







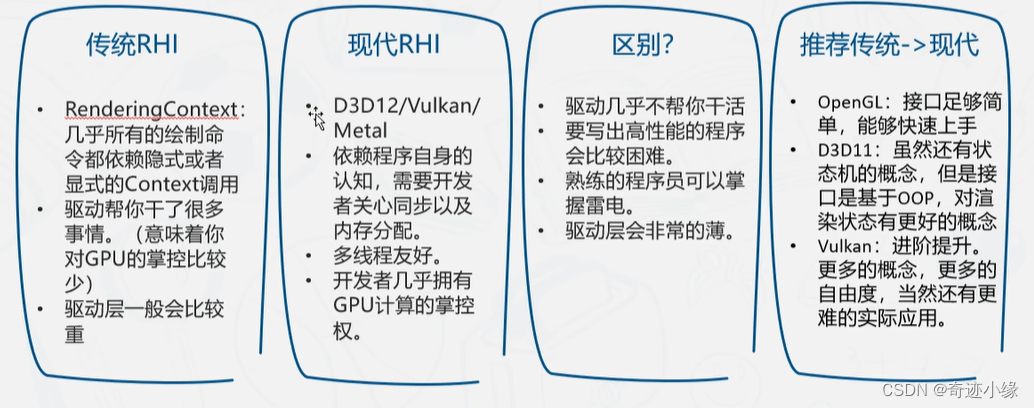
一、RHI - Render Hardware Interface
二、Vulkan简介
- 真正的实现依赖于厂家的驱动实现
- 与传统API相比可以更大程度上直接操作GPU,在难度更大的同时,可以更加自由的编写高性能程序。
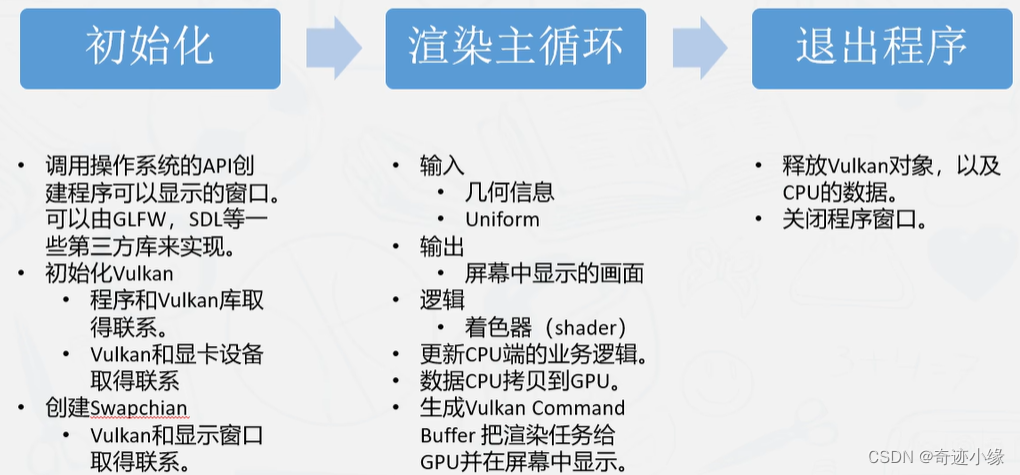
 初始化
初始化
- 创建窗口(操作系统API或者glfw或SDL库)
- 初始化Vulkan
- 创建Swapchain,联系Vulkan与显示窗口。
关心的问题:窗口类型win32、XCB等。
vulkan层次
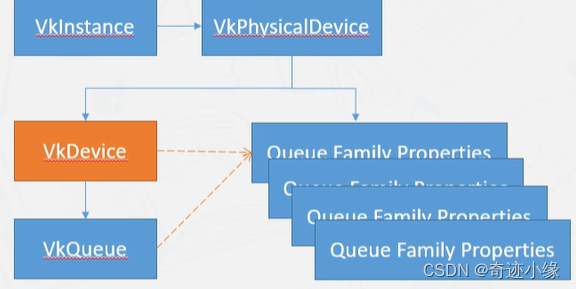
通常情况:一个实例,一个物理设备,一个逻辑设备,一个或多个队列。
但Vulkan创建多个实例,来分配不同的的物理设备,实现不同逻辑设备的与命令队列组合来更好利用GPU资源的能力。

