出场
首先,针对一维数据开始,一维高斯(均值u,方差)的方程被定义为:
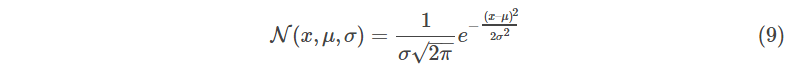
如果两个高斯分布相乘会发生什么呢(如之前所说,预测值是粉红色,测量值是绿色),下图的蓝色曲线代表了两个高斯分布的交集部分:


把(9)带入(10)然后做一些变换,可以得到
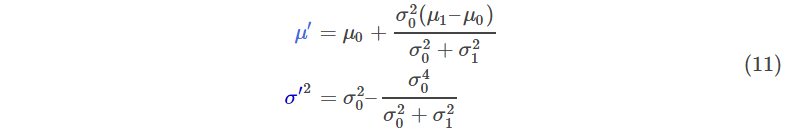
且慢,上述公式11的推导如果不一步步展开,则会导致初学的你在千篇一律的人云亦云中看的还是很头疼,所以我们把上面的变换展开下:
其中,A代表其它项,从而有
因式分解出一个部分,这部分用k表示:

相当于如果是一维数据下,对于之前的预测值,仅仅是简单将两者叠加相乘就可以得到新的预测值。(这个叠加相乘是不是应该有可交换性?? 看公式推导是可交换的)
如果是一个多维矩阵呢?我们将(12)与(13)表示为矩阵形式。Σ表示协方差矩阵, 表示平均向量:

上述的这个矩阵K 就是卡尔曼增益。
现在,我们有两个独立的维度去估计系统状态:
预测值
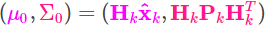
测量值
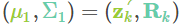
将两者相乘带入(15)寻找他们的重叠区域:

从(14)可知,卡尔曼增益为
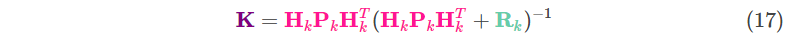
到了关键步骤!原文是一句带过,但为本文的通俗考虑,我多解释两句:
- 将(16)的第一个公式的两边都除以
,所以结合了
),同时(16)的第二个公式的左右两边都约掉
,可以得到(18)的第二个公式(一样结合了这个定义
- 然后对(17)的两边也都同时除以

