







本系列为MIT Gilbert Strang教授的"数据分析、信号处理和机器学习中的矩阵方法"的学习笔记。
- Gilbert Strang & Sarah Hansen | Sprint 2018
- 18.065: Matrix Methods in Data Analysis, Signal Processing, and Machine Learning
- 视频网址: https://ocw.mit.edu/courses/18-065-matrix-methods-in-data-analysis-signal-processing-and-machine-learning-spring-2018/
- 关注 下面的公众号,回复“ 矩阵方法 ”,即可获取 本系列完整的pdf笔记文件~
内容在CSDN、知乎和微信公众号同步更新

- Markdown源文件暂未开源,如有需要可联系邮箱
- 笔记难免存在问题,欢迎联系邮箱指正
Lecture 0: Course Introduction
Lecture 1 The Column Space of A A A Contains All Vectors A x Ax Ax
Lecture 2 Multiplying and Factoring Matrices
Lecture 3 Orthonormal Columns in Q Q Q Give Q ′ Q = I Q'Q=I Q′Q=I
Lecture 4 Eigenvalues and Eigenvectors
Lecture 5 Positive Definite and Semidefinite Matrices
Lecture 6 Singular Value Decomposition (SVD)
Lecture 7 Eckart-Young: The Closest Rank k k k Matrix to A A A
Lecture 8 Norms of Vectors and Matrices
Lecture 9 Four Ways to Solve Least Squares Problems
Lecture 10 Survey of Difficulties with A x = b Ax=b Ax=b
Lecture 11 Minimizing ||x|| Subject to A x = b Ax=b Ax=b
Lecture 12 Computing Eigenvalues and Singular Values
Lecture 13 Randomized Matrix Multiplication
Lecture 14 Low Rank Changes in A A A and Its Inverse
Lecture 15 Matrices A ( t ) A(t) A(t) Depending on t t t, Derivative = d A / d t dA/dt dA/dt
Lecture 16 Derivatives of Inverse and Singular Values
Lecture 17 Rapidly Decreasing Singular Values
Lecture 18 Counting Parameters in SVD, LU, QR, Saddle Points
Lecture 19 Saddle Points Continued, Maxmin Principle
Lecture 20 Definitions and Inequalities
Lecture 21 Minimizing a Function Step by Step
Lecture 22 Gradient Descent: Downhill to a Minimum
Lecture 23 Accelerating Gradient Descent (Use Momentum)
Lecture 24 Linear Programming and Two-Person Games
Lecture 25 Stochastic Gradient Descent
Lecture 26 Structure of Neural Nets for Deep Learning
Lecture 27 Backpropagation: Find Partial Derivatives
Lecture 28 Computing in Class [No video available]
Lecture 29 Computing in Class (cont.) [No video available]
Lecture 30 Completing a Rank-One Matrix, Circulants!
Lecture 31 Eigenvectors of Circulant Matrices: Fourier Matrix
Lecture 32 ImageNet is a Convolutional Neural Network (CNN), The Convolution Rule
Lecture 33 Neural Nets and the Learning Function
Lecture 34 Distance Matrices, Procrustes Problem
Lecture 35 Finding Clusters in Graphs
Lecture 36 Alan Edelman and Julia Language
文章目录
Lecture 7 Eckart-Young: The Closest Rank k Matrix to A
This is a pretty key lecture
- about principal component analysis (PCA)
- a major tool in understanding a matrix of data
7.1 Review SVD & Propose Eckart-Young Theorem
-
A
=
U
Σ
V
T
=
σ
1
u
1
v
1
T
+
.
.
.
