









Abstract
少样本分类具有挑战性,因为训练集的数据分布可能与测试集大不相同,因为它们的类不相交。这种分布变化通常会导致泛化能力差。流形平滑已被证明可以通过扩展决策边界和减少类表示的噪声来解决分布偏移问题。此外,流形平滑度是半监督学习和转导学习算法的关键因素。在这项工作中,我们建议使用嵌入传播作为无监督的非参数正则化器,用于小样本分类中的流形平滑。嵌入传播利用基于相似图的神经网络提取特征之间的插值。我们凭经验表明嵌入传播会产生更平滑的嵌入流形。我们还表明,将嵌入传播应用于转导分类器在 miniImagenet、tieredImagenet、Imagenet-FS 和 CUB 中实现了新的最先进的结果。此外,我们表明嵌入传播在多个半监督学习场景中始终将模型的准确性提高了 16%。所提出的嵌入传播操作可以很容易地作为非参数层集成到神经网络中。
代码:
 https://github.com/ElementAI/embedding-propagation
https://github.com/ElementAI/embedding-propagationContributions
- 以无监督的方式对流形进行正则化。
- 利用嵌入插值来捕获更高阶的特征交互。
- 为直推式和半监督学习设置实现最先进的少样本分类结果。
Method
1、嵌入传播
![]()

接下来我们计算邻接矩阵的拉普拉斯算子,
![]()
最后,使用标签传播公式,我们得到传播矩阵P为,
![]()
其中 α ∈ R 是比例因子,I 是单位矩阵。然后,嵌入可通过如下获得,

