







参考:《大模型导论》
1. 模型压缩和加速
为了提升推理速度
- 减少模型尺寸:量化、蒸馏、权重共享
- 减少计算操作:模型剪枝、稀疏激活
1.1 量化
将浮点数 量化成 整型数
Q
=
R
S
+
Z
Q = \frac { R } { S } + Z
Q=SR+Z
R 是真实的浮点数
Q 量化后的定点数
Z 0浮点数对应的量化值
S 收缩因子
S
=
R
max
−
R
min
Q
max
−
Q
min
S = \frac { R _ { \ \ \max } - R _ { \min } } { Q _ { \ \ \max } - Q _ { \min } }
S=Q max−QminR max−Rmin
Z
=
Q
max
−
R
min
S
Z = Q _ { \ \ \max } - \frac { R _ { \min } } { S }
Z=Q max−SRmin
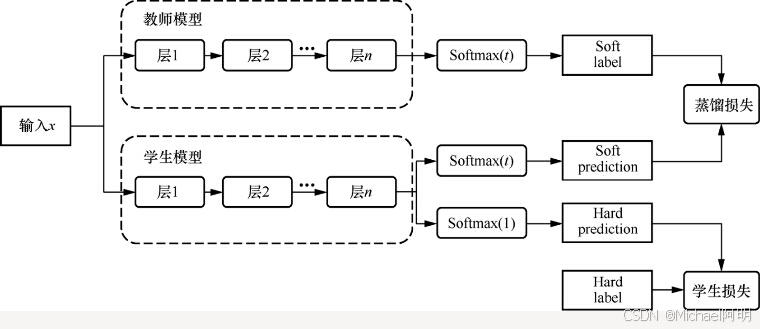
1.2 蒸馏
L
=
α
L
S
o
f
t
+
(
1
−
α
)
L
H
a
r
d
L = \alpha L _ { S o f t } + (1-\alpha) L _ { H a r d }
L=αLSoft+(1−α)LHard
L
S
o
f
t
=
−
∑
i
N
p
i
T
log
(
q
i
T
)
L _ { S oft} = - \sum _ { i } ^ { N } p _ { i } ^ { T } \log ( q _ { i } ^ { T } )
LSoft=−i∑NpiTlog(qiT)
L
H
a
r
d
=
−
∑
i
N
c
j
log
(
q
i
1
)
L _ { H a r d } = - \sum _ { i } ^ { N } c _ { j } \log ( q _ { i } ^ { 1 } )
LHard=−i∑Ncjlog(qi1)
步骤:
- 训练教师模型
- 设计学生模型,可以选择层数减少、宽度缩小、参数共享等方式来降低复杂度
- 教师模型对输入数据进行预测,获取软标签
- 加权两种损失,考虑 跟老师输出的差异 和
真实标签的差异(避免被老师的偶然错误带跑) - 评估调优,学生模型结构调整,蒸馏温度T,超参数 a
还有特征蒸馏:学习教师模型的隐藏层输出
1.3 剪枝
删除不重要的模型参数,但是会引起精度损失
一般流程:
- 训练网络
- 删除权重值低于阈值的神经元
- 对网络重新训练(减少精度损失),后两步可以重复多次
1.4 稀疏激活
- 减少激活数量
某些神经元只在特定条件下被激活(输出非零值),其他神经元的激活值为零或被忽略,减少计算,减少内存占用
MOE 混合专家模型,门控网络负责选择合适的专家
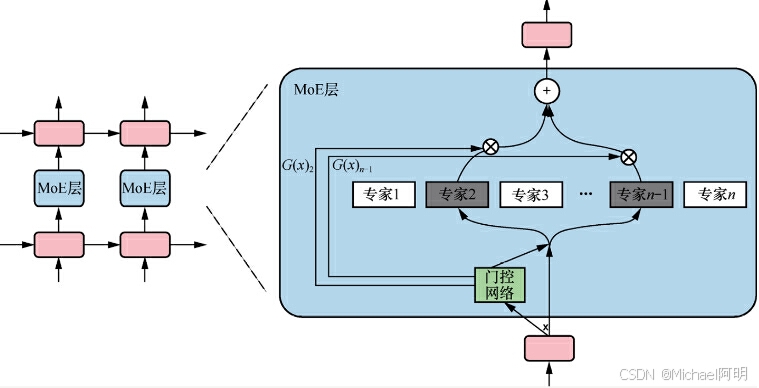
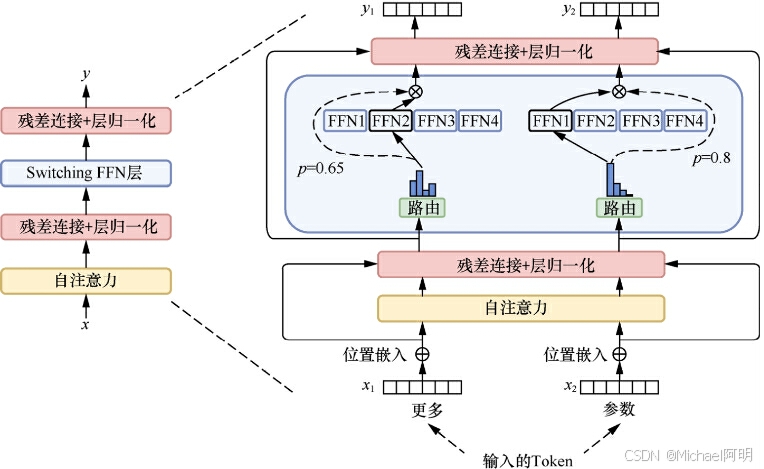
稀疏激活模型有:悟道2.0,GLaM,Mixtral 8x7B 等
2. 推理服务加速