+
σ
r
u
r
v
r
T
A = U \Sigma V^T = \sigma_1 u_1 v_1^T + ... + \sigma_r u_r v_r^T
A=UΣVT=σ1u1v1T+...+σrurvrT
-
any matrix A A A could be broken into r rank 1 pieces
-
r r r: the rank of the matrix A A A
-
u u u and r r r: orthonomal
-
how to get important information:
❌ (People say, in machine learning, if you learned all of the training data, you have not learned anything ⇒ \Rightarrow ⇒ just copy and overfitting)
🚩 The whole point of DNN and the process of ML is to learn the import facts about the data
🚩 The most basic stage of that: TOP (Largest) k singular values ⇒ \Rightarrow ⇒ A k = U k Σ k V k T = σ 1 u 1 v 1 T + . . . + σ k u k v k T A_k = U_k \Sigma_k V_k^T = \sigma_1 u_1 v_1^T + ... + \sigma_k u_k v_k^T Ak=UkΣkVkT=σ1u1v1T+...+σkukvkT
✅ One Theorem here: A k A_k Ak using the first k pieces of the SVD is the best approximation to A A A of rank k k k ⇒ \Rightarrow ⇒ 🚩 This really says why SVD is perfect
✅ More precisely Definition: (Eckart-Young Theorem) If B has rank k, then ∥ A − B ∥ \| A - B\| ∥A−B∥ ≥ \geq ≥ ∥ A − A k ∥ \|A - A_k\| ∥A−Ak∥ ⇒ \Rightarrow ⇒ a pretty straightform beautiful fact
-
下面要解决的问题:
- 范数:定理中的 ∥ ⋅ ∥ \| \cdot \| ∥⋅∥的含义
- 证明该定理
7.2 Norm of Matrix
本节课介绍的范数的特点: can be comupted by their singular values
-
Pre: Norm of Vectors
-
∥ v ∥ 2 \|v\|_2 ∥v∥2: just the regular lenght of vector ∣ v 1 ∣ 2 + ∣ v 2 ∣ 2 + . . . + ∣ v n ∣ 2 \sqrt{|v_1|^2 + |v_2|^2 + ... + |v_n|^2} ∣v1∣2+∣v2∣2+...+∣vn∣2
🚩 historically goes back to Gauss ⇒ \Rightarrow ⇒ the least squares
🚩 the results would have lot of little components (平方后do not hurt much)
-
∥ v ∥ 1 \|v\|_1 ∥v∥1 = ∣ v 1 ∣ + . . . + ∣ v n ∣ |v_1| + ... + |v_n| ∣v1∣+...+∣vn∣ ⇒ \Rightarrow ⇒ 🚩 getting more and more important & special
🚩 🚩 when you minimize some function using the L 1 L_1 L1 norm
▪ 🚩 tend to be sparse ⇒ \Rightarrow ⇒ mostly zero components
✅ One advantage of the “sparse” : you can understand what its components are ⇒ \Rightarrow ⇒ 如果一个result有很多small components, 解释起来就会很困难( L 2 L_2 L2); 反之( L 1 L_1 L1),则易于解释
-
∥ v ∥ ∞ \|v\|_\infin ∥v∥∞ = max ∣ v i ∣ |v_i| ∣vi∣
-
The property of the norm:
🚩 homogeneous : ∥ C V ∥ = ∣ C ∣ ∥ V ∥ \|CV\| = |C| \|V\| ∥CV∥=∣C∣∥V∥ ⇒ \Rightarrow ⇒ If you double the vector, you should double the norm
✅ triangle inequality : ∥ V + W ∥ ≤ ∥ V ∥ + ∥ W ∥ \|V + W\| \leq \|V\| + \|W\| ∥V+W∥≤∥V∥+∥W∥ ⇒ \Rightarrow ⇒ add the norm of V and W, you get more than the straight norm along the hypotenuse hypotenuse 斜边 ⇒ \Rightarrow ⇒
🚩 上述properties 同样适用于Matrix Norm ↓ \downarrow ↓
-
矩阵范数1: L 2 L_2 L2 Norm
- The largst singular value
- ∥ A ∥ 2 = σ 1 \|A \|_2 = \sigma_1 ∥A∥2=σ1
- Property 1: homogeneous ⇒ \Rightarrow ⇒ ∥ 2 A ∥ 2 = 2 σ 1 \|2 A \|_2 = 2 \sigma_1 ∥2A∥2=2σ1
- Property 2: Triangle inequality ⇒ \Rightarrow ⇒ The largest singular value of A + B A+B A+B ≤ \leq ≤ the largest singular value of A + the largest singular value of B
-
矩阵范数2:Frobenius norm ∥ A ∥ F = ∣ a 11 ∣ 2 + . . . + ∣ a n m ∣ 2 \|A\|_F = \sqrt{|a_{11}|^2 + ... + |a_{nm}|^2} ∥A∥F=∣a11∣2+...+∣anm∣2
- just like the L 2 L_2 L2 vector norm
-
矩阵范数3:Nuclear norm ∥ A ∥ N u c l e a r = σ 1 + σ 2 + . . . + σ r \|A\|_{Nuclear} = \sigma_1 + \sigma_2 + ... + \sigma_r ∥A∥Nuclear=σ1+σ2+...+σr
-
考虑Netflix Competitions: It had movie preferences from many Netflix subscribers ⇒ \Rightarrow ⇒ they give their ranking to a bunch of movies ⇒ \Rightarrow ⇒ none of them had seen all the movies ⇒ \Rightarrow ⇒ So, the matrix of rankings – the ranker and the matrix – is a bery big matrix ⇒ \Rightarrow ⇒ but it got missing entries – if the ranker did not see the movie, 则无法ranking it
-
那么 what is the idea about Netflix?
✅ what would the ranker have said about the post if he had not seen it, but have ranked several other movies
🚩 The Nuclear Norm is the right one to minimize!
