







💡💡💡本文独家改进:DCNv4更快收敛、更高速度、更高性能,完美和YOLO11结合,助力涨点
DCNv4优势:(1) 去除空间聚合中的softmax归一化,以增强其动态性和表达能力;(2) 优化存储器访问以最小化冗余操作以加速。这些改进显著加快了收敛速度,并大幅提高了处理速度,DCNv 4实现了三倍以上的前向速度。
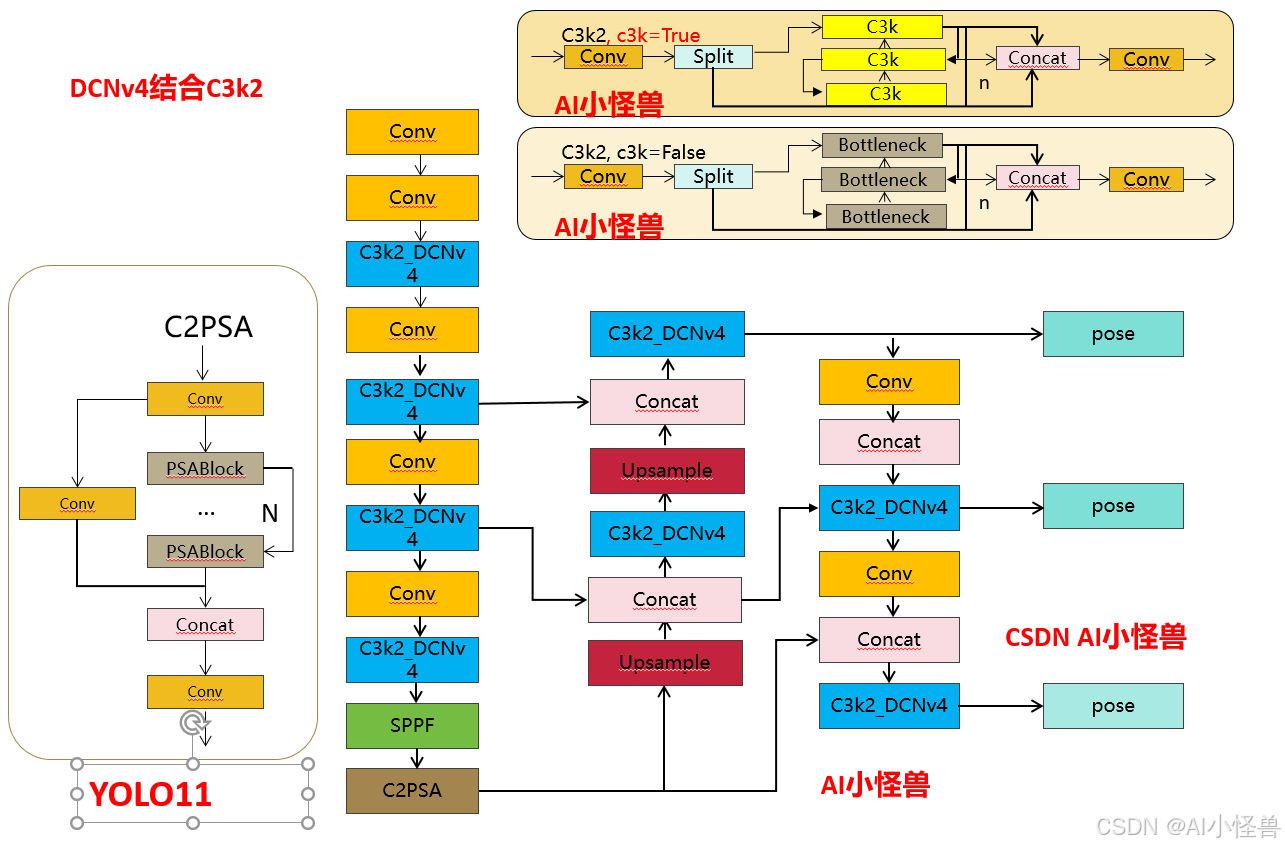
💡💡💡如何跟YOLO11结合:1)和C3k2创新性结合
💡💡💡 DCNv4结合C3k2,Mask mAP50 从原始的0.673 提升至0.681
《YOLOv11魔术师专栏》将从以下各个方向进行创新:
【原创自研模块】【多组合点优化】【注意力机制】【卷积魔改】【block&多尺度融合结合】【损失&IOU优化】【上下采样优化 】【小目标性能提升】【前沿论文分享】【训练实战篇】
【pose关键点检测】【yolo11-seg分割】
定期向订阅者提供源码工程,配合博客使用。
订阅者可以申请发票,便于报销
💡💡💡为本专栏订阅者提供创新点改进代码,改进网络结构图,方便paper写作!!!
