






Paper之AGI:《Levels of AGI Operationalizing Progress on the Path to AGI实现通用人工智能路径上的进展水平》翻译与解读
导读:通用人工智能(AGI)是一个重要但具有争议性的概念。现有的AGI定义各不相同,很难明确地描述和衡量AI系统的能力。这篇文章提出了一套描述人工通用智能能力和行为水平的框架,用于分类AGI模型及其前体的能力和行为。该文件分析了九个著名的AGI定义,并提炼出了有关AGI有用本体论的六个原则。基于这些原则,提出了基于能力深度和广度的“AGI水平”分类法,并讨论了当前系统如何符合这一本体论。它还讨论了未来基准的要求,以量化AGI模型相对于这些水平的行为和能力。提出与AGI水平对应的人机交互自主水平概念。说明综合考虑AGI水平和自主水平可以对风险进行细致分析。强调人机交互研发与模型研发同步进行的重要性。最后强调了选择人机交互范式的重要性,以负责任和安全地部署高度能力的AI系统。
重点内容如下所示:
>> 该框架引入了AGI性能、一般性和自治的水平,类似于自动驾驶的水平,以比较模型、评估风险并衡量通往AGI的进展。
>> 提出了描述AGI能力和行为的"水平制度"框架。该框架从能力深度(表现能力)和广度(通用能力)两个维度来分类AGI的能力等级。
>> AGI的级别六个等级(0~5):初级、熟练、专家、乐师和超人。将通用能力分为狭隘能力和通用能力两类。AGI的级别六个等级(0~5):No AI(无人工智能)→Emerging(等于或略优于不熟练的人类,如符号化的智能)→Competent(至少达到成年人的50%,如智能音箱Siri)→Expert(至少达到成年人的90%,如生成图像模型Dall-E)→Virtuoso(至少达到成年人的99%,如AlphaGo )→SuperHuman(超过100%的人类表现,如AlphaFold/AlphaZero等)
>> 论文阐述了该框架的六大原则:能力而非过程、广泛性和性能、认知和元认知任务、潜力而非部署、生态效度、关注通往通用人工智能的路径等。
>> 论文对当前主流AI系统如ChatGPT等进行分析,归类到该框架中的相应等级。
>> 人机交互中的自主级别—人机交互决策设计的重要性:No AI→作为工具(搜索信息/机器翻译)→作为顾问(文本摘要/代码生成/复杂推荐)→作为合作者(象棋博弈/与AI生成互动)→作为专家(科学发现-蛋白质折叠)→作为代理(AI驱动的个人助手)>> 论文着重讨论了如何通过指标体系来衡量不同水平AGI系统的能力,以及水平等级与部署风险之间的关系。
总之,该论文系统地总结了AGI的定义缺陷问题,提出了一套“水平制度”框架来明确描述和衡量AGI系统的能力水平进展情况。该框架有助于推动AGI相关研究与应用的发展。
目录
《Levels of AGI Operationalizing Progress on the Path to AGI》翻译与解读
Defining AGI: Case Studies—九个著名的AGI定义
案例研究1:图灵测试图灵测试——应该根据能力而不是过程来定义
案例研究2:强人工智能-拥有意识的系统——过于关注过程的框架变得不切实际
案例研究3:类比人类大脑——同时强调能力和过程+transformer架构的成功
案例研究 4:在认知任务上达到人类水平的表现——引入计算机领域+尤其关注非物理任务
案例研究 7:灵活且通用 - “咖啡测试”及相关挑战——需要机器人的化身
案例研究 8:人工有能力智能——现代的图灵测试+有足够性能和通用性的AI系统可完成复杂的多步骤任务
案例研究 9:最新大型语言模型作为通才——已经实现了足够的普遍性
Defining AGI: Six Principles框架的六大原则
原则1、关注能力,而不是过程——不一定要以人类的方式思考+不一定要具有自主意识
原则3、关注认知和元认知任务——执行物理任务可提高通用性,但不应被视为AGI必备条件+元认知能力对系统获得通用性来说很重要
原则4、关注潜力,而不是部署——判断一个系统是否为AGI应基于它能够展示达到一定水平完成必需任务集合的潜在能力,而不应考虑其是否实际部署(会带来法律和伦理问题)
原则5、关注生态有效性(即与人类社会中各种形式价值的实际任务相一致,)
原则6、关注通往AGI的路径,而非单一终点——提出一套类似同级驾驶水平的“AGI水平分类”也有利于明确AGI政策进度和不同定义的整合
表1 | 根据深度(性能)和广度(通用性)对通往AGI的道路上的系统进行分类的层级矩阵方法
AI系统能力的深度和广度:引入了一个关注“性能”和“通用性”的矩阵层级系统
Emerging AGI→Competent AGI:目前的ChatGPT处于一级通用人工智能
Expert:强调设计考虑实际性能的评估标准,以及人机交互方式如何影响判断AGI水平——比如DALL-E2在理论上达“Expert专家”水平,但界面限制可能只达“Competent熟练”水平
SuperHuman/ASI:超越人类水平100%的表现+拥有非人类技能(神经接口/神谕能力/与动物交流等),比如AlphaFold在单项任务上超越顶级科学家
运用"水平制度"框架衡量AGI的两个核心指标是能力广度和深度
实现AGI定义的挑战:回答广泛性维度的问题,以及开发具体多样且具有挑战性的任务+复杂性巨大,需要涵盖广泛的观点
AGI基准的特性:未提出具体基准,而是明确基准应该测量的本体+强调基准应包括广泛的认知和元认知任务
AGI基准的性质:AGI标准应参考现有标准并包括开放式任务,后者可能更贴近真实场景但难定量+AGI标准应持续更新(基准是动态)
确定非AGI的任务:无法详尽列出所有任务但可通过新任务确定系统不是某水平AGI
Risk in Context: Autonomy and Human-AI Interaction情境中的风险:自主性与人工智能交互
Levels of AGI as a Framework for Risk Assessment—AGI级别作为风险评估框架
随着水平向ASI提升,会引入利用风险、对齐风险与结构风险,Expert AGI水平可能面临经济影响与就业替代风险+Virtuoso AGI与ASI水平易产生超级风险(如模型误导人类实现误指定目标)
若进度超过监管,不同国家获得ASI可能带来地缘政治风险+标准测试是否包含危险能力存在争议
Capabilities vs. Autonomy——能力vs.自主性:从系统运行背景出发,阐述AGI水平与人机交互水平如何相互匹配,并强调环境因素在交互设计中的重要性
Table 2 | More capable AI systems unlock new human-AI interaction paradigms 表2 | 更强大的AI系统解锁新的人机交互范式
AGI水平和人机交互水平共同决定不同交互模式解锁,从而影响风险评估。
一般AI系统能力发展不均衡,可能提前解锁某任务范围更高交互水平
综合考虑模型能力和交互设计,可以进行更细致的风险评估和负责任部署决策
Conclusion结论:阐述了对AGI概念和进度判断的原则式思考,以及其在安全研究中的应用价值。
《Levels of AGI Operationalizing Progress on the Path to AGI》翻译与解读
| 地址 | |
| 时间 | 2023年11月4日 |
| 作者 | Meredith Ringel Morris 1 , Jascha Sohl-dickstein 1 , Noah Fiedel 1 , Tris Warkentin 1 , Allan Dafoe 1 , Aleksandra Faust 1 , Clement Farabet 1 and Shane Legg 1 1Google DeepMind |
摘要
| We propose a framework for classifying the capabilities and behavior of Artificial General Intelligence (AGI) models and their precursors. This framework introduces levels of AGI performance, generality, and autonomy. It is our hope that this framework will be useful in an analogous way to the levels of autonomous driving, by providing a common language to compare models, assess risks, and measure progress along the path to AGI. To develop our framework, we analyze existing definitions of AGI, and distill six principles that a useful ontology for AGI should satisfy. These principles include focusing on capabilities rather than mechanisms; separately evaluating generality and performance; and defining stages along the path toward AGI, rather than focusing on the endpoint. With these principles in mind, we propose “Levels of AGI” based on depth (performance) and breadth (generality) of capabilities, and reflect on how current systems fit into this ontology. We discuss the challenging requirements for future benchmarks that quantify the behavior and capabilities of AGI models against these levels. Finally, we discuss how these levels of AGI interact with deployment considerations such as autonomy and risk, and emphasize the importance of carefully selecting Human-AI Interaction paradigms for responsible and safe deployment of highly capable AI systems. | 我们提出了一个分类人工智能(AGI)模型及其前身的能力和行为的框架。这个框架引入了AGI性能、通用性和自主性的层次。我们希望这个框架能以类似于自动驾驶等级的方式提供帮助,通过提供一种比较模型、评估风险和衡量迈向AGI过程中进步的共同语言。为了开发我们的框架,我们分析了现有关于AGI的定义,并提炼出六个有用的AGI本体应满足的原则。这些原则包括注重能力而非机制;独立评估通用性和性能;以及定义AGI道路上的阶段,而不是关注终点。在此基础上,我们提出了基于能力深度(性能)和广度(通用性)的“AGI级别”,并反思了现有系统如何融入这一本体。我们讨论了针对这些级别量化AGI模型的行为和能力的未来基准的挑战性需求。最后,我们探讨了这些AGI级别如何与部署考虑因素(如自主性和风险)相互作用,并强调了谨慎选择人机交互范式的重要性,以负责任和安全部署高性能AI系统。 |
| Keywords: AI, AGI, Artificial General Intelligence, General AI, Human-Level AI, HLAI, ASI, frontier models, benchmarking, metrics, AI safety, AI risk, autonomous systems, Human-AI Interaction | 关键词:AI、AGI、通用人工智能、通用人工智能、人级人工智能、HLAI、ASI、前沿模型、标杆、指标、AI安全、AI风险、自主系统、人机交互 |
Introduction
