






大语言模型技术点总结
本文将开源文本大模型中的LLaMA系列和Qwen系列的各个版本技术点对比总结成表格形式,方便查看和阅览,然后基于一些共性的技术点进行详细介绍。
一、LLaMA
1、模型技术点对比总结
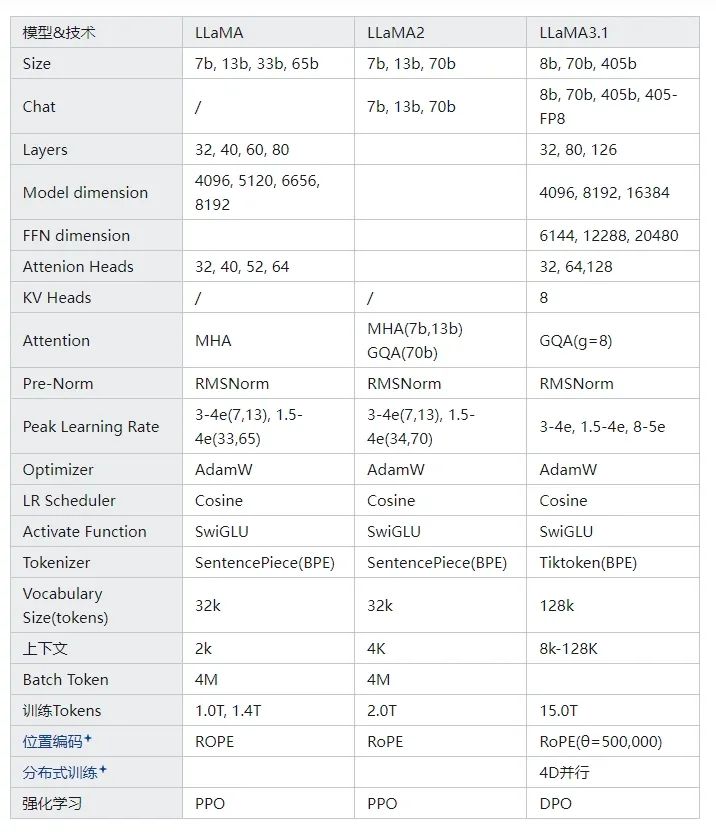
llama系列是Meta开源的文本大模型,采用Transformer Decoder-Only架构,通过阅读几个版本的技术报告,总结一些核心技术数据选取如下表:
2、模型架构与训练
1)LLaMA模型架构,LLaMA1LLaMA2LLaMA3在模型架构上几乎没有变化。模型架构图如下:
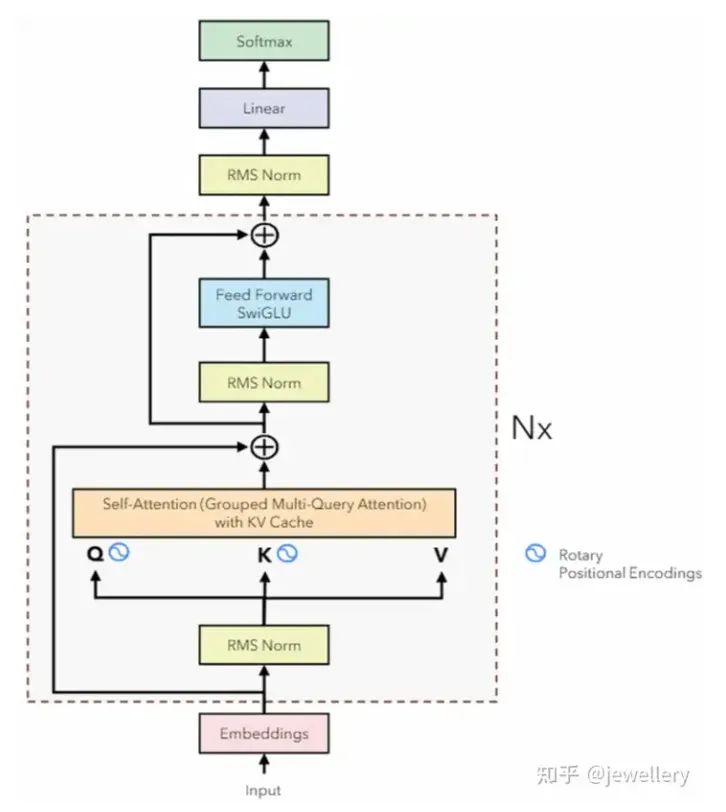
LLaMA Model Architecture
2)LLaMA2从预训练到Chat训练全流程,如下图:

Overall Training of LLaMA 2-Chat
3)LLaMA3的预训练和后训练流程

Pre-Training of LLaMA 3

Post-Training of LLaMA 3 (Rejection Sampling, SFT, DPO)
二、Qwen
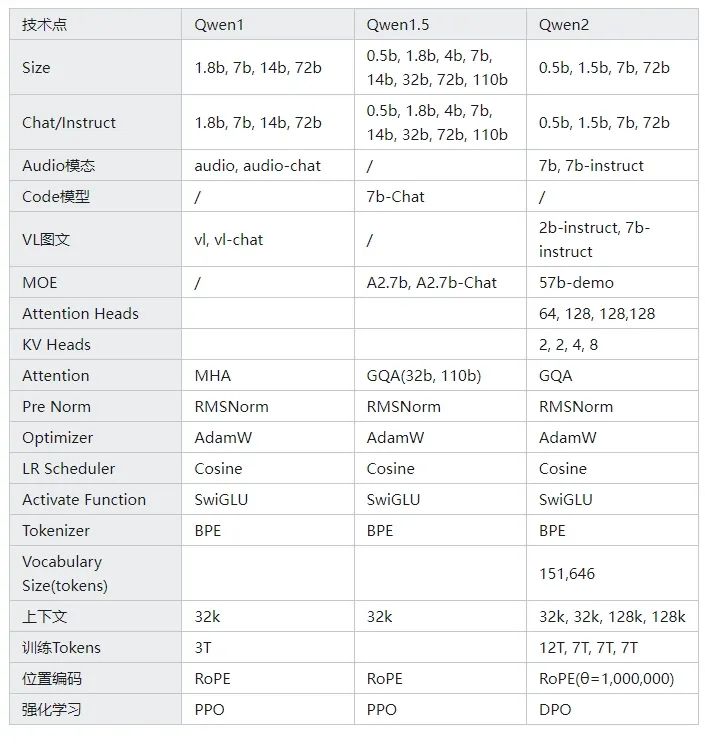
qwen系列是国内开源比较完整,商业和微调都比较常用的文本大模型,采用Transformer Decoder-Only架构,next-token prediction训练,总结几个系列的核心技术数据:
三、 技术点一览
3.1 量化方法
大模型压缩技术:剪枝、知识蒸馏、量化、低秩分解
模型量化是指以较低的推理精度损失将连续取值(通常为float32或者大量可能的离散值)的浮点型权重近似为有限多个离散值(通常为int8)的过程。量化对象为模型的参数(embedding, 权重weight, 输入input, 输出output),量化形式包括线性量化和非线性量化。
量化分类:
1)QAT(量化感知训练,Quantization Aware Training),在模型训练过程中加入伪量化算子通过训练时统计输入输出的数据范围可以提升量化后模型的精度,适用于对模型精度要求较高的场景,让大模型在训练过程中就适应低精度的表示,增强其处理量化引起的精度损失的能力,使它在量化过程之后保持更高性能。
2)QAF(量化感知微调,Quantization-Aware Fine-tuning),将量化感知训练放在微调阶段里,在模型压缩和保持性能之间取得平衡。
3)PTQ(训练后量化,Post Training Quantization),在大模型训练完成之后进行量化,少量校准数据,适用于追求高易用性和缺乏训练资源的场景。减少大模型的存储和计算复杂度,这种方式精度损失略大。
参考:Training with quantization noise for extreme model compression