-
and MRI
-
-
对于以上三种Matrix Norm, the theorem: A k A_k Ak using the first k pieces of the SVD is the best approximation to A A A of rank k k k is ture
下节课将会对范数进行更加详细的介绍
7.3 About Eckart-Young theorem
没有证明该定理,但是举例说明了该定理的含义和适用范围
-
The above 3 Matrix Norm 适用于该定理 (但并非all Matrix Norm)
-
Why?
-
These 3 norms depend only on the singular values
🚩 ∥ A ∥ 2 \|A\|_2 ∥A∥2 and ∥ A ∥ N u c l e a r \|A\|_{Nuclear} ∥A∥Nuclear obviously depends on singular values
-
Suppose k = 2 k=2 k=2 ⇒ \Rightarrow ⇒ looking among all rank 2 matrices
✅ and the matrix Σ = [ 4 0 0 0 0 3 0 0 0 0 2 0 0 0 0 1 ] \Sigma = \begin{bmatrix} 4 & 0 & 0 & 0 \\ 0 & 3 & 0 & 0 \\ 0 & 0 & 2 & 0 \\ 0 & 0 & 0 & 1 \\ \end{bmatrix} Σ=⎣⎢⎢⎡4000030000200001⎦⎥⎥⎤
🚩 the best approximation of rank 2 Σ 2 = [ 4 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 ] \Sigma_2 = \begin{bmatrix} 4 & 0 & 0 & 0 \\ 0 & 3 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 \\ \end{bmatrix} Σ2=⎣⎢⎢⎡4000030000000000⎦⎥⎥⎤
✅ and an exmple of B = [ 3.5 3.5 0 0 3.5 3.5 0 0 0 0 1.5 1.5 0 0 1.5 1.5 ] B = \begin{bmatrix} 3.5 & 3.5 & 0 & 0 \\ 3.5 & 3.5 & 0 & 0 \\ 0 & 0 & 1.5 & 1.5 \\ 0 & 0 & 1.5 & 1.5 \\ \end{bmatrix} B=⎣⎢⎢⎡3.53.5003.53.500001.51.5001.51.5⎦⎥⎥⎤ ⇒ \Rightarrow ⇒ 一行两个3.5 (1.5) 是为了 keep low rank
-
对于非对角阵 A = U Σ V T A = U \Sigma V^T A=UΣVT
✅ What are the singular values of that matrix A A A? ⇒ \Rightarrow ⇒ did not change! – 4,3,2,1 ⇒ \Rightarrow ⇒ because A = U Σ V T A = U \Sigma V^T A=UΣVT is an SVD form and the diagonal contains diagonal values
🚩 The problem is orthogonally invariant.
✅ These norms are not changed by orthogonal matrices ⇒ \Rightarrow ⇒ Q A = Q U Σ V T = U ′ Σ V T QA = QU\Sigma V^T = U' \Sigma V^T QA=QUΣVT=U′ΣVT (Orthogonal × \times × Orthogonal is Orthogonal)
-
-
These are the key math behind PCA
- An example: 研究身高和年龄的关系
-
(PCA Principal Component Analysis用于拟合可参考相关博客,如 https://xiaotaoguo.com/p/pca-model-fitting/)
-
data matrix A 0 A_0 A0 (如下图)
-
1st step: normalization (get the mean to zero) ⇒ \Rightarrow ⇒ A = A 0 − [ a v e r a g e h e i g h t ; / / a v e r a g e a g e s ] A = A_0 - [average_height;// average_ages] A=A0−[averageheight;//averageages]
🚩 centered the data at ( 0 , 0 ) (0,0) (0,0)
-
How to looking for the best line to fit the data (in the data matrix)? (What is the best linear relationship?)
✅ here is PCA as a linear business (instead of unlinear deep learning method)
-
One way: use least squares (Gauss did it). ⇒ \Rightarrow ⇒ 🚩 使用PCA和使用least squares的区别?
🚩 In PCA, you are measuring perpendicular to the lineperpendicular 垂直 ⇒ \Rightarrow ⇒ involve SVD / σ \sigma σ
🚩 但 least square 则用的竖直距离 ( ∥ A x − b ∥ 2 \|Ax-b\|^2 ∥Ax−b∥2) ⇒ \Rightarrow ⇒ A T A x ^ = A T b A^T A \hat{x} = A^T b ATAx^=ATb (regression problem)
🚩 Sample Covariance matrix A A T A A^T AAT
-
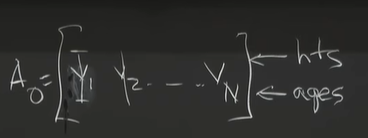
本节小结:
- 给出了 One Theorem: A k A_k Ak using the first k pieces of the SVD is the best approximation to A A A of rank k k k
- 引入并介绍了 向量范数 和 矩阵范数 的概念
- 根据范数的概念,详细说明了 上述定理的含义和应用范围
- 根据上述定理, 引入了PCA ,举例说明了PCA和SVD在数据拟合上的应用
















 523
523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}