






大型语言模型(LLM)现在在各行各业都越来越火了,选对合适的LLM对公司来说超级重要。这不仅仅是看模型有多厉害,还得看它能不能和公司的工作流程还有长远目标完美对接。在这个选择过程中,LLM能处理的上下文长度非常关键。
在LLM的世界里,上下文长度(也叫上下文窗口)就是模型能同时处理的最大标记数。你可以把它想象成模型的记忆力或者注意力范围,这是像ChatGPT和Llama这样的基于变换器的模型的一个基本特性。
标记是模型把单词转换成数字的一种方法,这个过程叫做位置编码。比如,大概130个标记就相当于100个单词。如果模型遇到一个它没见过的词,它会把这个单词拆成好几个标记。
LLM的上下文长度决定了它能接受多少信息作为输入来给出回应。简单来说,上下文长度越大,用户就能在提问时输入更多的信息。
虽然我们习惯上会用单词来衡量LLM的上下文长度,但实际上模型是按标记来计算内容的。通常来说,一个标记大概对应英语里的四个字符或者四分之三的单词。所以,100个标记差不多就是75个单词。
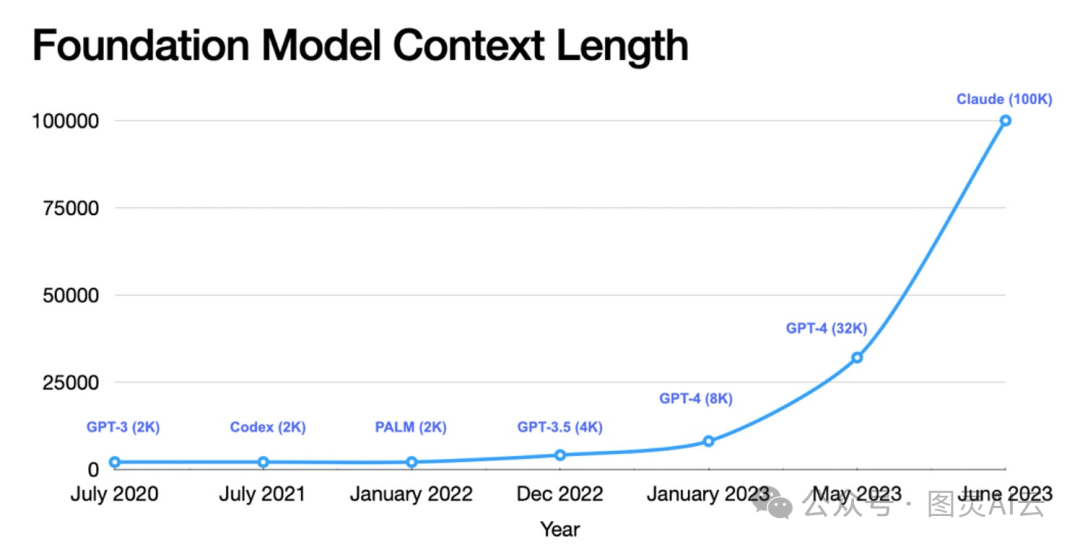
明白了这一点,我们来看看一些最火的LLM的上下文长度:
-
Llama: 2K(2000个标记)
-
Llama 2: 4K(4000个标记)
-
Llama 3: 128K (128000个标记)
-
GPT-3.5-turbo: 4K(4000个标记)。但是,GPT-3.5-16k的上下文长度能达到16K(16000个标记)。
-
GPT-4: 8K(8000个标记)。同样,GPT-4-32k的上下文窗口能到32K(32000个标记)。
-
Mistral 7B: 8K(8000个标记)
-
Palm-2: 8K(8000个标记)
-
Gemini: 32K标记上下文长度,也就是32000个标记。
所以,公司在选择LLM时,得根据自己的需求来考虑这些模型的上下文长度,找到最合适的那一个。
想象一下,如果LLM的上下文窗口变大了,它们就能在回答我们之前,考虑更多的信息,这样它们的回答就会更准确,内容也会更丰富。这对于需要处理很多文字或者需要写出很多东西的应用来说,比如写文章、做摘要或者回答问题,都是非常有用的。
但是,如果上下文窗口变大了,LLM就需要更多的脑力和记忆空间来工作,这就有点像是我们的电脑需要更多的内存和处理器一样。这意味着成本也会增加,所以公司在使用LLM的时候,得考虑一下成本和效果之间的平衡。
总的来说,上下文窗口对于LLM来说就像是它们的视野,视野越宽,它们能做的事情就越多,但同时也需要更多的资源。所以,开发者和公司在使用LLM的时候,就需要好好考虑一下,怎么样让这个视野既够用,又不会让成本太高。