3.2 RoPE
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

3.3 4D并行
4D并行为4种并行手段一起使用:TP,CP,PP,DP
-
DP:数据并行,通过数据集切分成不同的GPU分别训练,每个GPU上都有一个完整模型副本,反向传播之后,模型梯度进行聚合,在不同GPU上模型参数保持同步。实现方式:PyTorch DDP
-
TP:张量并行,是模型并行的一种形式,是在一个操作中进行并行计算,比如矩阵乘法,模型层内并行。实现:Megatron-LM(1D)
-
PP:流水线并行,是模型并行的一种形式,将模型按层分割成若干块,分到不同的GPU上,是在模型各层之间进行并行计算。缺点:后一个阶段需要等前一个阶段执行完毕,训练设备容易出现空闲状态。
-
CP:序列(上下文)并行,实现:Megatron-LM
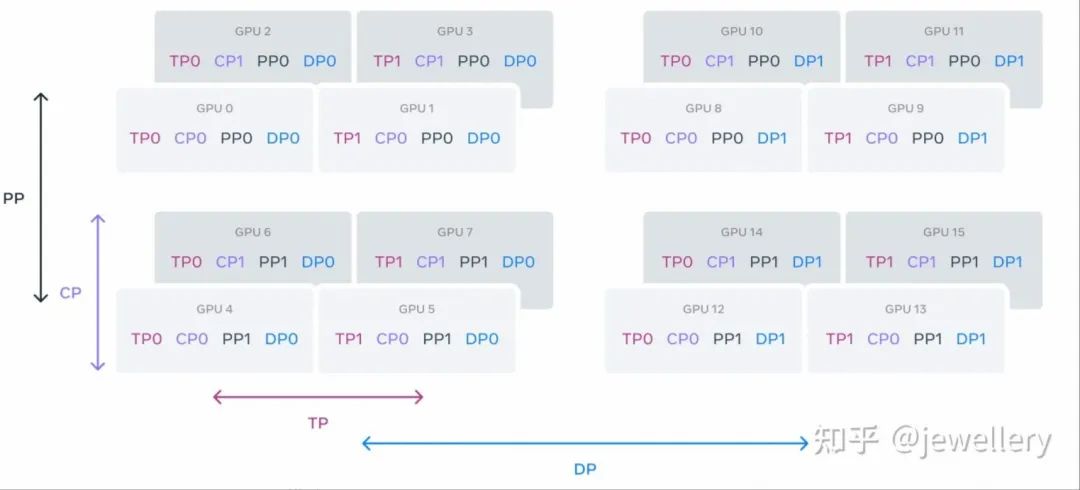
LLaMA3:Illustration of 4D parallelism
3.4 Attention
a) Transformer中的三种注意力机制:Self Attention, Cross Attention, Causal Masked Attention
编码器中的Attention为Self Attention(自注意力),q, k, v三个线性向量都是来自于同一个输入query,是针对同一个序列,使用缩放点积注意力(Scaled Dot-Product Attention)计算注意力分数,从而对值向量进行加权求和,得到输入序列每个token的加权表示。
解码器中的接受编码器结果的Cross Attention(交叉注意力),q来自解码器已经生成的序列,k, v来自编码器输出序列,实现跨序列交互。
解码器最下方的Causal Masked Attention(因果注意力),q, k, v均来自已经生成的序列,并且使用掩码遮掩当前位置之后的序列内容,在生成过程中不会受到未来信息的影响。
b) Transformer的三种注意力的多头形式(也是Transformer在大模型中实际使用的)
-
编码器输入序列通过Multi-Head Self Attention(多头自注意力)计算注意力权重。
-
编码器和解码器两个序列通过Multi-Head Cross Attention(多头交叉注意力)进行注意力转移。
-
解码器的单个序列通过Multi-Head Causal Self-Attention(多头因果自注意力)进行注意力计算。
MHA(Multi-Head Attention):多头注意力,多个注意力头并行运行,每个头都会独立计算注意力权重和输出,然后将所有头输出拼接起来(加权平均)得到最终输出。
#### Multi head attention 代码实现:
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.wq = nn.Linear(embed_dim, embed_dim)