以为就这样了?我对正在读此文的你提一个问题,上面为何要从(16)(17)除以变到(18)(19)呢,这就要谈到卡尔曼增益的本质了。卡尔曼增益的本质其实就是把(11)里面经常用到的一个中间结果定义了一个变量,它的物理意义在于:
- 根据两方面的方差来决定最终的权重,这个相信大家都已理解了;
- 把观测域变回到状态域:即(16)是在观测域, 除以
1.2.6 全流程回顾:从预测传感器噪声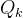 到观测传感器噪声
到观测传感器噪声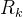
至此,原外文针对卡尔曼滤波的过程差不多了,但为考虑增加本文的可读性,所以我再总结如下:
回顾下整个过程
- 最开头,我们分别建立了系统的协方差矩阵
,以及状态转移/预测矩阵
,预测传感器不确定的外部因素描述为协方差为
- 随后把预测状态量到观测量的变换矩阵设为
进而求出了卡尔曼增益的计算公式:
再回到递推公式(核心思想就是用测量值修正预测值)
从而有
特别大的时候(测量值相对不靠谱,毕竟R代表传感器噪声,R越大代表噪声越大,也就意味着测量值越不靠谱),卡尔曼增益
趋于零,也就是去更多相信预测值
;
- 当
,从而代入递推公式,可得
也算是再次验证了卡尔曼滤波里的数据融合思想。
终于,我们得到了最佳预测值,可以把它继续放进去做另一轮预测,持续迭代(独立于
)。
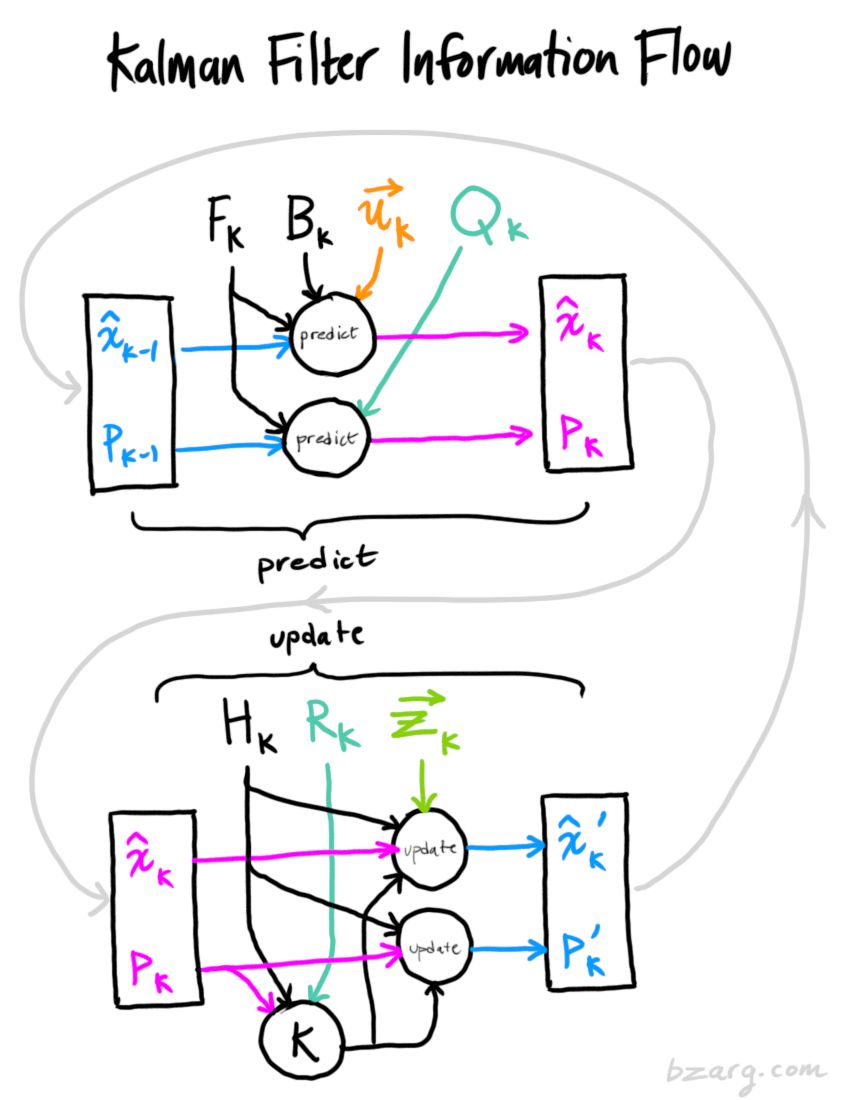
以上所有公式,仅需要实现(7)(18)(19),这使你可以对任何线性系统建模。
公式7类似于预测未来,公式18、19类似修正当下,简言之,则是前者预测 后者更新。
另外,有一点值得一提的是,公式18中括号里的部分就是所谓的“更新量”,这个更新量的物理意义是实际与期望测量值的误差,而卡尔曼增益则是这部分更新量对于预测值的权重。
当然,卡尔曼滤波的推导思路很多:1 从加权的角度;2 从贝叶斯的角度;3 从最小二乘角度。限于篇幅,本文只介绍加权的角度,至于后两者,读者可以自行查阅相关文章,比如参考文献14的《机器人学中的状态估计》,这本书讲得不错,可能相关符号的表示有所差别(比如本文里的、
、
、
在书中分别是
、
、
、
),但不影响理解,拍图如下,最后还可以看下参考文献18、19。