💡💡💡适用场景:红外、小目标检测、工业缺陷检测、医学影像、遥感目标检测、低对比度场景
💡💡💡适用任务:所有改进点适用【检测】、【分割】、【pose】、【分类】等
💡💡💡全网独家首发创新,【自研多个自研模块】,【多创新点组合适合paper 】!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
🚀🚀🚀 本项目持续更新 | 更新完结保底≥80+ ,冲刺100+ 🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉
⭐⭐⭐专栏涨价趋势 159 ->199->259->299,越早订阅越划算⭐⭐⭐
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8、Yolov9等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
1.YOLO11介绍
Ultralytics YOLO11是一款尖端的、最先进的模型,它在之前YOLO版本成功的基础上进行了构建,并引入了新功能和改进,以进一步提升性能和灵活性。YOLO11设计快速、准确且易于使用,使其成为各种物体检测和跟踪、实例分割、图像分类以及姿态估计任务的绝佳选择。


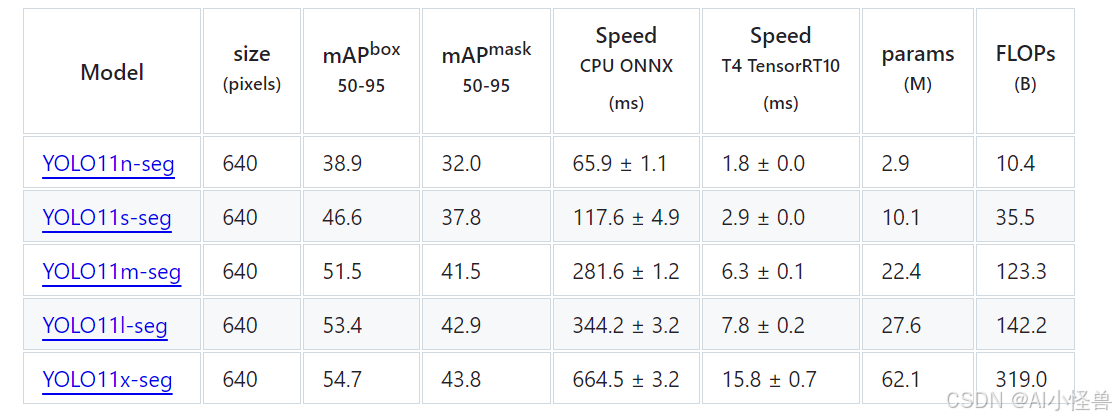
Segmentation 官方在COCO数据集上做了更多测试:
2.数据集介绍
道路裂纹分割数据集是一个全面的4029张静态图像集合,专门为交通和公共安全研究而设计。它非常适合自动驾驶汽车模型开发和基础设施维护等任务。该数据集包括训练、测试和验证集,有助于精确的裂缝检测和分割。
训练集3712张,验证集200张,测试集112张

标签可视化:
3.如何训练YOLO11-seg模型
3.1 修改 crack-seg.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# Crack-seg dataset by Ultralytics
# Documentation: https://docs.ultralytics.com/datasets/segment/crack-seg/
# Example usage: yolo train data=crack-seg.yaml
# parent
# ├── ultralytics
# └── datasets
# └── crack-seg ← downloads here (91.2 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/ultralytics-seg/data/crack-seg # dataset root dir
train: train/images # train images (relative to 'path') 3717 images
val: valid/images # val images (relative to 'path') 112 images
test: test/images # test images (relative to 'path') 200 images
# Classes
names:
0: crack
3.2 如何开启训练
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/11/yolo11-seg.yaml')
#model.load('yolov8n.pt') # loading pretrain weights
model.train(data='data/crack-seg.yaml',
cache=False,
imgsz=640,
epochs=200,
batch=16,
close_mosaic=10,
device='0',
optimizer='SGD', # using SGD
project='runs/train',
name='exp',
)
3.3 训练结果可视化
YOLO11-seg summary (fused): 265 layers, 2,834,763 parameters, 0 gradients, 10.2 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 7/7 [00:07<00:00, 1.06s/it]
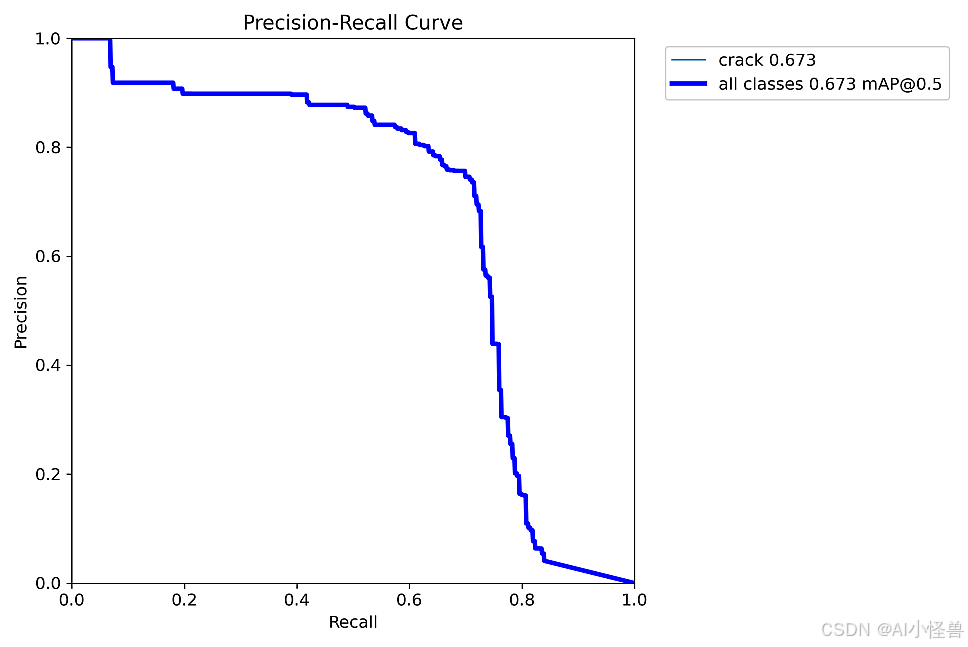
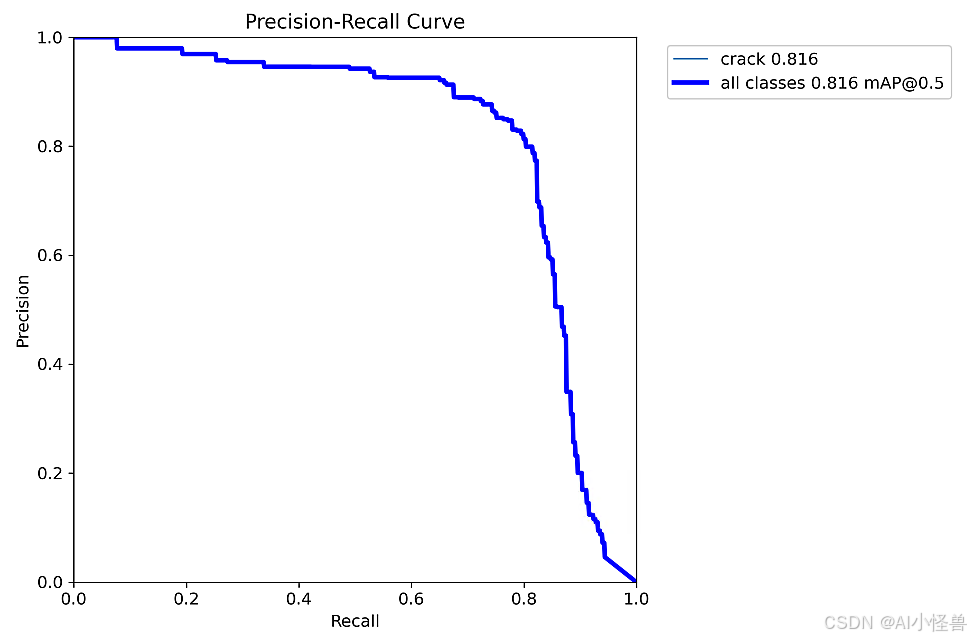
all 200 249 0.83 0.784 0.816 0.632 0.746 0.707 0.673 0.228
Mask mAP50 为 0.673
MaskPR_curve.png
BoxPR_curve.png
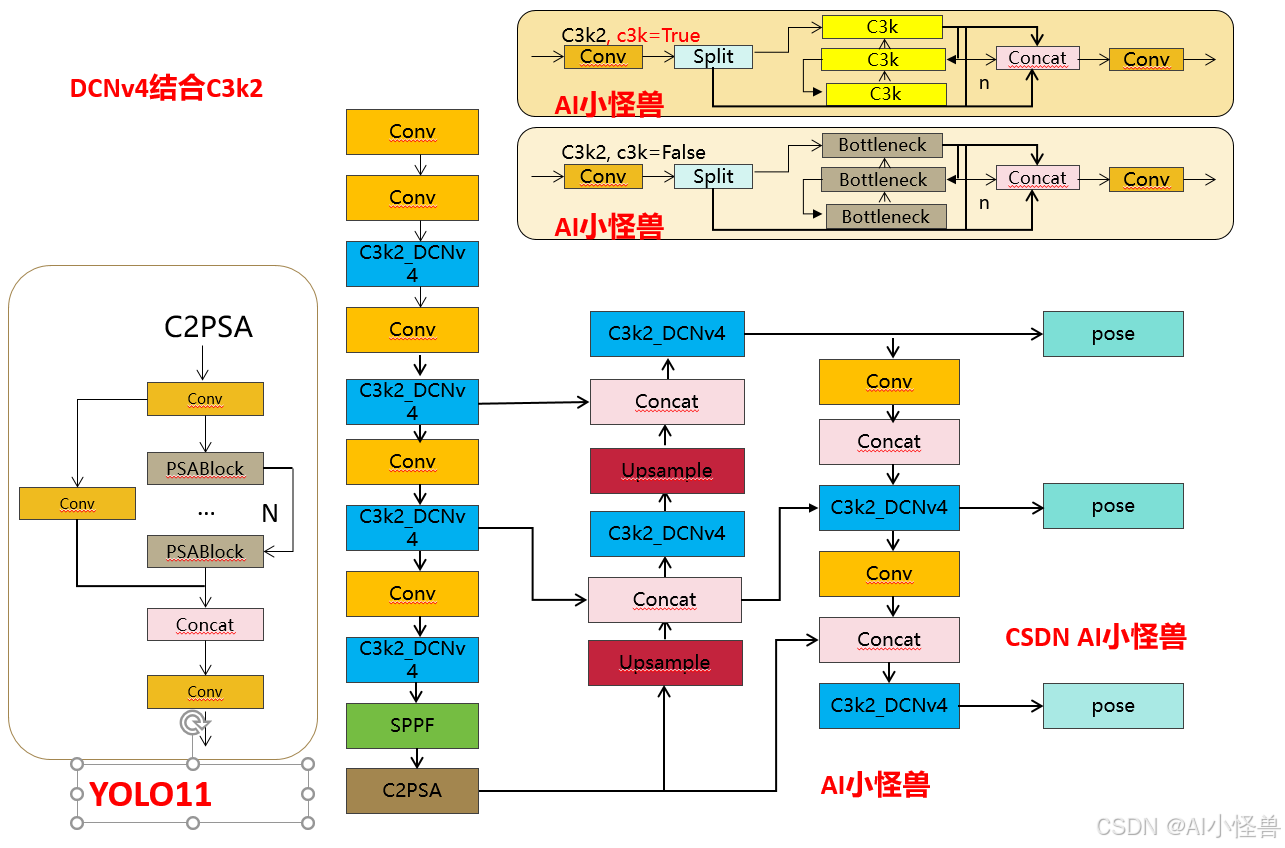