| Artificial General Intelligence (AGI)1 is an important and sometimes controversial concept in computing research, used to describe an AI system that is at least as capable as a human at most tasks. Given the rapid advancement of Machine Learning (ML) models, the concept of AGI has passed from being the subject of philosophical debate to one with near-term practical relevance. Some experts believe that “sparks” of AGI (Bubeck et al., 2023) are already present in the latest generation of large language models (LLMs); some predict AI will broadly outperform humans within about a decade (Bengio et al., 2023); some even assert that current LLMs are AGIs (Agüera y Arcas and Norvig, 2023). However, if you were to ask 100 AI experts to define what they mean by “AGI,” you would likely get 100 related but different definitions. | 人工通用智能(AGI)是计算研究中一个重要但有时颇具争议的概念,用于描述在大多数任务中至少与人类一样有能力的人工智能系统。鉴于机器学习(ML)模型的快速发展,AGI的概念已经从哲学辩论的主题转变为具有近期实际意义的主题。一些专家认为,AGI的“火花”(Bubeck et al., 2023)已经存在于最新一代的大型语言模型(llm)中;一些人预测,人工智能将在大约十年内广泛超越人类(Bengio et al., 2023);一些人甚至断言,当前的LLMs是AGI (ag<s:1> y Arcas和Norvig, 2023)。然而,如果你问100位AI专家他们对“AGI”的定义,你可能会得到100个相关但不同的定义。 |
AGI的概念很重要:它映射了AI的目标、预测和风险
| The concept of AGI is important as it maps onto goals for, predictions about, and risks of AI: >> Goals: Achieving human-level “intelligence” is an implicit or explicit north-star goal for many in our field, from the 1955 Dartmouth AI Conference (McCarthy et al., 1955) that kick-started the modern field of AI to some of today’s leading AI research firms whose mission statements allude to concepts such as “ensure transformative AI helps people and society” (Anthropic, 2023a) or “ensure that artificial general intelligence benefits all of humanity” (OpenAI, 2023). >> Predictions: The concept of AGI is related to a prediction about progress in AI, namely that it is toward greater generality, approaching and exceeding human generality. Additionally, AGI is typically intertwined with a notion of “emergent” properties (Wei et al., 2022), i.e. capabilities not explicitly anticipated by the developer. Such capabilities offer promise, perhaps including abilities that are complementary to typical human skills, enabling new types of interaction or novel industries. Such predictions about AGI’s capabilities in turn predict likely societal impacts; AGI may have significant economic implications, i.e., reaching the necessary criteria for widespread labor substitution (Dell’Acqua et al., 2023; Ellingrud et al., 2023), as well as geo-political implications relating not only to the economic advantages AGI may confer, but also to military considerations (Kissinger et al., 2022). >> Risks: Lastly, AGI is viewed by some as a concept for identifying the point when there are extreme risks (Bengio et al., 2023; Shevlane et al., 2023), as some speculate that AGI systems might be able to deceive and manipulate, accumulate resources, advance goals, behave agentically, outwit humans in broad domains, displace humans from key roles, and/or recursively self-improve. | AGI的概念很重要,因为它映射了人工智能的目标、预测和风险: >>目标:许多人将实现人类水平的“智能”视为现代 AI 领域的隐含或明确目标,从1955年达特茅斯人工智能会议(McCarthy et al., 1955)开始了现代人工智能领域,到今天一些领先的AI研究公司,其使命宣言暗示了诸如“确保变革性AI帮助人类和社会”(Anthropic, 2023a)或“确保人工通用智能造福全人类”(OpenAI, 2023)等概念。 >>预测:AGI的概念与对人工智能进展的预测有关,即走向更大的通用性,接近并超越人类通用性。此外,AGI通常与“涌现”特性的概念交织在一起(Wei et al., 2022),即开发人员没有明确预期的能力。这些能力预示着希望,可能包括与典型人类技能互补的能力,促进新类型的交互或新兴产业。这种对人工智能能力的预测反过来又预测了可能的社会影响;AGI可能具有重大的经济影响,即达到广泛劳动力替代的必要标准(Dell 'Acqua等人,2023;Ellingrud et al., 2023),同时还涉及地缘政治影响,不仅涉及AGI可能带来的经济优势,还涉及军事考虑(Kissinger et al., 2022)。 >>风险:最后,AGI被一些人视为识别极端风险点的概念(Bengio et al., 2023;Shevlane et al., 2023),因为一些人推测AGI系统可能能够欺骗和操纵,积累资源,推进目标,表现出代理行为,在广泛的领域胜过人类,取代人类的关键角色,以及/或通过递归自我改进。 |
| In this paper, we argue that it is critical for the AI research community to explicitly reflect on what we mean by "AGI," and aspire to quantify attributes like the performance, generality, and autonomy of AI systems. Shared operationalizable definitions for these concepts will support: comparisons between models; risk assessments and mitigation strategies; clear criteria from policymakers and regulators; identifying goals, predictions, and risks for research and development; and the ability to understand and communicate where we are along the path to AGI. | 在本文中,我们主张 AI 研究界有必要明确反思我们所说的“AGI”是什么,并渴望量化AI系统的性能、通用性和自主性等属性是至关重要的。这些概念的可操作的共享定义将支持:模型之间的比较;风险评估和缓解策略;政策制定者和监管者制定明确的标准;确定研究和开发的目标、预测和风险失败;以及了解和传达我们在通往 AGI 道路上所处的位置(能力)。 |
Defining AGI: Case Studies—九个著名的AGI定义
| Many AI researchers and organizations have proposed definitions of AGI. In this section, we consider nine prominent examples, and reflect on their strengths and limitations. This analysis informs our subsequent introduction of a two-dimensional, leveled ontology of AGI. | 许多AI研究人员和组织已经提出了AGI的定义。在本节中,我们考虑了九个突出的例子,并反思了它们的优点和局限性。这个分析为我们随后介绍的二维、分层的AGI本体提供了信息。 |
案例研究1:图灵测试图灵测试——应该根据能力而不是过程来定义
| Case Study 1: The Turing Test. The Turing Test (Turing, 1950) is perhaps the most well-known attempt to operationalize an AGI-like concept. Turing’s “imitation game” was posited as a way to operationalize the question of whether machines could think, and asks a human to interactively distinguish whether text is produced by another human or by a machine. The test as originally framed is a thought experiment, and is the subject of many critiques (Wikipedia, 2023b); in practice, the test often highlights the ease of fooling people (Weizenbaum, 1966; Wikipedia, 2023a) rather than the “intelligence” of the machine. Given that modern LLMs pass some framings of the Turing Test, it seems clear that this criteria is insufficient for operationalizing or benchmarking AGI. We agree with Turing that whether a machine can “think,” while an interesting philosophical and scientific question, seems orthogonal to the question of what the machine can do; the latter is much more straightforward to measure and more important for evaluating impacts. Therefore we propose that AGI should be defined in terms of capabilities rather than processes2. | 案例研究1:图灵测试图灵测试(Turing Test, 1950)可能是最为人所知的将 AGI 概念操作化的尝试。图灵的“模仿游戏”被设定为一种操作方式,用来解决机器是否会思考的问题,并要求人类以互动的方式判断文本是由另一个人产生的,还是由机器产生的。测试最初的框架是一个思想实验,它是许多批评的主题(Wikipedia,2023b);在实践中,该测试往往突出了测试通常强调欺骗人们的容易程度(Weizenbaum, 1966;Wikipedia,2023a),而不是机器的“智能”。考虑到现代语言模型LLMs可以通过某些图灵测试的设定,这个标准对于操作化或衡量 AGI 显然不足。我们同意图灵的观点,机器能否“思考”,虽然是一个有趣的哲学和科学问题,但似乎与机器能做什么的问题无关;后者更容易测量,对评估影响也更重要。因此,我们建议AGI应该根据能力而不是过程来定义。 |