至于非线性系统,则可以使用扩展卡尔曼滤波(Extended Kalman Filter,EKF),相当于对测量和预测值的平均值进行简单线性化,下部分会详细介绍。
1.3 基本公式推导(方法 - 最小二乘法)
卡尔曼滤波是目前应用很广泛的一种滤波方法,最早由Kalman老先生在1960年提出,网上可以找到原文。这种方法最开始用在航天领域,作为轨道矫正的一种方法,有很好的效果。
卡尔曼滤波的方法的核心思想,就是用另一个测量空间的观测值去纠正当前空间对被测量的量的估计。简单来说,就是用一种方法去测量一个量。同时建立一个模型去估计这个测量的量,最后,按权重的方式求这两种方式的和,就是滤波之后的量的值。而这个权重的大小,就是卡尔曼系数。
首先,我们假设要测量的状态量为, 这个状态量可以表述为随时间而变化的量,例如每天的温度变化,可以大致根据之前一天的温度变化规律估计得到今天的温度,这个温度变化规律可以表述为一个计算矩阵。
(1)
其中为转换矩阵,
表示
时刻的噪声,且该噪声服从高斯分布。
为估计值,即根据t-1时刻估计k时刻的状态值。
同时今天的温度可以测量出来,如测量温度可以用温度传感器来测量,但是温度传感器的测量是因为温度改变了电阻的阻值,所以根据电压电流以及电阻随温度的变化曲线而计算出来的。在卡尔曼模型中,这一公式可以表示为如下等式
(2)
其中,
是通过测量的量(温度)
对应到上述的例子中温度传感器的电阻阻值。
是测量矩阵,用来将测量的量转换成要估计的量。
是测量过程中存在的误差。同样的,
也是服从高斯分布的白噪声。
然后就是卡尔曼滤波的核心思想了,有了这两种方法得到的,那么怎么得到一个更准确的估计值。所以需要将两种方法得到的估计值进行算一下加权平均,就得到了最优的估计值。所以卡尔曼滤波的方法如下:
1: 首先根据模型计算当前时刻的估计值
(3)
2: 然后根据测量矩阵计算当前的测量值的估计值
(4)
3: 然后计算测量值和测量估计值之间的差,并以此作为对最终估计值的调整。从这里可以看出,如果估计的很准,就是说此时
的值和
的值相差很小,那么
对于
的修正也就越少。但是如果估计值和测量值相差很大,那么
对于
的修正也就越大。其中,
是卡尔曼增益,表示滤波器对测量值的信任程度。
(5)
那么如何估计卡尔曼增益,可以用贝叶斯估计的方法推导,也可以用最小二乘法的方式推导,这里用最小二乘法的方式推导
我们假设真实值是,那么卡尔曼滤波计算得到的估计值和真实值之间的协方差
(6)
卡尔曼滤波的估计值和模型的估计值之间的协方差,用来评估两种估计的差别 (7)
根据卡尔曼的估计公式以及测量公式,可以得到
![]()
把上述等式展开,可以得到![]()
所以,如果我们要估计的更准确,那么就要更小,就是说真实值和卡尔曼滤波的估计值之间的协方差最小。不考虑估计值之间的相关,那么协方差矩阵的对角线元素就表示了卡尔曼估计值和真实值之间的方差。接下来就是求方差最小的情况下对应的卡尔曼增益
。可以用矩阵的迹的方法求解
![]()
可以看出,是
的二次函数,所以根据二次函数求极值的方法,对
求导,得到
令,所以有
(8)
把t的结果带入到
的表达式中,有
(9)
所以根据上述的推导计算,可以得到卡尔曼滤波的计算过程:
- 1、首先,根据已知的模型,以及上一时刻的卡尔曼估计值,计算当前时刻的模型预测值
- 2、根据当前的模型预测值,计算对应的协方差
- 3、根据当前的协方差和测量空间的转换矩阵,计算当前时刻的卡尔曼增益 (8)
- 4、根据卡尔曼增益和测量值,计算当前时刻的卡尔曼估计值
- 5、计算了当前时刻的卡尔曼估计值之后,还需要计算当前的估计值和真实值的协方差矩阵,方便下一次计算 (9)
以上就是卡尔曼滤波的基本过程,以及一些简单的推导。总体上说理解卡尔曼滤波应该算一种最优估计的算法。也是应用很广泛的,然后卡尔曼滤波的推导方法也有很多,除了最小二乘法,也可以从贝叶斯估计的角度推导。两者是类似的。
Code
1.4、具体例子步骤说明
先从下面的公式来开始讲解:
其中下标k是指状态,这里我们可以把它看成间隔,比如k=1指1ms,k=2指2ms。我们的目的就是要找到在状态k时X的估计。在公式中就是真实测量值。我们要牢记,这些测量值并不可靠。(如果这些测量值是可靠的,那么我们就没必要学kalman filter了:))。
指卡尔曼增益(这是整个公式中的核心点)。
就是上一状态时的估计。
在上述公式中,我们唯一未知的量就是卡尔曼增益。像测量值及上一状态估计,我们都已经知道了。当然了,求出卡尔曼增益并不简单,但是我们有方法来解决它。
我们从另一角度来思考,让我们假设卡尔曼增益为0.5,我们会得到什么呢?它就是个简单的平均!换句话说,我们应该找到对应于每个状态的更加智能化的卡尔曼增益系数。归根结底就是:

卡尔曼滤波器为每个结果状态找到最优的平均因子。 不知怎的,还记得一些关于过去的状态。
1.4.1 Step1 构建模型
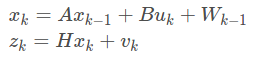
1.2.2 Step2 开始处理
如何决定必要的参数和初始值。
我们有两个不同的方程组:时间更新(预测)及测量更新(校准)。两个方程组合都是应用在第k
个状态
我们在步骤一中建立模型,因此我们知道矩阵A,B和H。很可能,他们都是数值常量。并且他们极可能都是数值1.

