






1. SRA数据库简单介绍
序列读取档案(SRA)存储来自“下一代”测序技术的原始序列数据,包括Illumina、454、IonTorrent、Complete Genomics、PacBio和Oxford纳米孔。除了原始序列数据外,SRA现在还以读取位置的形式在参考序列上存储对齐信息。
2. 四种类型的数据
- STUDY with accessions in the form of SRP#, ERP#, or DRP#
- SAMPLE with accessions in the form of SRS#, ERS#, or DRS#
- EXPERIMENT with accessions in the form of SRX#, ERX#, or DRX#
- RUN with accessions in the form of SRR#, ERR#, or DRR#
3. SRA 软件工具包的下载
官网地址 下载系统对应的文件
4. 安装和配置
解压:
tar xzvf sratoolkit.2.11.1-centos_linux64.tar.gz进入bin目录 运行如下命令进行配置
./vdb-config --interactive 5. 下载
下载单一文件到当前目录
vim ~/.bashrc
# 最后一行加入 export PATH=sratoolkit_bin_dir:$PATH
source ~/.bashrc 立即生效
prefetch -p SRR62322-o -O 参数分别指定下载文件名称和目录。
下载多个文件,file.txt 含有多个sra号
prefetch --option-file file.txtprefetch 官方教程
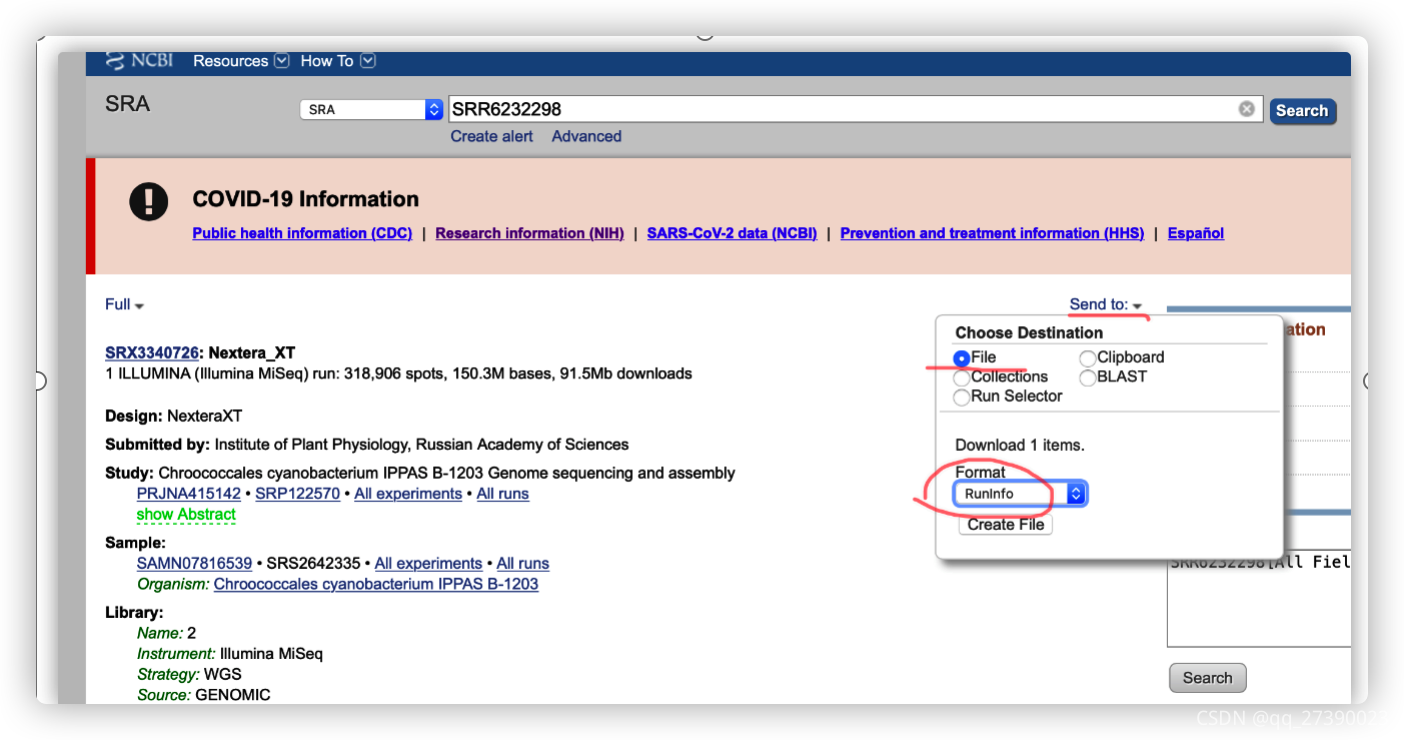
6.表型数据下载
SRA的表型数据可以到NCBI的SRA Entrez搜索查看,也可以下载,如下图。
7. 转化成fastq文件
双端测序,加--split-files参数
fastq-dump --split-files SRR6232298.sra
fastq-dump参考文档: fastq-dump官方教程















 1265
1265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