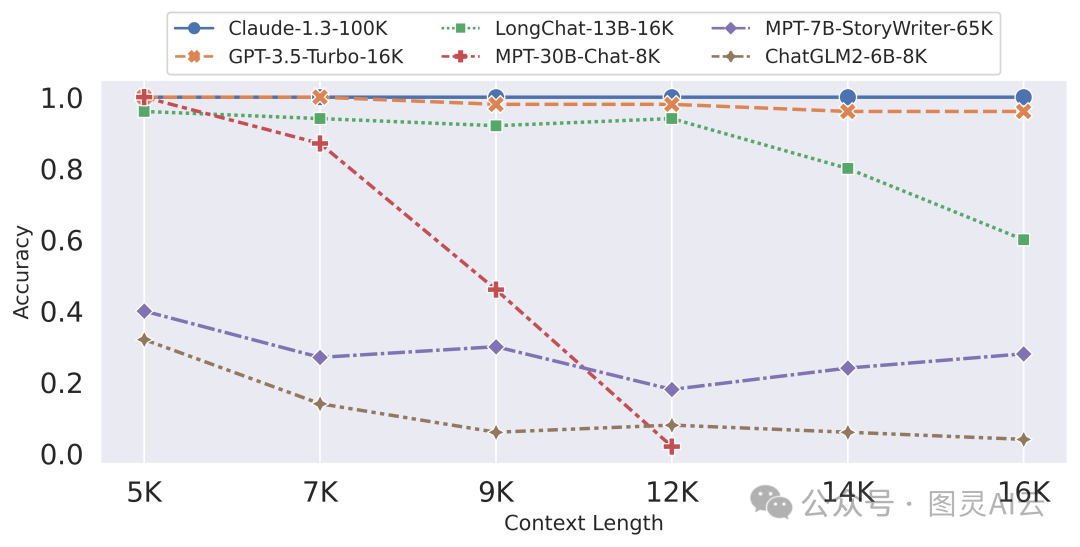
乍一看,大上下文窗口似乎很有优势——只需将所有训练数据喂给模型,让它来做繁重的工作。然而,这种“上下文填充”策略通常伴随着缺点,并且在现实世界中的表现不如预期。
响应的质量可能会恶化,并且产生不相关或无意义的输出的风险,即所谓的“幻觉”,会增加。成本也随着更大的上下文线性上升。处理广泛的上下文需要更多的计算资源,由于LLM提供商按标记收费,长上下文(即更多标记)使得每个查询更昂贵。
研究表明,当LLM在上下文中提供较少但更相关的文档时,会得到更好的结果,而不是大量的未经筛选的文档。
这就是检索系统证明其价值的地方。检索系统已经开发和优化了几十年,专门设计用于大规模提取相关信息,这样做的成本大大降低。此外,这些AI系统的模型参数是明确可调的,与LLM相比,提供了更多的灵活性和优化机会。使用检索系统为LLM提供上下文的策略被称为检索增强生成(RAG)。
想象一下,你有一个超级聪明的助手,它能写文章、回答问题,但有时候它需要更多的信息来给出最好的答案。这时候,RAG就像是给助手装了个超级搜索器,让它能在需要的时候,快速找到网上或者数据库里的资料来帮助回答问题。
这种方法就像是给模型开了个外挂,让它在回答问题时不仅能用自己“脑子里”的东西,还能去外面找更多的信息。这样一来,即使是一些需要特定知识背景的问题,模型也能给出更准确、更丰富的答案。
但是,设计这样的系统可不是一件容易的事。你得考虑很多问题,比如怎么决定哪些信息是最重要的,需要先找;或者是不是先用一个不那么贵的模型来总结信息,然后再让更高级的模型来生成最终的答案。这些问题都需要仔细考虑和测试,才能让系统跑得又快又好。
在实际应用考虑方面,首先你得根据你的应用来决定需要多大的上下文窗口。如果你的应用需要处理很多信息,那就得选一个视野更宽的模型。然后就是运营成本,更大的上下文窗口和RAG会让计算变得更复杂,也就意味着成本会上升。所以,你得根据自己的预算来选择合适的模型。最后就是 模型训练和微调,训练一个能处理大上下文窗口的模型需要很多资源,但是通过特定领域的数据来训练模型,可以让模型在实际应用中表现得更好。
总的来说,上下文窗口和RAG是让LLM变得更强大的关键。它们让模型不仅能处理更多的信息,还能在需要的时候去找更多的资料。这对于开发更复杂、更高效的应用来说非常重要。
所以说,开发者和使用LLM的技术用户需要在上下文窗口的大小、计算资源、应用需求和RAG的使用之间找到平衡。这虽然是个挑战,但也是让人工智能更进一步的关键。



















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









