






什么是DFT?
DFT是Design For Test的缩写。 指在芯片设计过程中引入测试逻辑,并利用这部分测试逻辑完成测试向量的自动生产,从而达到快速有效的芯片测试的目的。DFT分功能测试和制造测试,功能测试主要寻找设计上可能存在的错误,用来验证电路中的逻辑行为;制造测试用于寻找在制造过程中可能存在的制造缺陷(开路、短路等)。
DFT是为了使制造测试尽可能简单,覆盖率尽可能高,而在电路中加入一些特殊逻辑的设计方法。
DFT的工作包括什么
-
在项目初期规划DFT架构;
-
在RTL级别设计测试电路;
-
在验证阶段验证测试电路;
-
在synthesis阶段实现测试逻辑的插入;
-
在测试阶段提供测试向量。
IC设计流程
数字前端设计(front-end):以生成可以布局布线的网表为终点;
数字后端设计(back-end):以生成可以进行流片的GDSII文件为终点;
芯片架构-RTL设计-功能仿真-综合&扫描链插入-等价性检验-静态时序分析(前端部分结束)-(后端部分开始)布局规划-布局和布线-布线图与原理图的比较-设计规则检查-签名静态时序分析-GDSII
DFT常见技术
(1)Scan Chain(扫描链),针对时序电路,测试寄存器(Flip-Flop)和组合逻辑;
(2)MBIST(Memory Bulit-in Self Test,内建自测试),测试芯片中存储资源, rom 和 ram,在设计中插入内建自测试逻辑;
(3)Boundary Scan(边界扫描),测试封装与 IO、芯片间互联,主要逻辑有 TAP Controller 和 Boundary Scanchain)、JTAG(JTAG 是boundary scan design中用到的一个基本结构)。
ATPG(Automatic Test Pattern Generation,自动测试向量生成,基于扫描链,根据算法推算出应该加载到扫描链上的激励序列和期望序列,这样的序列称为测试向量);
DFT 构建硬件结构,ATPG 生成测试向量。
DFT工程师所需要的能力
-
DFT的基本概念:MBIST/boundary scan/logic bist
-
前端知识:RTL coding
-
脚本语言能力:Perl/Python/TCL/shell
-
EDA工具
-
Timing知识:减少对Timing的影响
-
ATE debug知识:
其他知识
DFT 能够覆盖电路时序问题
DFT 的 Scan Chain 扫描链:针对时序电路,测试寄存器(Flip-Flop)和组合逻辑;
其中,DC Scan是慢速测试;AC Scan是全速测试 at speed test,使用高于芯片工作频率的时钟,测试 setup 和 hold 。
DFT 影响动态功耗
影响器件测试的动态功耗有两种:峰值功率和平均功率。峰值功率,也称为“瞬时功率”,反映了器件中节点开关的活动水平,从一个逻辑状态切换到另一个状态的节点数量越多,峰值功率就越大,DFT 里涉及大量 MUX 选择开关。
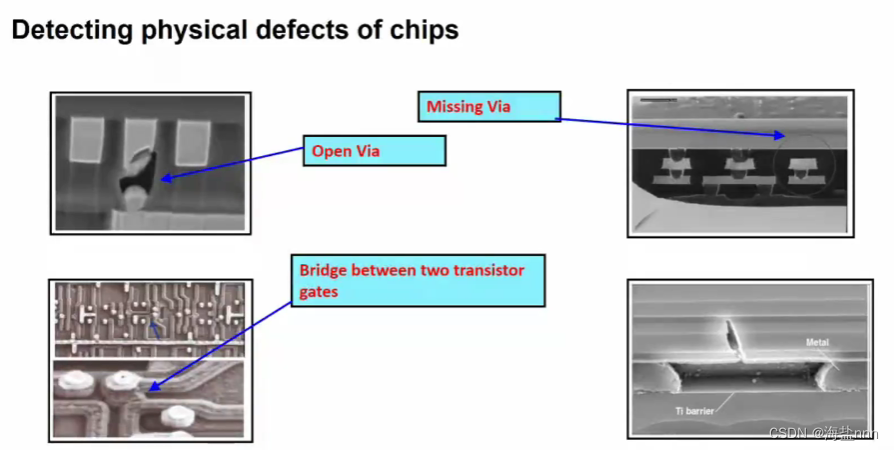
DFT(Design for Test)检测制造缺陷
在芯片设计过程中,加入各种 可测性逻辑,使芯片变得容易测试,找到存在 制造缺陷 的芯片,主要是为了找出在 生产制作 中引入的 制造缺陷(短路、断路等)。
DFT:为了检查 制造缺陷,降低测试成本,提高产品质量。
常见的可测性设计技术(Design for Test)
Scan Chain 扫描链,针对时序电路,测试寄存器(Flip-Flop)和组合逻辑;
MBIST 存储器内建自测试,测试芯片内的 rom 和 ram;
Boundary Scan 边界扫描,测试封装与 IO、芯片间互联。

















 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