self.wk = nn.Linear(embed_dim, embed_dim)
self.wv = nn.Linear(embed_dim, embed_dim)
self.wo = nn.Linear(embed_dim, embed_dim)
def split(self, hidden):
batch_size = hidden.shape[0]
x = hidden.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
return x
def forward(self, hidden_state, mask=None):
batch_size = hidden_states.size(0)
# 线性变换
q, k, v = self.wq(hidden_states), self.wk(hidden_states), self.wv(hidden_states)
# 多头切分
q, k, v = self.split(q), self.split(k), self.split(v)
# 注意力计算
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attention = torch.softmax(scores, dim=-1) # 权重转换
output = torch.matmul(attention, v) # 注意力权重与v加权求和
# 拼接多头
output = output.transpose(1, 2).contiguout().view(batch_size, -1, self.num_heads * self.head_dim)
# 线性变换
output = self.wo(output)
return output
x = torch.ones(3, 6, 32)
atten = MultiHeadAttention(32, 8)
y = atten(x)
print(y.shape)
c) 对KV Cache的优化:MQA、GQA、MLA
-
KV Cache:大模型在next token递归生成时,新预测的token不会影响之前的k, v计算,将这部分计算结果存储下来就是KV Cache. 它可以提升计算效率,但是却需要额外的显存占用,因此也需要不断降低存储节省空间。transformers库generate函数已经将KVCache封装。
-
MQA(Multi-Query Attention):所有Attention Head共享同一个K、V,可以讲KV Cache减少到原来的1/h,Attention的参数量减少了将近一半,为了模型总参数量不变,通常相应增加FFN/GLU规模,弥补一部分效果损失,目前PaLM、StarCoder、Gemini等大模型在使用。