- 减少时间延迟
- 增加单位时间处理的 token 数量
2.1 KV Cache
- 以空间换时间
- 已知前 n 个Token, 预测第 n+1 个 Token的时候,对前n个Token的计算是重复的
- 对 K,V等信息缓存在内存中,后续复用,减少计算,推高推理效率
缺点就是会占用一定的显存资源
transformers 中的 generate() 已经内置该技术了
2.2 PagedAttention
大模型部署框架 VLLM 就使用了这个技术
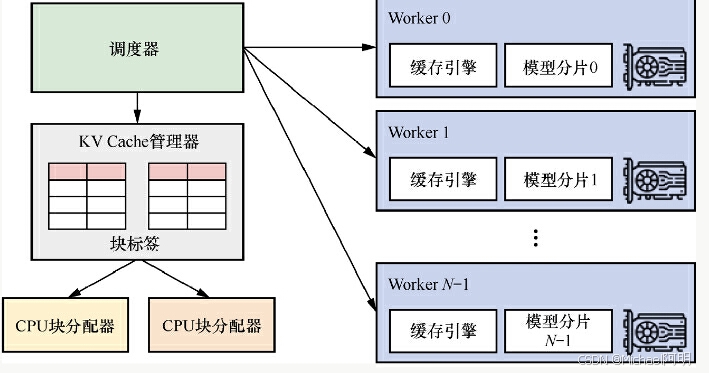
一次处理多个请求,需要有效管理每个推理占用的内存空间
-
将每个序列的KV缓存分成多个块,每个块包含固定数量的标记的键和值。在注意力计算过程中,PagedAttention Kernel 高效地识别和获取这些块,采用并行的方式加速计算
-
允许在非连续的内存空间中存储连续的KV张量
-
在块的粒度上实现了内存共享,不仅在与同一请求相关的不同序列之间,而且在不同请求之间
3. 常见推理框架
-
vLLM
通过PagedAttention技术高效地管理attention中缓存的张量,比HuggingFace Transformers高14-24倍的吞吐量。兼容OpenAI的接口服务,与HuggingFace模型无缝集成 -
Text Generation Inference (TGI)
TGI提供了一系列优化技术,如模型并行、张量并行和流水线并行等,这些技术可以显著提升大模型推理的效率。适合需要在多种硬件环境下进行高效推理的场景。 -
llama.cpp
主要目标是在本地和云端的各种硬件上以最少的设置和最先进的性能实现LLM推理。提供1.5位、2位、3位、4位、5位、6位和8位整数量化,以加快推理速度并减少内存使用。
适合CPU推理,结合模型int4量化,减少内存使用。 -
MLC LLM
适合在手机终端推理,可在客户端(边缘计算)如Android或iPhone平台上本地部署LLM -
TensorRT-LLM
是Nvidia在TensorRT推理引擎基础上,针对Transformer类大模型推理优化的框架。支持多种优化技术,如 kernel 融合、矩阵乘优化、量化感知训练等,可提升推理性能 -
DeepSpeed
微软开源的大模型训练加速库,最新的DeepSpeed-Inference提供了推理加速能力。通过内存优化、计算优化、通信优化,降低推理延迟和提升吞吐。 -
OpenLLM
是一个用于在生产中操作大型语言模型(LLM)的开放平台,良好的社区支持,集成新模型,支持量化,LangChain集成 -
FasterTransformer
由NVIDIA开发,用于加速Transformer模型的推理。
支持多种模型,针对NVIDIA GPU优化,提升性能。低精度推理,分布式推理,减少内存使用和访问延迟


















 811
811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