最痛苦的事儿就是确定R和Q了。R还相对比较容易找出,因为,通常来讲,我们对环境中的噪声还是比较确定的。
但是寻找Q就并不明显了。在这个阶段,我们并不能给你一个指定的方法。
还需要知道和
的估计
P为协方差,K为增益。
1.4.3 Step3 迭代
在我们收集了我们需要的所有信息后,我们开始处理流程,现在我们可迭代估计。我们要牢记上一状态的估计将成为当前状态的估计的输入。

1.4.4 一个简单的例子
现在估计一个标量随机常数,例如来自某个信号源的“电压读数”。假设它有一个恒定的a V电压,但是我们读数会不准确,可能会读高了,也有可能读低了。我们假设测量噪声的的标准差为0.1 V。(R=0.1)
现在我们来构建我们的模型:

就像我之前说的,我们可以把方程简化成非常简单的形式。
- 首先,我们有一个一维的信号的问题,因此我们模型中的每个系数(A,B,H)都是数值,而不是矩阵。
- 我们并没有控制信号
- 因为信号是一个常数,那么常数A=1,因为我们已经知道下一个值等于先前的值。我们很幸运,在这个例子中我们有一个恒定的值,但是即使它具有其他任何线性性质,我们都可以将它假设成1.
- 值H=1,因为我们知道测量值是由状态值和一些噪声组成的。你很少会遇到现实生活中,H与1不相同的情况
最后,我们假设我们得到了下面的测量值

我们应该从某处开始,比如说k=0。我们应该找到或者假设某个初始状态。这里我们给出了一些初始值。我们假设并且
,那么为什么我们不选择
呢?这很简单。如果我们这样选择,那么就意味着环境中不存在噪声,而这个假设将导致在k状态下X的所有结果估计值为0(保留初始状态),所以我们一般不取
我们来写时间更新和测量更新方程
我们来写时间更新和测量更新方程 (R? 如何确定? R 为测量误差 0.1 参见公式(2))

每一轮计算的步骤:

二、Unscented Kalman Filter(无迹卡尔曼滤波)
参考:
-
无味卡尔曼滤波——非线性UKF-Matlab 详细的代码实现
-
Object Tracking with Sensor Fusion-based Unscented Kalman Filter 论文与代码 机器人轨迹
2.1 无迹卡尔曼滤波的主要流程如下:
2.1.1 计算转换模型和编码模型
1、建立转换模型,可以是非线性也可以是线性,这里用线性模型:
2、建立编码模型,也可以是线性或非线性模型:
2.1.2 无迹卡尔曼的预测和更新
根据上述模型和训练集数据,用最小二乘法或其他的拟合方法,得到模型参数,然后开始无迹卡尔曼的预测和更新阶段
-
根据模型预测
-
预测
的协方差
-
用采样点估计当前协方差矩阵,先采样2d+1个点,并保证中心点的值为
-
计算采样点的权重值
-
根据转换矩阵,采样点,计算观测值和测量值的关系
-
根据采样点估计的观测值,计算观测值zz zz的方差,以及观测值zz zz和测量值xx xx的协方差
-
根据计算的协方差,可以计算Kalman增益
-
用Kalman增益计算最有估计值
以上就是无迹卡尔曼滤波的主要步骤。是对Kalman Filter的一种改进,通过引入UT变换,用采样的方式得到非线性模型的均值和方差。是一种很巧妙的计算方法。
代码链接
Unscented Kalman Filter
2.2 UKF另一个说明
2.2.1 Unscented Transform
步骤:
首先选择一组点,称为sigma点


然后通过非线性函数映射这些点:
最后通过对映射点计算高斯分布形式,和每个sigma点的权重:

2.2.2 sigma点的选择
选择的sigma点满足以下式子:
第一个点选择均值,其余点根据另外两个式子选择:
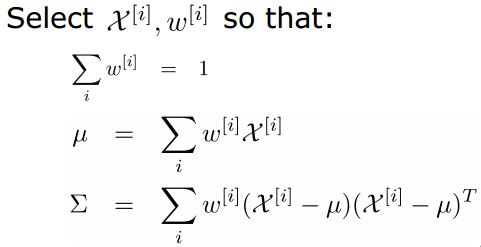

weights的选择:
最后计算高斯模型形式:

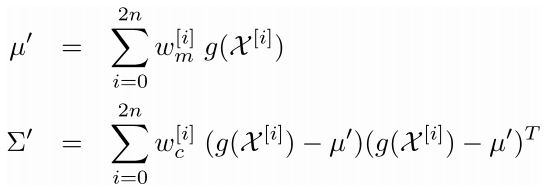
在上面的过程中有一些参数没有确定,这些参数的选择不唯一,但是有一些建议:

2.2.3 UKF算法
prediction过程:

correction过程:

3、OPENCV实现
参考例子
我们把这5个式子可分成三大部分看:
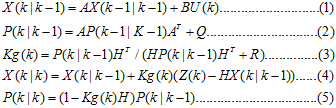
公式和opencv对应关系的讲解:
首先对于离散控制过程的系统,其系统状态和系统测量值可进行以下表示:
X(k): k时刻系统状态
A: 状态转移矩阵,对应opencv里kalman滤波器的transitionMatrix矩阵
B: 控制输入矩阵,对应opencv里kalman滤波器的controlMatrix矩阵
U(k): k时刻对系统的控制量
Z(k): k时刻的测量值
H: 系统测量矩阵,对应opencv里kalman滤波器的measurementMatrix矩阵
W(k):系统过程噪声,为高斯白噪声,协方差为Q,对应opencv里的kalman滤波器的processNoiseCov矩阵
V(k): 测量噪声,也为高斯白噪声,协方差为R,对应opencv里的kalman滤波器的measurementNoiseCov矩阵
对于满足上面的条件(线性随机微分系统,过程和测量都是高斯白噪声),卡尔曼滤波器是最优的信息处理器。
以上便是核心的5个公式。
第一部分:
式(1)-(2): 预测值的计算
式(1): 计算基于k-1时刻状态对k时刻系统状态的预测值
X(k|k-1): 基于k-1时刻状态对k时刻状态的预测值,对应opencv里kalman滤波器的predict()输出,即statePre矩阵
X(k-1|k-1):k-1时刻状态的最优结果,对应opencv里kalman滤波器的上一次状态的statePost矩阵
U(k): k时刻的系统控制量,无则为0
A: 状态转移矩阵,对应opencv里kalman滤波器的transitionMatrix矩阵
B: 控制输入矩阵,对应opencv里kalman滤波器的controlMatrix矩阵
/**********************************************************************************************************************************/
式(2): 计算X(k|k-1)对应的协方差的预测值
P(k|k-1): 基于k-1时刻的协方差计算k时刻协方差的预测值,对应opencv里kalman滤波器的errorCovPre矩阵 (predict预测)
P(k-1|k-1):k-1时刻协方差的最优结果,对应opencv里kalman滤波器的上一次状态的errorCovPost矩阵 (convariance协方差)
Q: 系统过程噪声协方差,对应opencv里kalman滤波器的processNoiseCov矩阵
/***********************************************************************************************************************************/
第二部分:
式(3): 增益的计算
Kg(k):k时刻的kalman增益,为估计量的方差占总方差(估计量方差和测量方差)的比重,对应opencv里kalman滤波器的gain矩阵
H: 系统测量矩阵,对应opencv里kalman滤波器的measurementMatrix矩阵
R: 测量噪声协方差,对应opencv里的kalman滤波器的measurementNoiseCov矩阵
/************************************************************************************************************************************/
第三部分:
式(4)--(5): k时刻的更新
式(4): 计算k时刻系统状态最优值
X(k|k): k时刻系统状态的最优结果,对应opencv里kalman滤波器的k时刻状态的statePost矩阵
Z(k): k时刻系统测量值
式(5): 计算k时刻系统最优结果对应的协方差
P(k|k): k时刻系统最优结果对应的协方差,对应opencv里kalman滤波器的errorCovPost矩阵
./************************************************************************************************************************************/
例如:KalmanFilter KF(stateNum, measureNum, 0);
Fk : KF.transitionMatrix
Hk : KF.measurementMatrix
Qk : KF.processNoiseCov
Rk : KF.measurementNoiseCov
Pk : KF.errorCovPost
有时也需要定义Bk : KF.controlMatrix















 645
645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