案例研究2:强人工智能-拥有意识的系统——过于关注过程的框架变得不切实际
| Case Study 2: Strong AI – Systems Possessing Consciousness. Philosopher John Searle mused, "according to strong AI, the computer is not merely a tool in the study of the mind; rather, the appropriately programmed computer really is a mind, in the sense that computers given the right programs can be literally said to understand and have other cognitive states" (Searle, 1980). While strong AI might be one path to achieving AGI, there is no scientific consensus on methods for determining whether machines possess strong AI attributes such as consciousness (Butlin et al., 2023), making the process-oriented focus of this framing impractical. | 案例研究2:强人工智能——拥有意识的系统。哲学家约翰·塞尔(John Searle)沉思道:“根据强人工智能,计算机不仅仅是一种研究思维的工具;相反,适当编程的计算机实际上是一种思想,从某种意义上说,计算机被赋予了正确的程序,可以从字面上说理解并具有其他认知状态”(Searle, 1980)。虽然强人工智能可能是实现AGI的一条途径,但对于确定机器是否具有强人工智能属性(如意识)的方法尚无科学共识(Butlin et al., 2023),这使得这种关注过程的框架变得不切实际。 |
案例研究3:类比人类大脑——同时强调能力和过程+transformer架构的成功
| Case Study 3: Analogies to the Human Brain. The original use of the term "artificial general intelligence" was in a 1997 article about military technologies by Mark Gubrud (Gubrud, 1997), which defined AGI as “AI systems that rival or surpass the human brain in complexity and speed, that can acquire, manipulate and reason with general knowledge, and that are usable in essentially any phase of industrial or military operations where a human intelligence would otherwise be needed.” This early definition emphasizes processes (rivaling the human brain in complexity) in addition to capabilities; while neural network architectures underlying modern ML systems are loosely inspired by the human brain, the success of transformer-based architectures (Vaswani et al., 2023) whose performance is not reliant on human-like learning suggests that strict brain-based processes and benchmarks are not inherently necessary for AGI. | 案例研究3:类比人类大脑。“通用人工智能”一词的最初使用是在1997年Mark gubroud关于军事技术的一篇文章中,该文章将AGI定义为“在复杂性和速度上与人类大脑相媲美或超过人类大脑的人工智能系统,可以获取、操纵和推理通用知识,并且基本上可以在任何需要人类智能的工业或军事行动阶段使用。”这个早期的定义除了强调能力外,还强调过程(在复杂性上与人脑相媲美);虽然现代机器学习系统底层的神经网络架构只是略微受到人类大脑的启发,但基于transformer 的架构(Vaswani et al., 2023)的成功表明,实现 AGI 并不一定需要严格基于人类类似学习的过程和基准。 |
案例研究 4:在认知任务上达到人类水平的表现——引入计算机领域+尤其关注非物理任务
| Case Study 4: Human-Level Performance on Cognitive Tasks. Legg (Legg, 2008) and Goertzel (Goertzel, 2014) popularized the term AGI among computer scientists in 2001 (Legg, 2022), describing AGI as a machine that is able to do the cognitive tasks that people can typically do. This definition notably focuses on non-physical tasks (i.e., not requiring robotic embodiment as a precursor to AGI). Like many other definitions of AGI, this framing presents ambiguity around choices such as “what tasks?” and “which people?”. | 案例研究 4:在认知任务上达到人类水平的表现。Legg (Legg, 2008)和Goertzel (Goertzel, 2014)于2001年在计算机科学家中普及了“AGI”一词(Legg, 2022),将 AGI 概念引入计算机科学领域,描述 AGI 为一种能够完成人们通常能完成的认知任务的机器。这一定义尤其关注非物理任务(即不需要机器人化身作为AGI的前身)。像许多其他的AGI定义一样,这种框架在诸如“什么任务?”和“哪些人?”等选择上存在歧义。 |
案例研究5:学习任务的能力——执行与人类一样广泛的任务
| Case Study 5: Ability to Learn Tasks. In The Technological Singularity (Shanahan, 2015), Shanahan suggests that AGI is “Artificial intelligence that is not specialized to carry out specific tasks, but can learn to perform as broad a range of tasks as a human.” An important property of this framing is its emphasis on the value of including metacognitive tasks (learning) among the requirements for achieving AGI. | 案例研究5:学习任务的能力。在《技术奇点》(The Technological Singularity, Shanahan, 2015)中,Shanahan认为AGI是“不专门执行特定任务的人工智能,但可以学习执行与人类一样广泛的任务。”这种框架的一个重要特点是它强调了在实现AGI的要求中包括元认知任务(学习)的价值。 |
案例研究6:具有经济价值的工作——衡量标准采用经济价值
| Case Study 6: Economically Valuable Work. OpenAI’s charter defines AGI as “highly autonomous systems that outperform humans at most economically valuable work” (OpenAI, 2018). This definition has strengths per the “capabilities, not processes” criteria, as it focuses on performance agnostic to underlying mechanisms; further, this definition offers a potential yardstick for measurement, i.e., economic value. A shortcoming of this definition is that it does not capture all of the criteria that may be part of “general intelligence.” There are many tasks that are associated with intelligence that may not have a well-defined economic value (e.g., artistic creativity or emotional intelligence). Such properties may be indirectly accounted for in economic measures (e.g., artistic creativity might produce books or movies, emotional intelligence might relate to the ability to be a successful CEO), though whether economic value captures the full spectrum of “intelligence” remains unclear. Another challenge with a framing of AGI in terms of economic value is that this implies a need for deployment of AGI in order to realize that value, whereas a focus on capabilities might only require the potential for an AGI to execute a task. We may well have systems that are technically capable of performing economically important tasks but don’t realize that economic value for varied reasons (legal, ethical, social, etc.). | 案例研究6:具有经济价值的工作。OpenAI的章程将AGI定义为“在最具经济价值的工作中超越人类的高度自主系统”(OpenAI, 2018)。个定义在“能力而非过程”的标准下具有优势,因为它关注的是与底层机制无关的性能;此外,这个定义提供了一个潜在的衡量标准,即经济价值。这个定义的一个缺点是,它没有涵盖“通用智能”的所有可能标准。有许多与智力相关的任务可能没有明确的经济价值(例如,艺术创造力或情感智能)。这些属性可能间接地在经济指标中得到体现(例如,艺术创造力可能产生书籍或电影,情感智能可能与成为成功 CEO 的能力相关),但经济价值是否捕捉到了“智能”的全谱仍不清楚。另一个挑战是,将 AGI 定义在经济价值方面意味着实现 AGI 的必要性,而关注能力可能只需要 AGI 执行任务的可能性潜力。我们可能拥有技术上能够执行经济上重要任务的系统,但由于各种原因(法律、道德、社会等)而没有意识到其经济价值。 |
案例研究 7:灵活且通用 - “咖啡测试”及相关挑战——需要机器人的化身
