









赵淼 1 谢良 1 林文静 1 徐海蛟 2
摘 要
近年来,投资组合管理问题在人工智能领域得到了广泛的研究,但现有的基于深度学习的量化交易
方法存在一些可以改进的地方。首先,对股票的预测模式单一,往往一个模型只训练出一个交易专家,交
易的决策也仅根据模型预测结果;其次,模型使用的数据源相对单一,只考虑了股票自身数据,忽略了整
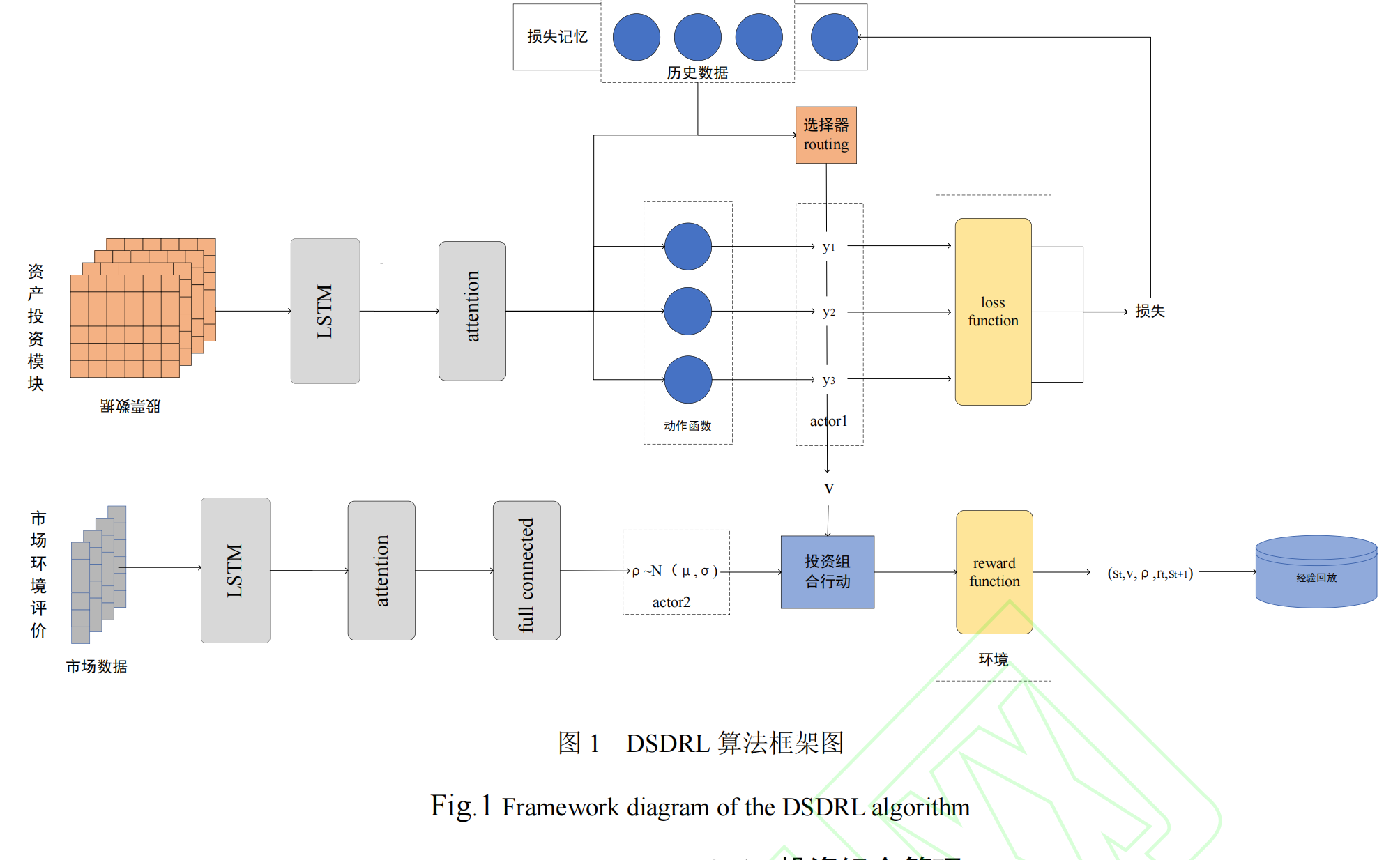
个市场风险对股票的影响。针对上述问题,文中提出了基于动态选择预测器的强化学习模型(DSDRL)。
该模型分为三个部分,首先提取股票数据的特征并传入多个预测器中,针对不同的投资策略训练多个预测
模型,用动态选择器得到当前最优预测结果;其次,利用市场环境评价模块对当前市场风险进行量化,得
到合适的投资金额比例;最后,在前两个模块的基础上建立了一种深度强化学习模型模拟真实的交易环
境,基于预测的结果和投资金额比例得到实际投资组合策略。文中使用中证 500 和标普 500 的日 k 线数据
进行测试验证,结果表明,此模型在夏普率等指标上均优于其它参照模型
1
引言
随着人工智能的发展,投资组合管理问题
的研究取得了很大的进展,投资组合管理旨在使
多重风险资产的预期回报最大化。其中,预测股
票的未来趋势在股票投资中起着关键作用
[1,2]
。
准确的股票预测可以一定程度上提高投资组合收
益,而股票价格受到多种因素的影响,因此要实
现高精度的股票趋势预测是具有挑战性的难题。
近些年来,深度强化学习已逐渐在金融领域
展现出了巨大潜力
[3,4,5]
,这类方法让一个代理与
环境交互来训练模型,节省了获取带标签样本的
时间,并且拥有自学习的能力。但是现有的方法
中仍存在许多亟待解决的问题
[6]
,一方面存在预
测单一问题,大多数方法未考虑股票市场周期特
点,代理往往只学习了一种市场预测方法。在市
场迅速变化的过程中,代理学习到的预测方法很
可能不适合当下,当市场差异过大时,代理往往
以遗忘旧的预测方法为代价来学习新的预测方法。
因此,代理很难在剧烈的波动中学习到合适的策
略;另一方面,部分投资策略没有考虑资金比例
问题,也就是没有考虑投资总金额在不同股票中
的分配比例。这种情况下,深度学习虽然可以相
对有效地预测股票的未来趋势,并且根据市场的
周期性变化进行合理的排名,但是仍然缺乏对资