2、推理阶段
给定一个情节,我们通过提取输入图像的特征,在这些特征上应用嵌入传播,然后应用标签传播来执行推理。更正式地,这是如下执行的。
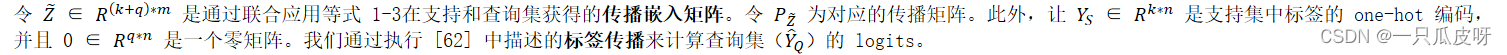
3、训练步骤
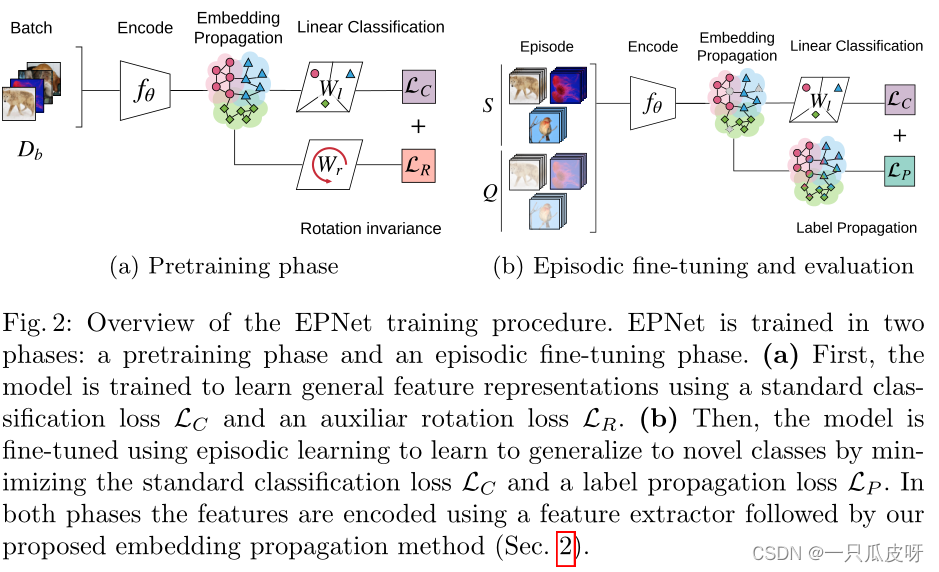
EPNet 分两个阶段进行训练:
- 首先,使用用于小样本分类的通用预训练程序 [41] 在 Db 上对模型进行训练,以学习一般特征表示。
- 其次,使用情节对模型进行微调,以便学习泛化到新类别。eposides来自同一数据集 Db。
在这两个阶段,EPNet 使用相同的特征提取器𝑓𝜃(𝑥)来获得为给定输入图像 x 提取的特征 𝑧。但是,每个阶段都依赖于不同的目标。
3.1 预训练阶段
如图 2a 所示,我们使用两个线性分类器训练𝑓𝜃,它们是由softmax激活且分别被 Wl 和 Wr 参数化的线性层。
第一个分类器被训练来预测 Db 中示例的类标签。它通过最小化交叉熵损失进行优化:
![]()
其中 yi ∈ Yb 和概率是通过将 softmax 应用于神经网络提供的 logits 获得的。
为了与最近的文献进行公平比较,我们还添加了自我监督损失以获得更稳健的特征表示。因此,我们使用第二个分类器来预测图像的旋转度数并使用以下损失:
![]()
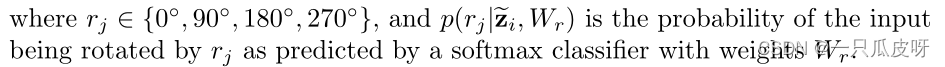
总体而言,我们使用随机梯度下降 (SGD),批量大小为 128,每张图像旋转 4 次,以优化以下损失,
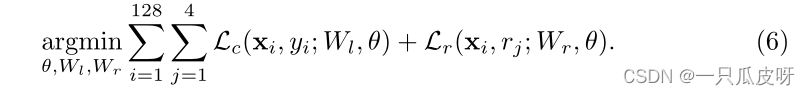
3.2 情景学习
如图 2b 所示,在预训练阶段之后,我们使用情景训练来学习识别新类。在这个阶段,我们还使用两个分类器优化 EPNet。
第一个分类器基于标签传播。它通过对第二节中定义的查询集 logits 𝑌𝑄 应用 softmax 来计算类概率:
![]()
第二个分类器与预训练中使用的基于 Wl 的分类器相同。包含它是为了保留有区别的特征表示。因此,我们最小化以下损失:
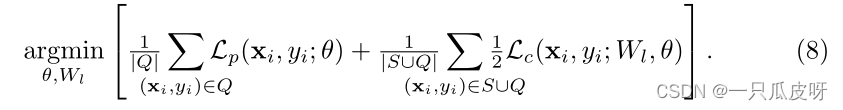
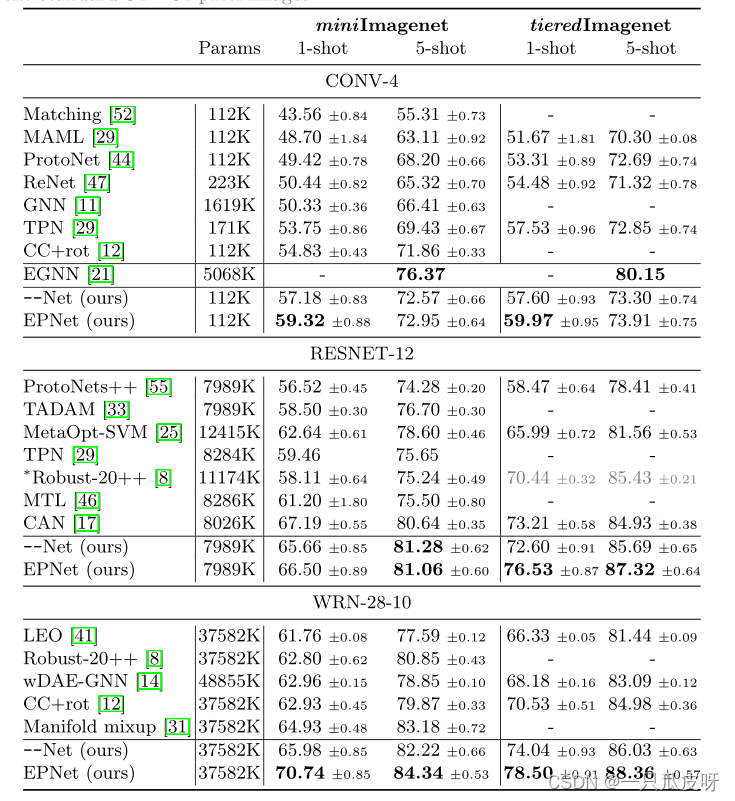
实验


















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