| Case Study 7: Flexible and General – The "Coffee Test" and Related Challenges. Marcus suggests that AGI is “shorthand for any intelligence (there might be many) that is flexible and general, with resourcefulness and reliability comparable to (or beyond) human intelligence” (Marcus, 2022b). This definition captures both generality and performance (via the inclusion of reliability); the mention of “flexibility” is noteworthy, since, like the Shanahan formulation, this suggests that metacognitive tasks such as the ability to learn new skills must be included in an AGI’s set of capabilities in order to achieve sufficient generality. Further, Marcus operationalizes his definition by proposing five concrete tasks (understanding a movie, understanding a novel, cooking in an arbitrary kitchen, writing a bug-free 10,000 line program, and converting natural language mathematical proofs into symbolic form) (Marcus, 2022a). Accompanying a definition with a benchmark is valuable; however, more work would be required to construct a sufficiently comprehensive benchmark. While we agree that failing some of these tasks indicates a system is not an AGI, it is unclear that passing them is sufficient for AGI status. In the Testing for AGI section, we further discuss the challenge in developing a set of tasks that is both necessary and sufficient for capturing the generality of AGI. We also note that one of Marcus’ proposed tasks, “work as a competent cook in an arbitrary kitchen” (a variant of Steve Wozniak’s “Coffee Test” (Wozniak, 2010)), requires robotic embodiment; this differs from other definitions that focus on non-physical tasks3. | 案例研究7:灵活和通用-“咖啡测试”和相关挑战。Marcus认为,AGI 是“任何灵活且通用的智能(可能有很多种)的简称,具有与(或超越)人类智能相当的智谋和可靠性”(Marcus, 2022b)。这个定义既包含了通用性,也包含了性能(通过包含可靠性);提到“灵活性”是值得注意的,因为,就像Shanahan公式一样,这表明元认知任务,如学习新技能的能力,必须包含在AGI的能力集合中,以实现足够的通用性。此外,Marcus通过提出五个具体任务(理解一部电影、理解一部小说、在任意一个厨房做饭、编写一个没有错误的10,000行程序,以及将自然语言数学证明转换为符号形式)来实现他的定义(Marcus, 2022a)。定义和基准是有价值的;但是,要建立一个足够全面的基准,还需要做更多的工作。虽然我们同意这些任务中的一些失败表明系统不是AGI,但尚不确定通过这些任务是否足以获得 AGI 地位。在测试AGI一节中,我们将进一步讨论开发一组任务所面临的挑战,这些任务对于捕获AGI的通用性既必要又充分。我们还注意到,Marcus 提出的任务之一,“在一个任意的厨房里做一个称职的厨师”(史蒂夫·沃兹尼亚克的“咖啡测试”(沃兹尼亚克,2010)的变体),需要机器人的化身;这与其他侧重于非物理任务的定义不同 |
案例研究 8:人工有能力智能——现代的图灵测试+有足够性能和通用性的AI系统可完成复杂的多步骤任务
| Case Study 8: Artificial Capable Intelligence. In The Coming Wave, Suleyman proposed the concept of "Artificial Capable Intelligence (ACI)" (Mustafa Suleyman and Michael Bhaskar, 2023) to refer to AI systems with sufficient performance and generality to accomplish complex, multi-step tasks in the open world. More specifically, Suleyman proposed an economically-based definition of ACI skill that he dubbed the “Modern Turing Test,” in which an AI would be given $100,000 of capital and tasked with turning that into $1,000,000 over a period of several months. This framing is more narrow than OpenAI’s definition of economically valuable work and has the additional downside of potentially introducing alignment risks (Kenton et al., 2021) by only targeting fiscal profit. However, a strength of Suleyman’s concept is the focus on performing a complex, multi-step task that humans value. Construed more broadly than making a million dollars, ACI’s emphasis on complex, real-world tasks is noteworthy, since such tasks may have more ecological validity than many current AI benchmarks; Marcus’ aforementioned five tests of flexibility and generality (Marcus, 2022a) seem within the spirit of ACI, as well. | 案例研究8:人工有能力智能。在《即将到来的浪潮》一书中,Suleyman 提出了“人工有能力智能(Artificial Capable Intelligence, ACI)”的概念。(Mustafa Suleyman和Michael Bhaskar, 2023),指具有足够性能和通用性的AI系统,可以在开放世界中完成复杂的多步骤任务。更具体地说,Suleyman 提出了一个基于经济学的ACI技能定义,他称之为“现代图灵测试”,在这个测试中,一个AI将获得10万美元的资本,并被要求在几个月内将其变成100万美元。这种框架比OpenAI对经济上有价值的工作的定义更狭隘,并且由于只以财政利润为目标,可能会引入一致性风险(Kenton et al., 2021)。但 Suleyman 的概念的一个优点是关注完成复杂、多步骤的人价值任务。从更广泛的角度来看,ACI对复杂的现实世界任务的强调值得注意,因为这些任务可能比许多当前的人工智能基准更具生态有效性;Marcus前面提到的五个灵活性和普遍性测试(Marcus, 2022a)似乎也符合ACI的精神。 |
案例研究 9:最新大型语言模型作为通才——已经实现了足够的普遍性
| Case Study 9: SOTA LLMs as Generalists. Agüera y Arcas and Norvig (Agüera y Arcas and Norvig, 2023) suggested that state-of-the-art LLMs (e.g. mid-2023 deployments of GPT-4, Bard, Llama 2, and Claude) already are AGIs, arguing that generality is the key property of AGI, and that because language models can discuss a wide range of topics, execute a wide range of tasks, handle multimodal inputs and outputs, operate in multiple languages, and “learn” from zero-shot or few-shot examples, they have achieved sufficient generality. While we agree that generality is a crucial characteristic of AGI, we posit that it must also be paired with a measure of performance (i.e., if an LLM can write code or perform math, but is not reliably correct, then its generality is not yet sufficiently performant). | 案例研究9: SOTA LLMs作为通才。Agüera y Arcas 和 Norvig(Agüera y Arcas 和 Norvig,2023)认为,当前最先进的 LLM(例如,2023 年中期的 GPT-4、Bard、Llama 2 和 Claude 部署)已经是 AGI,他们认为普遍性是 AGI 的关键属性,因为语言模型可以讨论各种主题,执行各种任务,处理多模态输入和输出,操作多种语言,以及从零散或少量示例中“学习”,所以它们已经实现了足够的普遍性。虽然我们同意通用性是AGI的关键特征,但我们认为它还必须与性能指标相结合(即,如果一个 LLM 可以编写代码或进行数学运算,但不是可靠的正确,那么它的普遍性还不足以实现高性能)。 |
Defining AGI: Six Principles框架的六大原则
| Reflecting on these nine example formulations of AGI (or AGI-adjacent concepts), we identify properties and commonalities that we feel contribute to a clear, operationalizable definition of AGI. We argue that any definition of AGI should meet the following six criteria: | 反思这九个AGI(或AGI相关概念)的例子公式,我们确定了我们认为有助于明确、可操作AGI定义的属性和共性。我们主张任何AGI定义都应该满足以下六个标准: |
原则1、关注能力,而不是过程——不一定要以人类的方式思考+不一定要具有自主意识