-
GQA(Grouped-Query Attention):为MHA与MQA之间的过渡版本,将所有Head分为g个组(g可以整除h),每组共享同一对K、V,当g=h时就是MHA,g=1时就是MQA,当1<g<h时,它只是将KV Cache压缩到g/h,压缩率不如MQA,但效果更有保证。目前LLaMA2-70B以及LLaMA3全系列、DeepSeek-V1、ChatGLM2、ChatGLM3等
-
MLA(Multi-Head Latent Attention):对KV Cache进行低秩分解,KV Cache存储低秩投影之后的K、V,并对KV进行整合变换。
参考:
MHA、MQA、GQA的区别 - 小飞侠 (http://www.kexue.love/index.php/archives/513/)
缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA - 科学空间|Scientific Spaces(https://kexue.fm/archives/10091)
3.5 对比Norm方法:BatchNorm, LayerNorm, RMSNorm
深度学习中,归一化是常用的稳定训练的手段,CV中常用BatchNorm,Transformer常用LayerNorm,RMSNorm是LayerNorm的一个变体。
BatchNorm是对整个batch样本内的每个特征做归一化,消除了不同特征之间的大小关系,同时保留不同样本间的大小关系。CV常用是因为每个通道c可看作一个特征,BN可以把各通道特征图的数量级调整到差不多,同时保持不同图片相同通道特征图间的相对大小关系。
LayerNorm是对每个样本的所有特征做归一化,消除了不同样本间的大小关系,同时保留一个样本内不同特征之间的大小关系。LN更适合NLP领域,保留d维特征(token)在各维度之间的大小关系。
RMSNorm为了节省LayerNorm的计算量而提出,可以节省7%~64%的运算。不需要同时计算均值和方差两个统计量,只需要计算均方根Root Mean Square一个统计量。
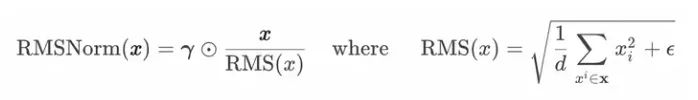
RMSNorm计算公式
## LLaMA源码中实现的RMSNorm
class LlamaRMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
"""
LlamaRMSNorm is equivalent to T5LayerNorm
"""
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states.to(input_dtype)
3.6 Flash Attention
3.7 强化学习PPO、DPO

在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}