VKInstance
Instance是程序与Vulkan库之间的桥梁
- 需要指定开启的扩展
- 创建swapchain的类型
- 给vulkan对象设置名字的调试功能
- 检查vulkan的错误调用的回调
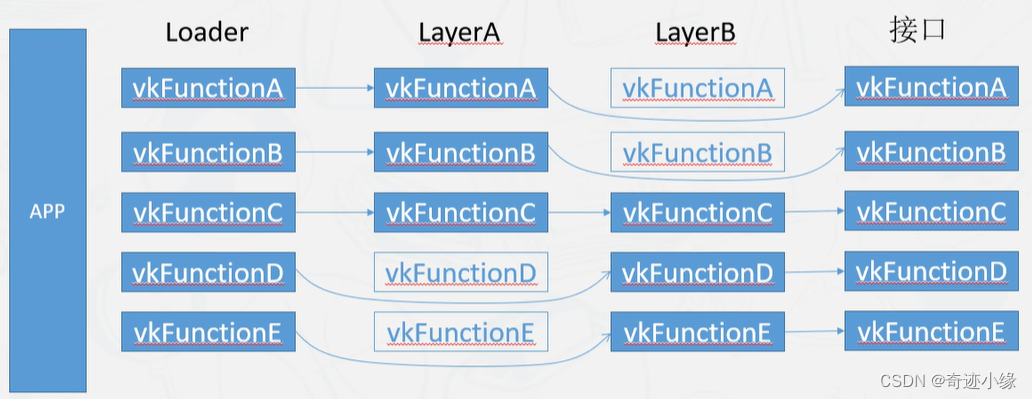
- Vulkan Layer可以实现不同的功能,可以开一个layer去实现扩展功能,例如调试,验证等。
- layer给vulkan提供重写函数的方式,可以重载对应的vulkan函数,传递给下一层layer。
VkPysicalDevice
获取与vulkan instance 和显卡的联系
- Vulkan可以检索当前计算机的显卡设备,以及他们的能力(对功能的支持)
- 根据程序的需要,需要判断显卡是否支持
- 如果程序需要一个扩展,显卡无法提供支持时,可以初始化失败
- 双显卡笔记本可以指定选择独显或核显
VkQueue
Vulkan的Command都需要上传到命令队列VkQueue(绘制,数据上传等)
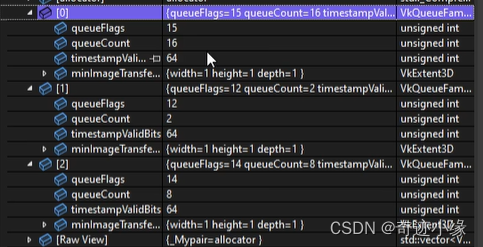
不同类型的队列来源不同的队列簇(Queue Family Properties),不同队列簇只允许部分类型的Command
- VK_QUEUE_GRAPHICS_BIT 图形操作
- VK_QUEUE_COMPUTE_BIT 着色器计算
- VK_QUEUE_TRANSFER_BIT 支持复制Buffer和Image操作
根据程序选择队列簇,使用队列簇需要检查显卡是否支持,例如对物理设备调用
findQueueFamilies来检查物理设备对于队列簇种类的支持。
VkDevice
- 逻辑设备和Vulkan做交互
- 通过逻辑设备可以获取VkQueue(物理设备中的队列簇的一条队列)中的Command。
- 可以选择开启可选的特性,可选特性可以通过
VkPhysicalDeviceFeatures来查询几何着色器,细分着色器,压缩纹理等功能。
移动端设备支持的特性会少。
SwapChain
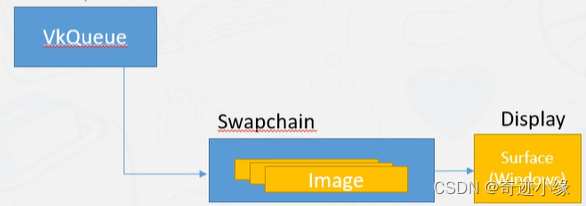
- 通过VkInstance创建Surface,然后vulkan与窗口取得联系。
- 需要检查使用的队列簇是否同时支持surface与graphic
- 创建swapchain和surface获取联系
- 创建swapchai的时候选择属性,颜色空间(SRGB/HDR),刷新模式(Vsync),缓冲数量(双缓冲三缓冲)
- 从Swapchain获取缓冲的Image,用于后面创建FrameBuffer用于渲染。
渲染主循环

- 输入几何信息
- 输出屏幕画面
- 处理着色器
- 更新CPU端逻辑
- CPU到GPU的数据拷贝
- 生成Vulkan Command Buffer,提交渲染任务到GPU
与opengl不一样,一般没有默认值,我们需要手动设置,例如深度检测等。
顶点输入
顶点数据缓存(vertex buffer),索引缓存(inedx buffer),图元拓扑类型(Primitive Topology),Draw
vertex buffer包括
- 顶点三维坐标
- 法线
- 纹理
- 其他顶点属性