| 1、Focus on Capabilities, not Processes. The majority of definitions focus on what an AGI can accomplish, not on the mechanism by which it accomplishes tasks. This is important for identifying characteristics that are not necessarily a prerequisite for achieving AGI (but may nonetheless be interesting research topics). This focus on capabilities allows us to exclude the following from our requirements for AGI: >> Achieving AGI does not imply that systems think or understand in a human-like way (since this focuses on processes, not capabilities) >> Achieving AGI does not imply that systems possess qualities such as consciousness (subjective awareness) (Butlin et al., 2023) or sentience (the ability to have feelings) (since these qualities not only have a process focus, but are not currently measurable by agreed-upon scientific methods) | 1、关注能力,而不是过程。大多数定义关注的是AGI可以完成什么,而不是它完成任务的机制。这一点对于识别不是 AGI 必要前提的特征(但可能仍然是有趣的研究主题)非常重要。这种对能力的关注使我们能够从AGI需求中排除以下内容: >>实现AGI并不意味着系统以类似人类的方式思考或理解(因为它关注的是过程,而不是能力) >>实现AGI并不意味着系统拥有意识(主观意识)(Butlin等人,2023)或感知(感受能力)等品质(但这些品质不仅关注过程,而且目前无法通过公认的科学方法进行测量)。 |
原则2、关注通用性和性能
| 2、Focus on Generality and Performance. All of the above definitions emphasize generality to varying degrees, but some exclude performance criteria. We argue that both generality and performance are key components of AGI. In the next section we introduce a leveled taxonomy that considers the interplay between these dimensions. | 2、关注通用性和性能。所有上述定义都在不同程度上强调了通用性,但有些定义排除了性能标准。我们认为通用性和性能都是AGI的关键组成部分。在下一部分,我们将引入一个层次分类,考虑这些维度的相互作用。 |
原则3、关注认知和元认知任务——执行物理任务可提高通用性,但不应被视为AGI必备条件+元认知能力对系统获得通用性来说很重要
| 3、Focus on Cognitive and Metacognitive Tasks. Whether to require robotic embodiment (Roy et al., 2021) as a criterion for AGI is a matter of some debate. Most definitions focus on cognitive tasks, by which we mean non-physical tasks. Despite recent advances in robotics (Brohan et al., 2023), physical capabilities for AI systems seem to be lagging behind non-physical capabilities. It is possible that embodiment in the physical world is necessary for building the world knowledge to be successful on some cognitive tasks (Shanahan, 2010), or at least may be one path to success on some classes of cognitive tasks; if that turns out to be true then embodiment may be critical to some paths toward AGI. We suggest that the ability to perform physical tasks increases a system’s generality, but should not be considered a necessary prerequisite to achieving AGI. On the other hand, metacognitive capabilities (such as the ability to learn new tasks or the ability to know when to ask for clarification or assistance from a human) are key prerequisites for systems to achieve generality. | 3、关注认知和元认知任务。是否需要机器人化身(Roy et al., 2021)作为AGI的标准是一个有争议的问题。大多数定义侧重于认知任务,即非物理任务。尽管最近在机器人领域取得了突破(Brohan et al., 2023),但人工智能系统的物理能力似乎落后于非物理能力。可能需要在物理世界中具有一定程度的实体化才能在某些认知任务上取得成功(Shanahan,2010),或者至少是成功的一途径;如果是那样的话,实体化可能是实现 AGI 的重要途径。我们认为,执行物理任务的能力增加了系统的通用性,但不应被视为实现AGI的必要先决条件。另一方面,元认知能力(例如学习新任务的能力或知道何时向人类寻求澄清或协助的能力)是系统实现通用性的关键先决条件。 |
原则4、关注潜力,而不是部署——判断一个系统是否为AGI应基于它能够展示达到一定水平完成必需任务集合的潜在能力,而不应考虑其是否实际部署(会带来法律和伦理问题)
| 4、Focus on Potential, not Deployment. Demonstrating that a system can perform a requisite set of tasks at a given level of performance should be sufficient for declaring the system to be an AGI; deployment of such a system in the open world should not be inherent in the definition of AGI. For instance, defining AGI in terms of reaching a certain level of labor substitution would require real-world deployment, whereas defining AGI in terms of being capable of substituting for labor would focus on potential. Requiring deployment as a condition of measuring AGI introduces non-technical hurdles such as legal and social considerations, as well as potential ethical and safety concerns. | 4、关注潜力,而不是部署。证明一个系统能在给定性能水平上完成一组必要任务,应该足以宣布该系统为AGI;在现实世界中部署这样一个系统不应该是AGI定义所固有的。将此类系统在现实世界的部署视为AGI定义的一部分,并不合适。 例如,根据达到一定程度的劳动力替代来定义AGI需要在现实世界中部署,而根据能够替代劳动力来定义AGI则侧重于潜力。将部署作为衡量AGI的条件会引入非技术障碍,如法律和社会考虑,以及潜在的道德和安全问题。 |
原则5、关注生态有效性(即与人类社会中各种形式价值的实际任务相一致,)
| 5、Focus on Ecological Validity. Tasks that can be used to benchmark progress toward AGI are critical to operationalizing any proposed definition. While we discuss this further in the “Testing for AGI” section, we emphasize here the importance of choosing tasks that align with real-world (i.e., ecologically valid) tasks that people value (construing “value” broadly, not only as economic value but also social value, artistic value, etc.). This may mean eschewing traditional AI metrics that are easy to automate or quantify (Raji et al., 2021) but may not capture the skills that people would value in an AGI. | 5、关注生态有效性。可以用来评估AGI进展的任务对于实施任何提议的定义都是至关重要的。虽然我们在“测试AGI”一节中进一步讨论了这一点,但我们在这里强调选择与人们重视的现实世界(即生态有效)任务相一致的任务的重要性(将“价值”理解为广泛的概念,不仅限于经济价值,还包括社会价值、艺术价值等)。这可能意味着放弃易于自动化或量化的传统人工智能指标(Raji等人,2021),但可能无法捕获人们在AGI中看重的技能。 |
原则6、关注通往AGI的路径,而非单一终点——提出一套类似同级驾驶水平的“AGI水平分类”也有利于明确AGI政策进度和不同定义的整合
论文认为,继同级驾驶水平概念成功指导自动驾驶政策和进度讨论后,提出一套“AGI水平分类”也有利于明确AGI政策进度和不同定义的整合,为下一节将要介绍的基于能力深浅和广度的AGI水平体系奠定基础。
| 6、Focus on the Path to AGI, not a Single Endpoint. Much as the adoption of a standard set of Levels of Driving Automation (SAE International, 2021) allowed for clear discussions of policy and progress relating to autonomous vehicles, we posit there is value in defining “Levels of AGI.” As we discuss in subsequent sections, we intend for each level of AGI to be associated with a clear set of metrics/benchmarks, as well as identified risks introduced at each level, and resultant changes to the Human-AI Interaction paradigm (Morris et al., 2023). This level-based approach to defining AGI supports the coexistence of many prominent formulations – for example, Aguera y Arcas & Norvig’s definition (Agüera y Arcas and Norvig, 2023) would fall into the “Emerging AGI” category of our ontology, while OpenAI’s threshold of labor replacement (OpenAI, 2018) better matches “Virtuoso AGI.” Our “Competent AGI” level is probably the best catch-all for many existing definitions of AGI (e.g., the Legg (Legg, 2008), Shanahan (Shanahan, 2015), and Suleyman (Mustafa Suleyman and Michael Bhaskar, 2023) formulations). In the next section, we introduce a level-based ontology of AGI. | 6、专注于通往AGI的道路,而不是单一的终点。正如采用一套标准的自动驾驶水平(SAE International, 2021)允许对与自动驾驶汽车相关的政策和进展进行清晰的讨论一样,我们认为定义“AGI级别”是有价值的。正如我们在后续章节中讨论的那样,我们打算将AGI的每个级别与一组明确的指标/基准相关联,以及在每个级别引入的识别风险,以及人与AI交互范式的最终变化(Morris等人,2023)。这种基于层次的定义AGI的方法支持许多著名公式的共存——例如,Aguera y Arcas和Norvig的定义(ag<s:1> era y Arcas和Norvig, 2023)将属于我们本体的“Emerging AGI”类别,而OpenAI的劳动力替代门槛(OpenAI,2018)则与“Virtuoso AGI”更好地匹配。我们的“Competent AGI”水平可能是许多现有AGI定义(例如Legg (Legg, 2008), Shanahan (Shanahan, 2015)和Suleyman (Mustafa Suleyman和Michael Bhaskar, 2023)公式)的最佳概括。在下一节中,我们将介绍基于级别的AGI本体。 |
