







R统计-PCA/PCoA/db-RDA/NMDS/CA/CCA/DCA等排序分析教程
一、定义
oridination(gradient analysis):研究群落之间、群落与成员之间、群落与其环境之间的复杂关系。排序的过程是将样方或物种排列在一定的空间,使得排序轴能够反映一定的生态梯度。在一个可视化的低维空间重新排列样方,使得样方之间的距离最大程度地反映出平面散点图内样方之间的关系信息。
二、分类
2.1 根据物种响应环境梯度模型分类
使用线性响应模型的排序方法叫线性排序(linear ordination),包括RDA和PCA等;而基于单峰响应模型的被称为非线性排序(nonlinear ordination),包括CCA、CA、DCA和DCCA等。线性响应模型通常使用最小二乘法进行回归拟合。单峰响应模型则是通过基于所有包含该物种的样方中环境因子的加权平均得到该物种在环境梯度上的最适値。单峰模型能更好的反映种-环境和种-种之间的关系。在具体分析的时候怎样选择模型,参考R绘图-RDA排序分析一文。需要补充的是物种数据的量纲不同时不适合做单峰模型排序;有空样方出现的数据要采用单峰分析,需要把空样方剔除。
2.2 根据是否使用环境因子数据分类
约束排序是在已有环境因子中寻找最相关的解释群落结构变化的变量,所用环境因子数要至少要比样品数少2;而非约束排序是寻找最能展示群落结构变化的潜在的解释变量,以排序轴的形式体现。
2.2.1 unconstrained ordination(非约束排序/间接排序) :只使用物种组成数据的排序
(1)principal components analysis:主成分分析(PCA),基于原始的物种组成矩阵所做的排序分析。
(2)correspondence analysis:对应分析(CA)
(3)Detrended correspondence analysis:去趋势对应分析(DCA)
(4)principal coordinate analysis:主坐标分析(PCoA) ,基于由物种组成计算得到的距离矩阵得出的。
(4)non-metric multi-dimensional scaling:非度量多维尺度分析(NMDS)
2.2.2 constrained ordination(约束排序/直接排序):使用物种和环境因子数据排序
(1)redundancy analysis:冗余分析(RDA)
(2)Canonical correspondence analysis:典范对应分析(CCA)
(3)Detrended canonical correspondence analysis:降趋势典范对应分析(DCCA)
(4)Canonical variate analysis:典型变量分析(CVA)
(5)distance based redundancy analysis (db-RDA):基于距离的冗余分析
2.3 偏分析(partial analysis)
预先移除群落结构变化中由协变量产生的那部分影响,在通过排序展示剩下的变化量的排序方法,约束排序和非约束排序均有相应的偏分析方法。
2.3.1 Partial methods of unconstrained ordination:非约束性偏分析方法
partial PCA;partial CA ;partial DCA
2.3.2 Partial methods of constrained ordination:约束性偏分析方法
partial RDA;partial CCA;partial DCCA;partial CVA
三、R中进行排序分析
Canoco和R中的vegan包都可以实现上述排序分析,但是Canoco是一个收费软件,而且不能像R中ggplot2绘制精美的图,因此下面我使用R来展示排序分析。
3.1 数据准备
所有排序分析都使用的是同一套数据,一个不同放牧处理的土壤微生物物种组成数据,对应样品的土壤理化因子数据以及一个分类因子文件。
 图1|物种组成数据。
图1|物种组成数据。
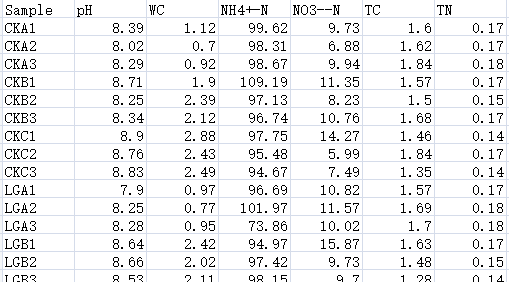 图2|环境因子数据
图2|环境因子数据

图3|分类数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1950
1950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











