






WWW '24 | EarnMore: 如何利用强化学习来处理可定制股票池中的投资组合管理问题
原创 QuantML QuantML 2024-04-16 09:04 上海
Content
本文主要探讨了如何利用强化学习(Reinforcement Learning, RL)来处理可定制股票池(Customizable Stock Pools, CSPs)中的投资组合管理(Portfolio Management, PM)问题。
1. 引言与背景
投资组合管理是金融交易中的基本任务,目的是通过不同股票之间的资本分配来追求长期利润。
现有的RL方法主要关注固定股票池,这与投资者的实际需求不符,因为不同投资者的目标股票池可能因市场状态和个人偏好而显著不同。
为了解决这一问题,论文提出了一个名为EarnMore的RL框架,它通过在全球股票池(Global Stock Pool, GSP)中一次性训练,来处理CSPs中的PM问题。
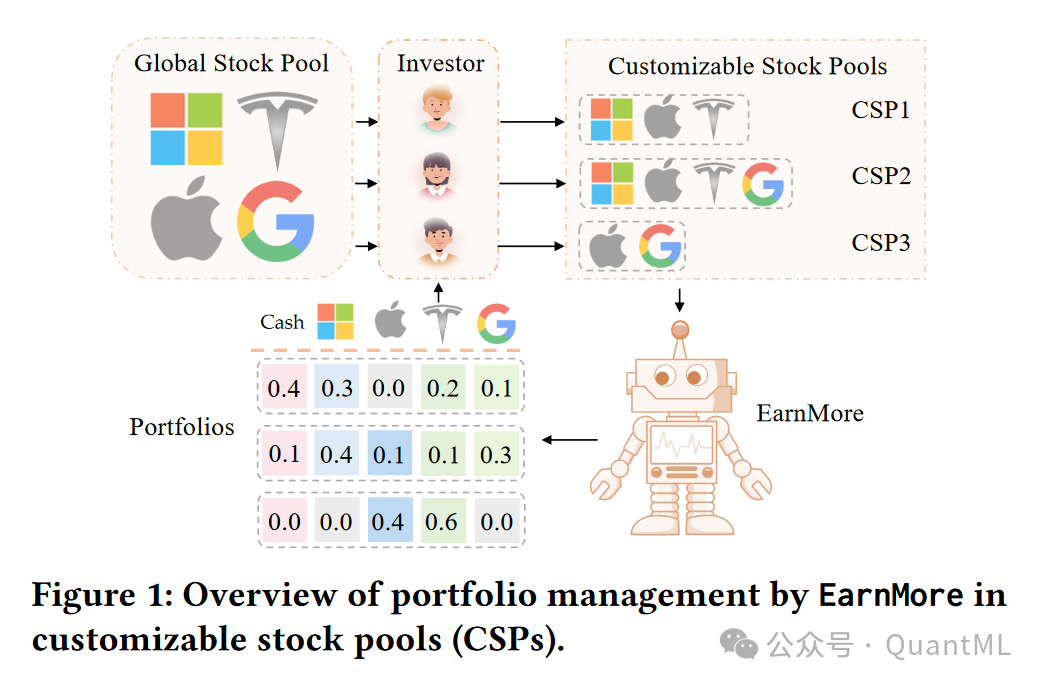
2. 相关工作
论文回顾了传统的投资组合管理方法,如均值回归和动量策略,以及基于预测的方法,如机器学习和深度学习方法。
论文还讨论了Masked Autoencoders(MAEs)在时间序列预测中的应用,特别是在金融市场中的低信噪比数据。
3. 方法论