Levels of AGI —AGI的级别
表1 | 根据深度(性能)和广度(通用性)对通往AGI的道路上的系统进行分类的层级矩阵方法
| Table 1 | A leveled, matrixed approach toward classifying systems on the path to AGI based on depth (performance) and breadth (generality) of capabilities. Example systems in each cell are approximations based on current descriptions in the literature or experiences interacting with deployed systems. Unambiguous classification of AI systems will require a standardized benchmark of tasks, as we discuss in the Testing for AGI section. | 表1:对系统进行分级的矩阵方法 表1 |基于能力的深度(性能)和广度(一般性),在通往AGI的道路上对系统进行分类的一种分层的矩阵方法。每个单元格中的示例系统是基于文献中的当前描述或与部署系统互动的经验的近似值。AI系统的明确分类将需要一个标准化的任务基准,正如我们在“AGI测试”部分中讨论的那样。 |
AGI的级别六个等级(0~5):No AI(无人工智能)→Emerging(等于或略优于不熟练的人类,如符号化的智能)→Competent(至少达到成年人的50%,如智能音箱Siri)→Expert(至少达到成年人的90%,如生成图像模型Dall-E)→Virtuoso(至少达到成年人的99%,如AlphaGo )→SuperHuman(超过100%的人类表现,如AlphaFold/AlphaZero等)
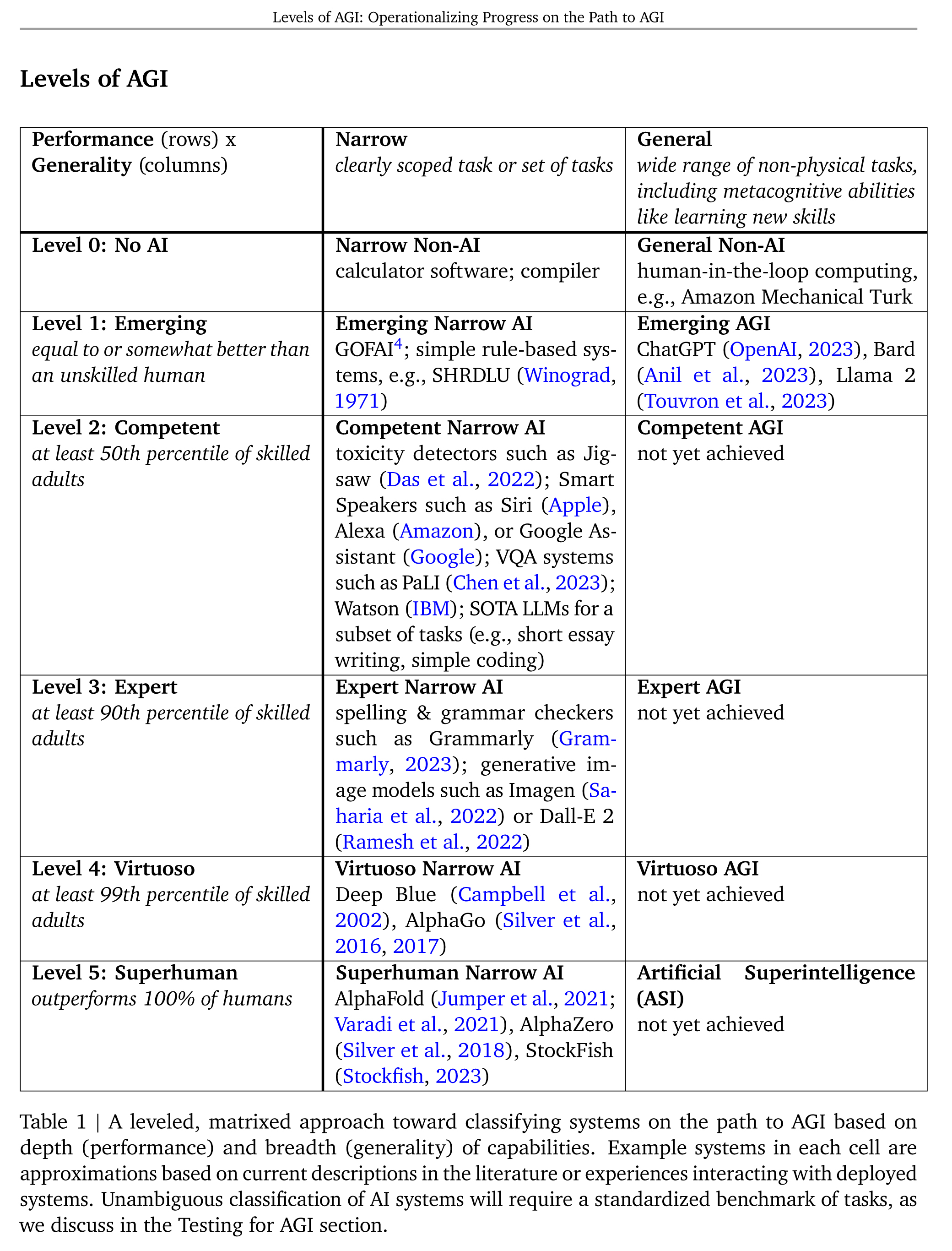
| Performance (rows) x Generality (columns) 表现(行)x 通用性(列) | Narrow clearly scoped task or set of tasks 明确定义的任务或任务集 | General wide range of non-physical tasks, including metacognitive abilities like learning new skills 广泛的非物理任务,包括元认知能力,如学习新技能 |
| Level 0: No AI 级别 0:无人工智能 | Narrow Non-AI calculator software; compiler 狭窄无人工智能 计算器软件;编译器 | General Non-AI human-in-the-loop computing, e.g., Amazon Mechanical Turk 通用人工智能 人在环计算,例如,亚马逊Mechanical Turk |
| Level 1: Emerging equal to or somewhat better than an unskilled human 级别 1:新兴 等于或略优于不熟练的人类 | Emerging Narrow AI GOFAI4; simple rule-based systems, e.g., SHRDLU (Winograd,1971) 新兴狭窄人工智能 符号化的智能(GOFAI);简单的基于规则的系统,例如 SHRDLU (Winograd, 1971) | Emerging AGI ChatGPT (OpenAI, 2023), Bard(Anil et al., 2023), Llama 2(Touvron et al., 2023) 新兴通用人工智能 ChatGPT (OpenAI, 2023);Bard (Anil et al., 2023);Llama 2 (Touvron et al., 2023) |
| Level 2: Competent at least 50th percentile of skilled adults 级别 2:胜任 至少达到熟练成年人的50百分位数 | Competent Narrow AI toxicity detectors such as Jigsaw (Das et al., 2022); Smart Speakers such as Siri (Apple), Alexa (Amazon), or Google Assistant (Google); VQA systems such as PaLI (Chen et al., 2023); Watson (IBM); SOTA LLMs for a subset of tasks (e.g., short essay writing, simple coding) 胜任狭窄人工智能 毒性检测器,如 Jigsaw (Das et al., 2022);智能音箱,如 Siri (Apple)、Alexa (Amazon) 或 Google Assistant (Google);视觉问题回答系统,如 PaLI (Chen et al., 2023);Watson (IBM);某些任务的最先进语言模型,例如短文写作,简单编码 | Competent AGI not yet achieved 胜任通用人工智能 尚未实现 |
| Level 3: Expert at least 90th percentile of skilled adults 级别 3:专家 至少达到熟练成年人的90百分位数 | Expert Narrow AI spelling & grammar checkers such as Grammarly (Grammarly, 2023); generative image models such as Imagen (Saharia et al., 2022) or Dall-E 2 (Ramesh et al., 2022) 专家狭窄人工智能 拼写和语法检查器,如 Grammarly (Grammarly, 2023);生成图像模型,如 Imagen (Saharia et al., 2022) 或 Dall-E 2 (Ramesh et al., 2022) | Expert AGI not yet achieved 专业通用人工智能 尚未实现 |
| Level 4: Virtuoso at least 99th percentile of skilled adults 级别 4:大师 至少达到熟练成年人的99百分位数 | Virtuoso Narrow AI Deep Blue (Campbell et al., 2002), AlphaGo (Silver et al., 2016, 2017) 大师狭窄人工智能 Deep Blue (Campbell et al., 2002);AlphaGo (Silver et al., 2016, 2017) | Virtuoso AGI not yet achieved 大师通用人工智能 尚未实现 |
| Level 5: Superhuman outperforms 100% of humans 级别 5:超人 超过100%的人类表现 | Superhuman Narrow AI AlphaFold (Jumper et al., 2021;Varadi et al., 2021), AlphaZer (Silver et al., 2018), StockFish(Stockfish, 2023) 超人狭窄人工智能 AlphaFold (Jumper et al., 2021; Varadi et al., 2021);AlphaZero (Silver et al., 2018);StockFish (Stockfish, 2023) | Artificial Superintelligence(ASI) not yet achieved 人工超级智能(ASI) 尚未实现 |
AI系统能力的深度和广度:引入了一个关注“性能”和“通用性”的矩阵层级系统
| In accordance with Principle 2 ("Focus on Generality and Performance") and Principle 6 ("Focus on the Path to AGI, not a Single Endpoint"), in Table 1 we introduce a matrixed leveling system that focuses on performance and generality as the two dimensions that are core to AGI: >> Performance refers to the depth of an AI system’s capabilities, i.e., how it compares to human- level performance for a given task. Note that for all performance levels above “Emerging,” percentiles are in reference to a sample of adults who possess the relevant skill (e.g., “Competent” or higher performance on a task such as English writing ability would only be measured against the set of adults who are literate and fluent in English). >> Generality refers to the breadth of an AI system’s capabilities, i.e., the range of tasks for which an AI system reaches a target performance threshold. | 根据原则2(“关注通用性和性能”)和原则6(“关注AGI的路径,而不是单一端点”),在表1中我们引入了一个关注性能和通用性的矩阵层级系统:这两个维度是AGI的核心: >> 性能是指AI系统能力的深度,即它在给定任务上与人类水平表现的比较。需要注意的是,对于所有性能水平高于“ Emerging”的系统,百分位数是指拥有相关技能的成年人样本(例如,在英语写作能力等任务中,“胜任”或更高的表现只能与识字和流利英语的成年人进行比较)。 >>通用性指的是AI系统能力的广度,即AI系统达到目标性能阈值的任务范围。 |
Emerging AGI→Competent AGI:目前的ChatGPT处于一级通用人工智能
