









Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks 2013
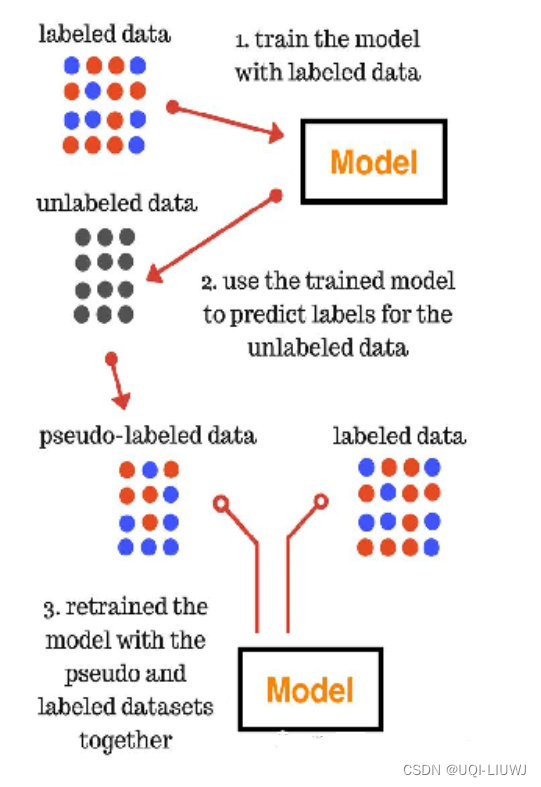
1 伪标签
- 未标记的数据由监督学习网络标记。(将具有最大预测概率的类作为伪标签)
- 然后使用标记数据和伪标记数据训练网络。
2 伪标签的损失函数
- 损失函数分为真实标签部分和伪标签部分
- 伪标签部分的权重使用a(t)来进行调节,如果a(t)特别小,那么伪标签将不会起到作用
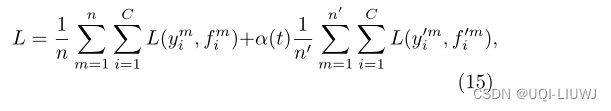
- 上标不带‘的是标注数据和对应的标签
- 上标带’的是未标注数据和对应的伪标签
- a(t)是一个确定性模拟退火过程,有助于在优化过程中避免较差的局部极小值,使未标记数据的伪标签尽可能地与真实标签相似
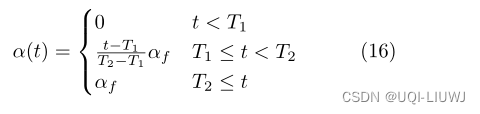
3 为什么伪标签有效果
论文中从分类边界应位于低密度区域、熵最小化两个角度说明了原因
4 伪标签效果
- 伪标签可以减少类重叠
- 直观来说,加入伪标签后,类边界会更清晰,学习到的类应该更紧凑
- 论文用在MNIST上的embedding的t-sne可视化清晰的展示了伪标签的效果
- b)图中的类边界明显要更清晰一些,重叠更少
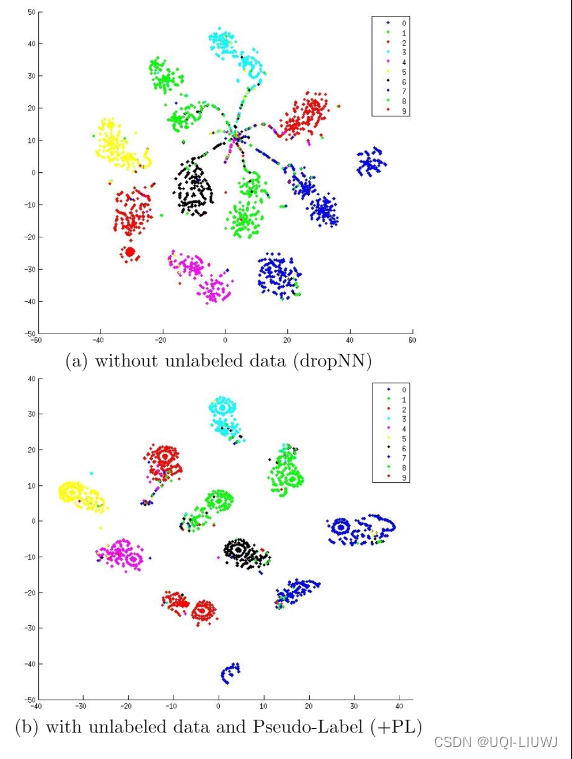
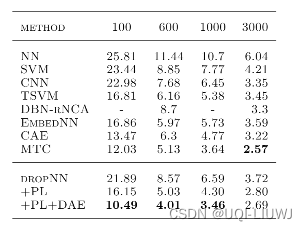
(DAE应该是去噪自编码器?)


















 1998
1998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