EarnMore模型结构是为了解决在可定制股票池(CSPs)中进行投资组合管理(PM)的问题。模型结构包含三个主要组成部分:Maskable Stock Representation(MSR),Reinforcement Learning Optimization(RL Optimization),以及Re-weighting Method。
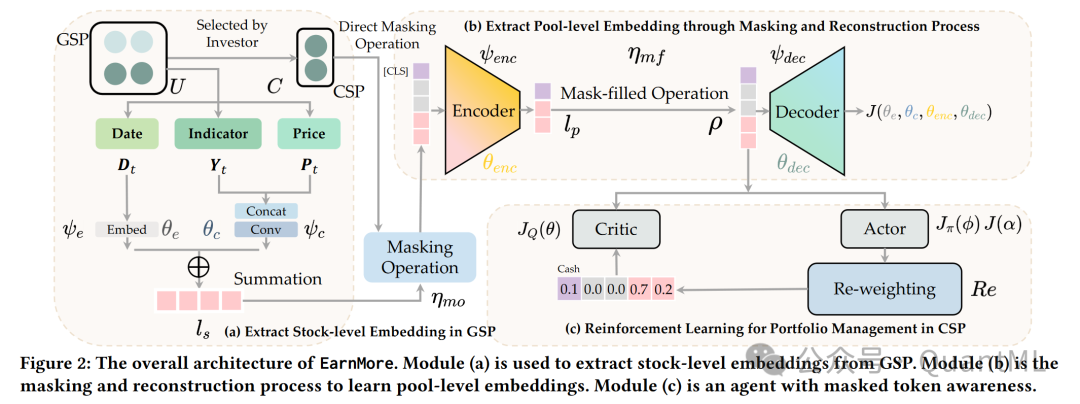
1. Maskable Stock Representation (MSR)
MSR是EarnMore模型的核心,它通过以下步骤来处理和表示股票信息:
Stock-level Representation:该部分利用股票的特征(如价格和技术指标)和时间特征来生成股票级别的表示。使用一维卷积(1D Convolution)来产生密集的嵌入,并使用嵌入层来处理稀疏的时间特征。最终的股票级别表示是通过密集和稀疏嵌入的总和形成的。
Pool-level Representation:股票级别的表示仅描述了每个单独股票内部的垂直时间序列信息,而没有捕捉到股票之间的水平关系。为了解决这个问题,引入了池级别的表示,通过掩码和重建过程来强化GSP中股票之间的联系。这个过程使用股票级别的嵌入作为局部嵌入,替换了MAEs中用于历史数据的补丁嵌入。
Masking and Reconstruction Process:在训练过程中,使用自适应掩码策略来模拟不同股票数量和组成的各种CSPs,提高了池级别嵌入的表示能力,并统一了高掩码和低掩码比例股票池的训练框架。通过编码器和解码器的过程,使用掩码操作来选择性地掩盖一部分股票级别的嵌入,然后使用掩码填充操作来恢复这些嵌入,并使用解码器来重建被掩盖股票的价格。