| This taxonomy specifies the minimum performance over most tasks needed to achieve a given rating – e.g., a Competent AGI must have performance at least at the 50th percentile for skilled adult humans on most cognitive tasks, but may have Expert, Virtuoso, or even Superhuman performance on a subset of tasks. As an example of how individual systems may straddle different points in our taxonomy, we posit that as of this writing in September 2023, frontier language models (e.g., ChatGPT (OpenAI, 2023), Bard (Anil et al., 2023), Llama2 (Touvron et al., 2023), etc.) exhibit “Competent” performance levels for some tasks (e.g., short essay writing, simple coding), but are still at “Emerging” performance levels for most tasks (e.g., mathematical abilities, tasks involving factuality). Overall, current frontier language models would therefore be considered a Level 1 General AI (“Emerging AGI”) until the performance level increases for a broader set of tasks (at which point the Level 2 General AI, “Competent AGI,” criteria would be met). We suggest that documentation for frontier AI models, such as model cards (Mitchell et al., 2019), should detail this mixture of performance levels. This will help end-users, policymakers, and other stakeholders come to a shared, nuanced understanding of the likely uneven performance of systems progressing along the path to AGI. | 这个分类法规定了在大多数任务中达到给定评级所需的最低表现——例如,一个称职的AGI在大多数认知任务中必须至少达到熟练成年人的第50百分位,但在某些任务子集上可能具有专家, Virtuoso,甚至超人的表现。作为个体系统如何跨越我们分类法中不同点的一个例子,我们假设在2023年9月撰写本文时,前沿语言模型(例如,ChatGPT (OpenAI, 2023), Bard (Anil等人,2023),Llama2 (Touvron等人,2023)等)在某些任务(例如,短文写作,简单编码)中表现出“胜任”的性能水平,但对于大多数任务(例如,数学能力,涉及事实性的任务)仍处于“Emerging”性能水平。总的来说,目前的前沿语言模型因此将被视为一级通用人工智能(“Emerging AGI”),直到性能水平提高到更广泛的任务集(此时将满足二级通用人工智能,“Competent AGI”标准)。我们建议前沿人工智能模型的文档,如模型卡(Mitchell et al., 2019),应该详细说明这种性能水平的混合。这将有助于最终用户、政策制定者和其他利益相关者对系统在通往AGI的道路上可能出现的不平衡表现有一个共同的、细致入微的理解。 |
获得技能的顺序、两种能力的非线性(性能和通用性)
| The order in which stronger skills in specific cognitive areas are acquired may have serious implications for AI safety (e.g., acquiring strong knowledge of chemical engineering before acquiring strong ethical reasoning skills may be a dangerous combination). Note also that the rate of progression between levels of performance and/or generality may be nonlinear. Acquiring the capability to learn new skills may particularly accelerate progress toward the next level. | 在特定认知领域获得更强技能的顺序可能会对人工智能的安全性产生严重影响(例如,在获得强大的道德推理技能之前获得强大的化学工程知识可能是一种危险的组合)。还要注意,性能水平和/或通用性水平之间的进展速度可能是非线性的。获得学习新技能的能力可能会加速你迈向下一个阶段。 |
Expert:强调设计考虑实际性能的评估标准,以及人机交互方式如何影响判断AGI水平——比如DALL-E2在理论上达“Expert专家”水平,但界面限制可能只达“Competent熟练”水平
| While this taxonomy rates systems according to their performance, systems that are capable of achieving a certain level of performance (e.g., against a given benchmark) may not match this level in practice when deployed. For instance, user interface limitations may reduce deployed performance. Consider the example of DALLE-2 (Ramesh et al., 2022), which we estimate as a Level 3 Narrow AI (“Expert Narrow AI”) in our taxonomy. We estimate the “Expert” level of performance since DALLE-2 produces images of higher quality than most people are able to draw; however, the system has failure modes (e.g., drawing hands with incorrect numbers of digits, rendering nonsensical or illegible text) that prevent it from achieving a “Virtuoso” performance designation. While theoretically an “Expert” level system, in practice the system may only be “Competent,” because prompting interfaces are too complex for most end-users to elicit optimal performance (as evidenced by the existence of marketplaces (e.g., (PromptBase)) in which skilled prompt engineers sell prompts). This observation emphasizes the importance of designing ecologically valid benchmarks (that would measure deployed rather than idealized performance) as well as the importance of considering how human-AI interaction paradigms interact with the notion of AGI (a topic we return to in the “Capabilities vs. Autonomy” Section). | 尽管此分类根据性能对系统进行了评级,但达到一定性能水平(例如,针对给定基准)的系统在实际部署时可能不会达到此级别。例如,用户界面的限制可能会降低部署的性能。考虑DALLE-2的例子(Ramesh等人,2022),我们估计它是我们分类法中的3级窄AI(“Expert Narrow AI”)。我们估计“Expert”级别的性能,因为DALLE-2产生的图像质量高于大多数人所能绘制的水平;然而,该系统具有故障模式(例如,用不正确的数字绘制手,呈现无意义或难以辨认的文本),使其无法获得“Virtuoso”性能评级。尽管从理论上来说,该系统属于“Expert”级别,但实际上,由于提示界面对于大多数终端用户来说过于复杂,无法激发最佳性能,因此该系统的实际性能可能仅为“Competent胜任”(如市场的存在(例如,(PromptBase)),熟练的提示工程师在其中销售提示)。这一观察强调了设计生态有效基准的重要性(这将衡量已部署的性能,而不是理想化的性能),以及考虑人类与人工智能交互范式如何与AGI概念交互的重要性(我们将在“能力与自主性”一节中回到这个主题)。 |
SuperHuman/ASI:超越人类水平100%的表现+拥有非人类技能(神经接口/神谕能力/与动物交流等),比如AlphaFold在单项任务上超越顶级科学家
将矩阵中综合表现力和通用性最高的水平定义为人工超级智能(ASI),将超越人类水平100%的表现定性为“超人”水平,比如AlphaFold在单项任务上超越顶级科学家,因此它将ASI水平定义为能够在范围广泛的任务上超越人类的通用系统。
| The highest level in our matrix in terms of combined performance and generality is ASI (Artificial Superintelligence). We define "Superhuman" performance as outperforming 100% of humans. For instance, we posit that AlphaFold (Jumper et al., 2021; Varadi et al., 2021) is a Level 5 Narrow AI ("Superhuman Narrow AI") since it performs a single task (predicting a protein’s 3D structure from an amino acid sequence) above the level of the world’s top scientists. This definition means that Level 5 General AI ("ASI") systems will be able to do a wide range of tasks at a level that no human can match. Additionally, this framing also implies that Superhuman systems may be able to perform an even broader generality of tasks than lower levels of AGI, since the ability to execute tasks that qualitiatively differ from existing human skills would by definition outperform all humans (who fundamentally cannot do such tasks). For example, non-human skills that an ASI might have could include capabilities such as neural interfaces (perhaps through mechanisms such as analyzing brain signals to decode thoughts (Tang et al., 2023)), oracular abilities (perhaps through mechanisms such as analyzing large volumes of data to make high-quality predictions), or the ability to communicate with animals (perhaps by mechanisms such as analyzing patterns in their vocalizations, brain waves, or body language). | 就综合性能和通用性而言,我们矩阵中的最高级别是ASI(人工超级智能)。我们把"Superhuman"的表现定义为超越100%的人类。例如,我们假设AlphaFold (Jumper et al., 2021;Varadi等人,2021)是第5级窄AI(“Superhuman Narrow AI”),因为它执行的单一任务(从氨基酸序列预测蛋白质的3D结构)高于世界顶级科学家的水平。这一定义意味着5级通用人工智能(“ASI”)系统将能够在广泛的任务上达到人类无法匹敌的水平。此外,这种框架还意味着超级智能系统可能能够执行比低级AGI更广泛的任务,因为执行与现有人类技能有本质区别的任务的能力,从定义上讲,将优于所有人类(从根本上说,人类无法完成这些任务)。例如,ASI可能拥有的非人类技能可能包括神经接口(可能通过分析大脑信号来解码思想(Tang et al., 2023)等机制)、神谕能力(可能通过分析大量数据以做出高质量预测等机制)或与动物交流的能力(可能通过分析动物发声模式、脑电波或肢体语言等机制)。 |