一种可能的数据排布,P和N可能会在程序运行之中随时变化,而属性和纹理往往保持不变。
索引的意义在于顶点复用,拓扑结构中相同顶点属性可以复用以节省内存。
不建议跳转区域过大的vertex共用缓存,容易产生cache miss降低程序性能。
拓扑结构决定顶点如果组成几何,三角形,线。
Draw
VkCmdDraw:对vertex buffer调用drawcall,需要指定顶点数量VkCmdDrawIndexed:有索引的直接绘制VkCmdDrawIndirect: 可以将vertex buffer中传入GPU,可以在GPU端对buffer进行我们想要的处理,例如procedural生成或删除一些顶点,或者对顶点进行剔除后绘制,VkCmdDrawIndexedIndirect:有索引的间接绘制。
Vertex Shader
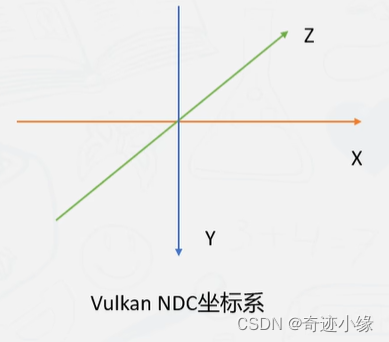
顶点shader经过编译器生成SPIR-V,主要用于计算顶点位置变换到NDC,顶点其他属性的计算。
光栅化Rasterization
- 填充方式
- 剔除方式
- 正方向
- 线宽度
- depth bias解决 z fighting(两个z一致的平面会随机部分相互出现)
ViewPort
设置窗口真正绘制的区域,描述framebuffer作为渲染输出结果目标区域;
一般与窗口一致,也可以设置一个非常大的View Port,增加局部分辨率(例如在做CSM时)。

Fragment Shader
通过插值后的顶点属性与纹理进行fragment上的进行渲染计算。
缓冲区有
- uniform buffer (std 140) (数字为OpenGL的版本)
- storage buffer (std 430)
- push constant (Vulkan特有,频繁更新的数据)
移动端数据要注意精度,顶点位置需要32位浮点数,颜色8位,以减少带宽需求,可以全部先改为半精度,根据实际情况进行进一步修改。
Fragment Buffer
- 混合(alpha混合等)
- 检测(模板/深度检测)
- 深度检测(画家算法,前面的挡住后面的)目前往往会early z,在vertex shader之后就知道了
- early z的一种实现方法,pre depth pass,先进行一个pass,fragment shader部分什么都不干,通过vertex shader给buffer写入深度,但其实有缺点,多进行一次pass,性能损耗较严重。
- 移动端往往采用tile based rendering,TBR由于其需要划分tile,在vertex shader之后,确定tile与图元的对应时可以完成pre depth。
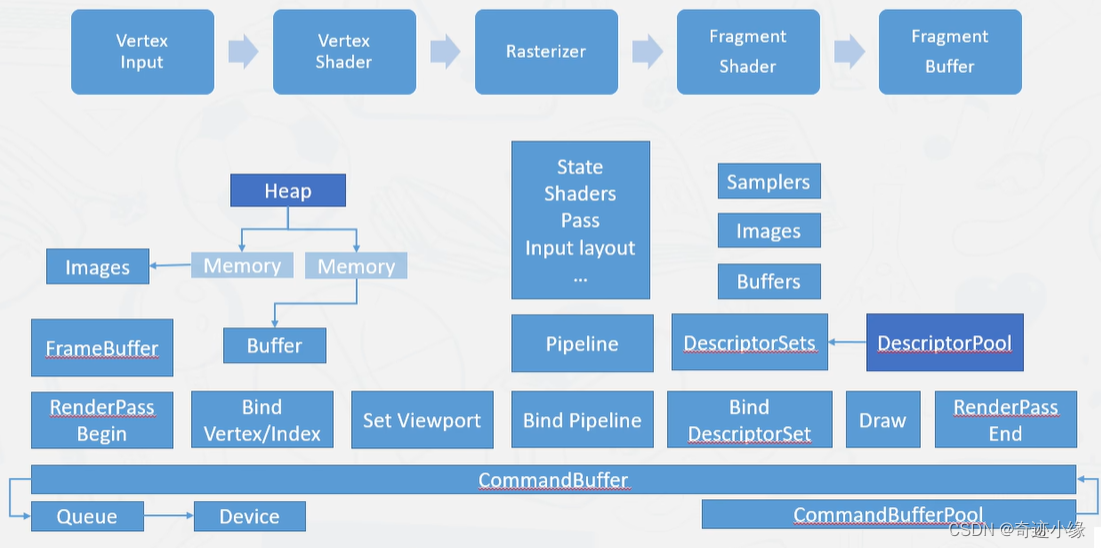
renderpass定义了图形绘制最小单元
定义绘制管线的输出 - framebuffer RT
vulkan定义了
- 1.framebuffer的IO
- 在开始时是否需要保持原有数据
- 结束后是否写回数据
- 在移动端显卡带宽小众需要特别关注
















 98
98











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