2. Reinforcement Learning Optimization (RL Optimization)
EarnMore模型的RL优化过程基于Soft Actor-Critic (SAC)算法,包含两个主要组件:Actor和Critic。
Actor:利用由掩码标记填充的潜在嵌入来生成动作,这些动作指示现金和个别股票的分配比例。Actor在决策过程中会避免分配不利股票。
Critic:使用由Actor生成的动作和潜在嵌入来评估投资组合的表现,并提供一个评分机制来指导学习过程并优化投资策略。
Q-Value Network Optimization:使用MSR定义的掩码股票表示作为状态输入,通过最小化灵活的Bellman残差来学习Q值函数。
Policy Network Optimization:使用重参数化技术来优化策略网络,并通过最小化KL散度来实现。
Parameter Alpha Optimization:使用自动熵调整方法来调整熵参数,通过最小化损失函数来实现。
3. Re-weighting Method
在连续的决策空间中,为了解决投资组合管理中的准确决策问题,引入了重新加权方法。该方法通过在softmax函数中引入一个额外的超参数来实现投资组合的稀疏化,从而将微小的投资比例重新加权到零。
Softmax Re-weighting:使用一个温度参数来调整softmax函数,较低的温度值会导致更稀疏的分配。随着温度参数接近零,所有投资都倾向于分配给预期回报最高的资产。
这些组成部分共同工作,使得EarnMore模型能够在全球股票池中一次性训练,并能够适应不同投资者的个性化需求和市场条件的变化。通过这种方式,EarnMore能够在不同的CSPs中实现优化的投资组合管理。
4. 实验
在美国股票市场的8个子集股票池上进行了广泛的实验。
EarnMore在6个流行的财务指标上显著优于14个最先进的基线方法,利润提高了40%以上。
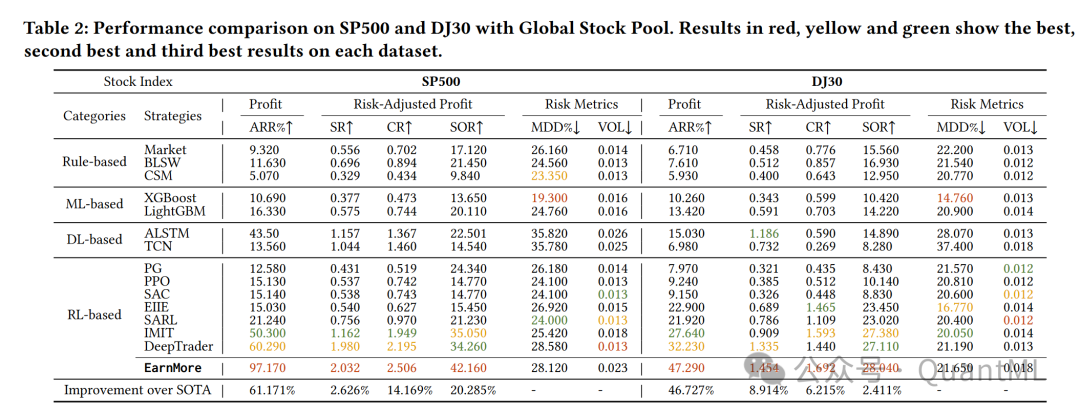
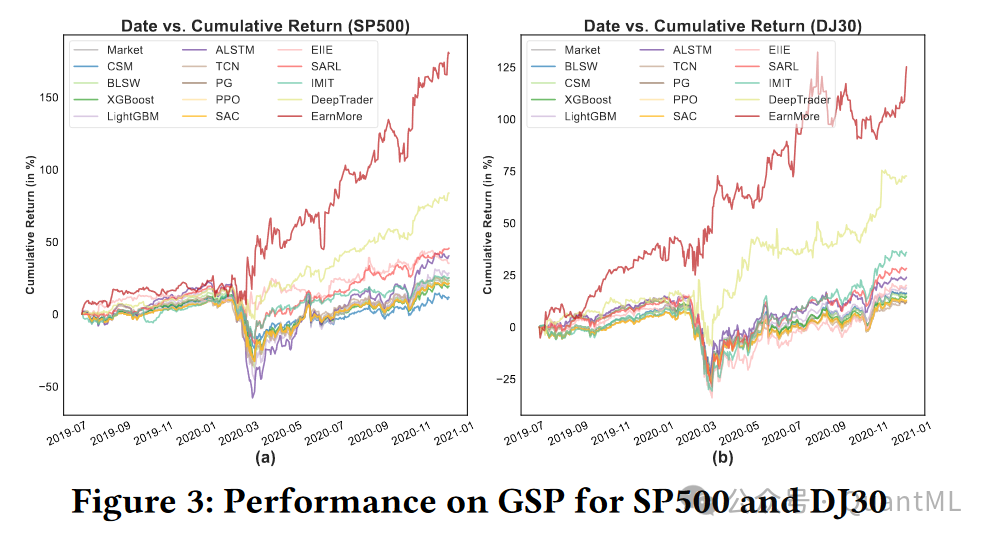
论文还展示了EarnMore在不同市场条件下的表现,以及在投资者个人决策过程中的适应性和鲁棒性。
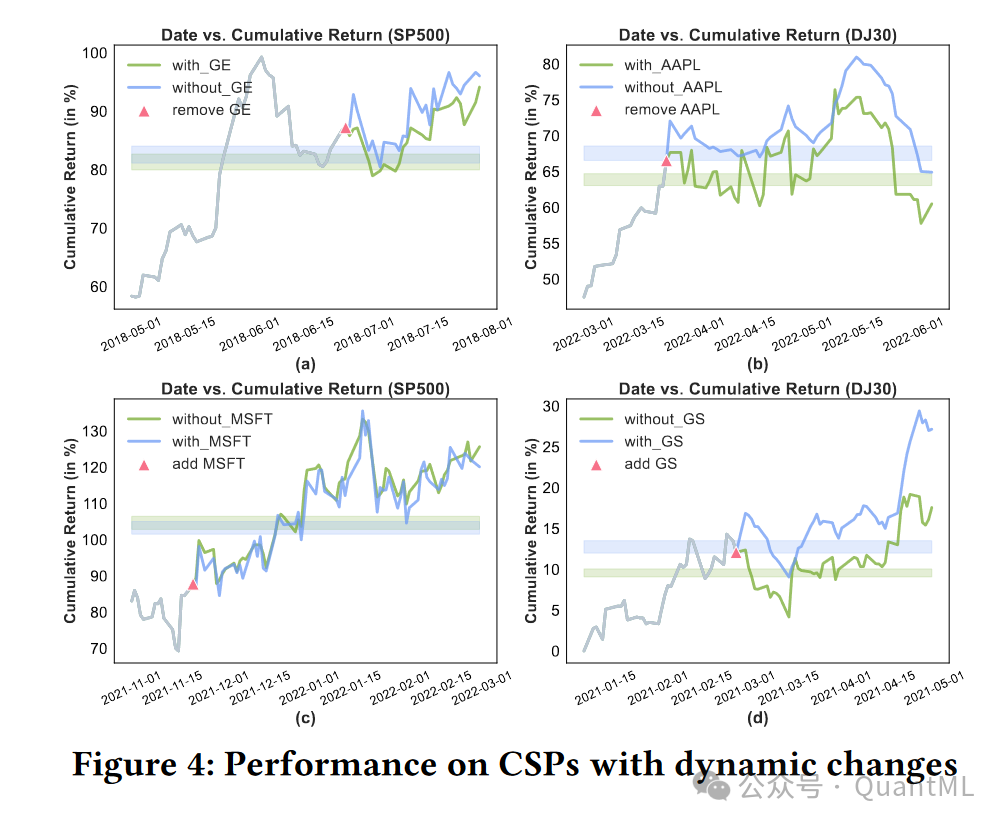
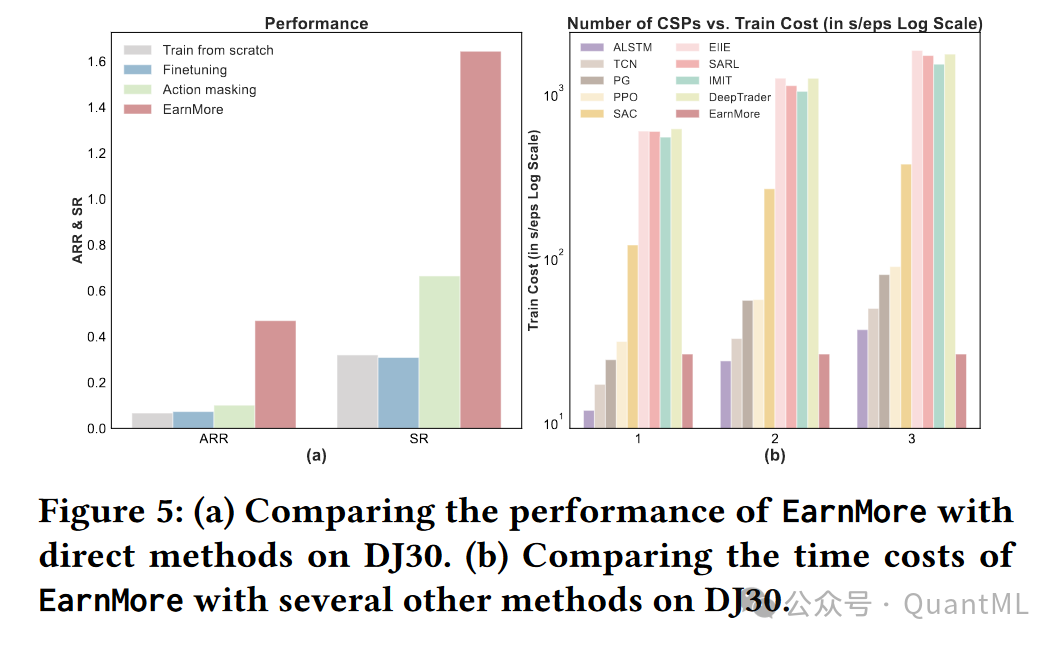
5. 结论与未来方向
EarnMore通过增强的掩码和重建过程提高了股票表示的性能,并引入了重新加权方法来改善投资组合。
未来研究将集中在通过风险惩罚优化来增强风险控制,并创建一个灵活、开放的可定制股票池,允许轻松添加或移除股票。















 8281
8281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