3.4 DCNv4结合C3k2
源码链接:YOLO11涨点优化:卷积魔改 | DCNv4更快收敛、更高速度、更高性能,效果秒杀DCNv3、DCNv2等 ,助力检测_yolov11增加小波卷积-CSDN博客

论文: https://arxiv.org/pdf/2401.06197.pdf
摘要:我们介绍了可变形卷积v4 (DCNv4),这是一种高效的算子,专为广泛的视觉应用而设计。DCNv4通过两个关键增强解决了其前身DCNv3的局限性:去除空间聚合中的softmax归一化,增强空间聚合的动态性和表现力;优化内存访问以最小化冗余操作以提高速度。与DCNv3相比,这些改进显著加快了收敛速度,并大幅提高了处理速度,其中DCNv4的转发速度是DCNv3的三倍以上。DCNv4在各种任务中表现出卓越的性能,包括图像分类、实例和语义分割,尤其是图像生成。当在潜在扩散模型中与U-Net等生成模型集成时,DCNv4的性能优于其基线,强调了其增强生成模型的可能性。在实际应用中,将InternImage模型中的DCNv3替换为DCNv4来创建FlashInternImage,无需进一步修改即可使速度提高80%,并进一步提高性能。DCNv4在速度和效率方面的进步,以及它在不同视觉任务中的强大性能,显示了它作为未来视觉模型基础构建块的潜力。
图1所示。(a)我们以DCNv3为基准显示相对运行时间。DCNv4比DCNv3有明显的加速,并且超过了其他常见的视觉算子。(b)在相同的网络架构下,DCNv4收敛速度快于其他视觉算子,而DCNv3在初始训练阶段落后于视觉算子。

YOLO11-seg-C3k2_DCNv4 summary (fused): 311 layers, 2,956,267 parameters, 0 gradients, 10.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Mask(P R mAP50 mAP50-95): 100%|██████████| 7/7 [00:08<00:00, 1.19s/it]
all 200 249 0.875 0.73 0.808 0.647 0.796 0.663 0.681 0.232
Mask mAP50 从原始的0.673 提升至0.681


















 3449
3449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











