







大模型中的“快思考”与“慢思考”:理解AI的两种思维模式
近年来,大型语言模型(LLMs)取得了惊人的进展,它们不仅能生成流畅的文本,还能进行简单的推理和对话。当我们惊叹于AI的智能时,或许会好奇:大模型是如何思考的? 其实,我们可以借鉴心理学中的一个经典理论——“快思考”与“慢思考”,来更好地理解大模型的思维模式。
什么是“快思考”与“慢思考”?
“快思考”和“慢思考”的概念源于心理学家丹尼尔·卡尼曼在他的著作《思考,快与慢》中提出的双系统理论。这个理论认为,人类的思考过程可以分为两个系统:
-
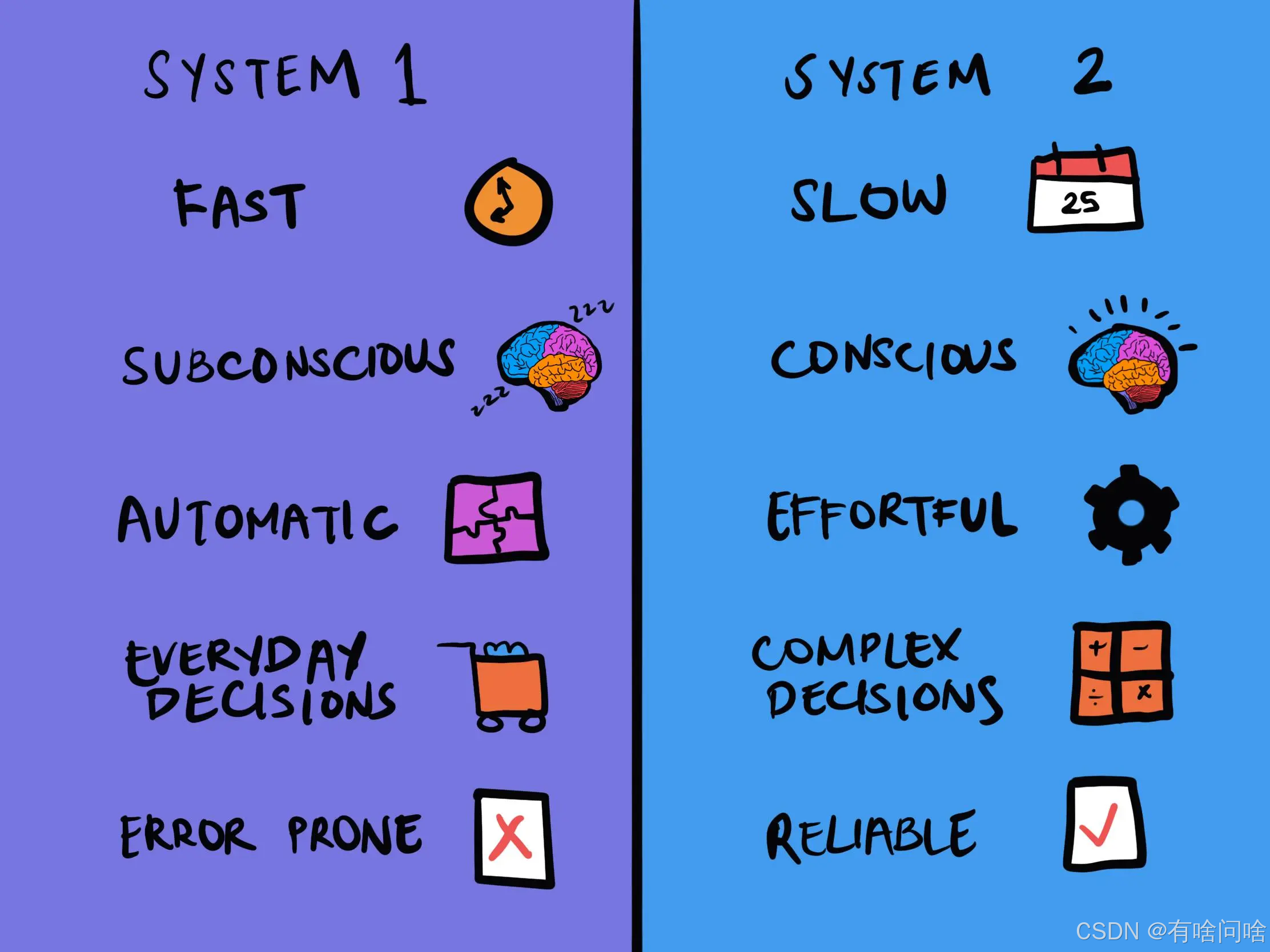
系统1:快思考 (Fast Thinking):
- 特点:快速、自动、无意识、直觉性强、耗能少。
- 运作方式:依赖于经验、习惯和启发式方法,不需要刻意控制。
- 例子:识别熟悉的面孔、阅读简单的句子、躲避突然出现的障碍物等。
-
系统2:慢思考 (Slow Thinking):
- 特点:缓慢、费力、有意识、逻辑性强、耗能多。
- 运作方式:需要集中注意力、进行逻辑推理和分析,需要刻意控制。
- 例子:解决复杂的数学问题、撰写详细的报告、学习新的技能等。
将“快思考”与“慢思考”的概念引入到大模型领域,可以帮助我们理解不同类型的大模型以及它们在处理任务时的不同方式。
大模型中的“快思考”:快速生成与模式识别
在大型语言模型中,“快思考”可以类比为模型快速生成文本、识别模式和进行初步判断的能力。这种“快思考”主要依赖于模型在海量数据中学习到的统计规律和模式。
特点:
- 速度快:模型能在极短的时间内生成回复或完成任务。
- 效率高:计算成本相对较低,适合处理大规模、实时的任务。
- 基于模式匹配:依赖于在训练数据中学习到的模式和关联性。
举个栗子:
虽然很难用一个简单的公式完全概括“快思考”,但我们可以用一个简化的模型来理解其核心思想。假设大模型学习到了一个简单的概率分布 P ( w i ∣ w i − 1 ) P(w_i | w_{i-1}) P(wi∣w
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