金投入比例方面的考虑。
考虑到真实世界中投资策略和经济周期的变
化,设计一种能够有效考虑不同交易模式的股票
预测方法,可以有效增强模型对股票的交易决策
能力
[7]
。代理基于不同时期的市场环境学习合适
的股票交易环境,提高对不同资产的预测准确性,
指导后续代理对股票的投资资金占比。一般来说,

大多数方法通过历史数据判断得到股票的未来趋
势。不同的投资专家对市场有不同的见解,因此
对同一只股票的未来趋势的判断也有所不同。基
于这种思想,本文构建资产权重模块,一方面让
代理在市场中通过学习不同的市场解读方法,来
训练得到不同模式下的预测器。另一方面让代理
提取时间序列特征并结合不同预测器在强化学习
环境中的回报,为预测样本在多个模式下的预测
器中挑选最佳的预测结果。同时,部分个股的走
势与市场的走势呈现一定的相关性,本文构建市
场环境评价模块,让代理学习动态的调整做空做
多的资金比例。本文的主要贡献可以总结如下:
1.
本文针对预测单一问题,在强化学习网络
中设计多种交易模式存在下的股票预测方法,代
理将学习到这些交易模式并且选择当下最合适的
交易模式,用来解决预测模式单一导致代理在跨
时段中表现不好的问题。
2.
为了解决资金比例问题,将投资组合问题
分为两个部分,投资权重问题与投资比例问题,
并且设计了两个不同的模块去处理对应的问题,
即资产权重模块和市场环境评价模块。市场环境
评价模块针对市场数据进行分析进行对资金比例
的调控。
3.
通过在真实市场数据上的实验验证该方法,
并且证明基于动态选择器的深度强化学习投资组
合模型在能有效的平衡风险和收益。并且在训练
过程中,该方法在训练集上的回报表现随着迭代
次数增加能稳定上升。
大多数方法通过历史数据判断得到股票的未来趋
势。不同的投资专家对市场有不同的见解,因此
对同一只股票的未来趋势的判断也有所不同。基
于这种思想,本文构建资产权重模块,一方面让
代理在市场中通过学习不同的市场解读方法,来
训练得到不同模式下的预测器。另一方面让代理
提取时间序列特征并结合不同预测器在强化学习
环境中的回报,为预测样本在多个模式下的预测
器中挑选最佳的预测结果。同时,部分个股的走
势与市场的走势呈现一定的相关性,本文构建市
场环境评价模块,让代理学习动态的调整做空做
多的资金比例。本文的主要贡献可以总结如下:
1.
本文针对预测单一问题,在强化学习网络
中设计多种交易模式存在下的股票预测方法,代
理将学习到这些交易模式并且选择当下最合适的
交易模式,用来解决预测模式单一导致代理在跨
时段中表现不好的问题。
2.
为了解决资金比例问题,将投资组合问题
分为两个部分,投资权重问题与投资比例问题,
并且设计了两个不同的模块去处理对应的问题,
即资产权重模块和市场环境评价模块。市场环境
评价模块针对市场数据进行分析进行对资金比例
的调控。
3.
通过在真实市场数据上的实验验证该方法,
并且证明基于动态选择器的深度强化学习投资组
合模型在能有效的平衡风险和收益。并且在训练
过程中,该方法在训练集上的回报表现随着迭代
次数增加能稳定上升。
这些算法在股票预测物体上取得了良好的效
果,但是在投资组合策略方面,往往只是采取简
单的预测排名,并且未将交易费率等交易因素与
网络的更新进行结合,因此在实际的交易中取得
的效果有限。
2.2
强化学习
强化学习通过代理与环境交互不断的找到控
制行动的最优策略的方法。目前,一些研究者将
深度神经网络与强化学习结合学习交易策略
[3,6,21,25]
。这些研究者的工作可以大致分为两种,
(
1
)结合不同的网络以及结合机器学习中的改
进方法,来增强代理在金融问题中的学习效果。
例如,
Neuneier
等人
[26]
首先在外汇中使用
RL
算
法,获得了比以往的监督学习算法的更好的性
能。
Moody
等人
[27]
提出了一种递归强化学习
(RRL)
算法,通过优化目标函数来训练投资组合
的交易系统,其中使用递归神经网络
(RNN)
从交
易环境中编码状态。
Rundo
等人
[4]
通过结合长短
期记忆(
LSTM
)网络在
RL
算法中分层预测外
汇市场的中短期趋势,并最大化高频交易的投资
回报率的最大化算法。
OB Sezer
等人
[5]
将一维
金融时间序列转换成二维图像的数据表示,
以便能够利用深度卷积神经网络的力量来实
现算法交易系统。(
2
)利用不同的强化学习
算法并结合其优势,并根据实际金融问题的特
性,在环境的设计或者代理的设计,并且使用更
丰富的数据,从多维度的方向提取更多的特征来
优化投资策略。例如,
Deng
等人
[28]
提出了一种
任务感知的时间反向传播方法,通过
RNN
有效
地训练代理,用
RNN
表示实时金融信号,可以
从状态中提取更高层次的特征,在中国未来市场
获得可靠的利润。
3.1
投资组合管理
3.1.1
马尔科夫过程
投资组合管理是根据当前市场状况将资源配
置为一组金融资产的一个顺序决策过程,目的是在
限制风险的同时实现回报最大化。这种过程符合马
尔科夫过程
(
1)
为状态空间,描
述股票当前状态的一组特性。一般来说,不同类型
的信息,如历史价格变动、交易量、财务报表和情
绪得分,可以作为当前状态。使用某一特定公司过
去 T 天的收盘价序列和特征因子
与市
场数据
,即
。其中
为股
票数量, 为特征因子数量。
(
2)
为动作空间,
t
时
刻执行动作
, 表示代理对不同股票的
评分,并且根据评分选取适合做多的股票进行投资,
计算出投资比例
t
R
n
T
。其中 为选出的股票。
为做多资金比例。
(
3)状 态
s
t
根 据 过 渡 分 布 转 化 为
s
t
1
~
P
(
s
t
1
|
s
t
,
a
t
)
P
(
s
t
1
|
s
t
)
,在投资组合问题
中,代理对下一个状态的影响可以忽略不计。因此,
状态
s
t
1
只受到
s
t
上一个状态的影响,这意味着,

















 8626
8626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