Testing for AGI—AGI测试
运用"水平制度"框架衡量AGI的两个核心指标是能力广度和深度
| Two of our six proposed principles for defining AGI (Principle 2: Generality and Performance; Principle 6: Focus on the Path to AGI) influenced our choice of a matrixed, leveled ontology for facilitating nuanced discussions of the breadth and depth of AI capabilities. Our remaining four principles (Principle 1: Capabilities, not Processes; Principle 3: Cognitive and Metacognitive Tasks; Principle 4: Potential, not Deployment; and Principle 5: Ecological Validity) relate to the issue of measurement. | 我们提出的定义AGI的六个原则中的两个(原则2:通用性和性能;原则6关注AGI的发展路径)影响了我们选择矩阵式、分层的本体,以促进对AI能力广度和深度的细致讨论。我们剩下的四个原则(原则1:能力,而不是过程;原理3:认知和元认知任务;原则4:潜力,而不是部署;和原则5:生态有效性)与测量问题有关。 |
测量问题:性能维度涉及任务表现的百分位范围
| While our performance dimension specifies one aspect of measurement (e.g., percentile ranges for task performance relative to particular subsets of people), our generality dimension leaves open important questions: What is the set of tasks that constitute the generality criteria? What proportion of such tasks must an AI system master to achieve a given level of generality in our schema? Are there some tasks that must always be performed to meet the criteria for certain generality levels, such as metacognitive tasks? | 虽然我们的性能维度度明确了测量的一个方面(例如,与特定子集人群相比的任务性能的百分位数范围),但通用性维度仍留下了一些重要问题:构成通用性标准的任务集是什么?AI系统必须掌握多少比例的此类任务才能在我们的模式中达到给定的通用性水平?是否有一些任务必须始终执行以满足某些一般性水平的标准,例如元认知任务? |
实现AGI定义的挑战:回答广泛性维度的问题,以及开发具体多样且具有挑战性的任务+复杂性巨大,需要涵盖广泛的观点
AGI基准的特性:未提出具体基准,而是明确基准应该测量的本体+强调基准应包括广泛的认知和元认知任务
| Operationalizing an AGI definition requires answering these questions, as well as developing specific diverse and challenging tasks. Because of the immense complexity of this process, as well as the importance of including a wide range of perspectives (including cross-organizational and multi-disciplinary viewpoints), we do not propose a benchmark in this paper. Instead, we work to clarify the ontology a benchmark should attempt to measure. We also discuss properties an AGI benchmark should possess. Our intent is that an AGI benchmark would include a broad suite of cognitive and metacognitive tasks (per Principle 3), measuring diverse properties including (but not limited to) linguistic intel- ligence, mathematical and logical reasoning (Webb et al., 2023), spatial reasoning, interpersonal and intra-personal social intelligences, the ability to learn new skills and creativity. A benchmark might include tests covering psychometric categories proposed by theories of intelligence from psy- chology, neuroscience, cognitive science, and education; however, such “traditional” tests must first be evaluated for suitability for benchmarking computing systems, since many may lack ecological and construct validity in this context (Serapio-García et al., 2023). One open question for benchmarking performance is whether to allow the use of tools, including potentially AI-powered tools, as an aid to human performance. This choice may ultimately be task dependent and should account for ecological validity in benchmark choice (per Principle 5). For example, in determining whether a self-driving car is sufficiently safe, benchmarking against a person driving without the benefit of any modern AI-assisted safety tools would not be the most informative comparison; since the relevant counterfactual involves some driver-assistance technology, we may prefer a comparison to that baseline. | 要将AGI定义付诸实践,需要回答这些问题,同时也需要开发具体、多样且具有挑战性的任务。由于这个过程的巨大复杂性,以及包括广泛的观点(包括跨组织和多学科的观点)的重要性,我们在本文中没有提出一个基准。相反,我们努力澄清基准应该试图测量的本体。我们还讨论了AGI基准应该具备的属性。 我们的意图是,AGI基准将包括一系列广泛的认知和元认知任务(根据原则3),测量各种属性,包括(但不限于)语言智能、数学和逻辑推理(Webb等人,2023)、空间推理、人际和自我社交智能、学习新技能和创造力的能力。基准测试可能包括由心理学、神经科学、认知科学和教育等智力理论提出的心理测量类别的测试;但是,这些“传统”的测试首先必须评估其适用于计算系统基准的适用性,因为在当前背景下许多测试可能缺乏生态和构造有效性(Serapio-García等人,2023)。 衡量性能的一个开放性问题是否允许使用工具,包括潜在的人工智能工具,作为提高人类绩效的辅助。这个选择可能最终取决于任务,并且应该考虑到基准选择的生态有效性(根据原则5)。例如,在确定自动驾驶汽车是否足够安全时,在没有任何现代AI辅助安全工具的情况下,与不使用任何现代AI辅助安全工具的人进行基准比较可能不是最有意义的比较;由于相关的反事实涉及一些驾驶辅助技术,我们可能更喜欢与该基线进行比较。 |
AGI基准的性质:AGI标准应参考现有标准并包括开放式任务,后者可能更贴近真实场景但难定量+AGI标准应持续更新(基准是动态)
| While an AGI benchmark might draw from some existing AI benchmarks (Lynch, 2023) (e.g., HELM (Liang et al., 2023), BIG-bench (Srivastava et al., 2023)), we also envision the inclusion of open-ended and/or interactive tasks that might require qualitative evaluation (Bubeck et al., 2023; Papakyriakopoulos et al., 2021; Yang et al., 2023). We suspect that these latter classes of complex, open-ended tasks, though difficult to benchmark, will have better ecological validity than traditional AI metrics, or than adapted traditional measures of human intelligence. It is impossible to enumerate the full set of tasks achievable by a sufficiently general intelligence. As such, an AGI benchmark should be a living benchmark. Such a benchmark should therefore include a framework for generating and agreeing upon new tasks. | 虽然AGI基准可能会从一些现有的AI基准(Lynch, 2023)(例如,HELM (Liang等人,2023),BIG-bench (Srivastava等人,2023))中借鉴,但我们还设想包括一些开放性和/或交互式任务,这些任务可能需要定性评估(Bubeck等人,2023;Papakyriakopoulos等人,2021;Yang等人,2023)。我们怀疑,后一类复杂、开放式的任务,尽管很难进行基准测试,但与传统的人工智能指标或经过调整的传统人类智能衡量标准相比,将具有更好的生态有效性。 要列举一个足够通用的智能所能完成的全部任务是不可能的。因此,AGI基准应该是一个动态的基准。因此,这种基准应包括一个生成和达成新任务的框架。 |
确定非AGI的任务:无法详尽列出所有任务但可通过新任务确定系统不是某水平AGI
| Determining that something is not an AGI at a given level simply requires identifying several5 tasks that people can typically do but the system cannot adequately perform. Systems that pass the majority of the envisioned AGI benchmark at a particular performance level ("Emerging," "Competent," etc.), including new tasks added by the testers, can be assumed to have the associated level of generality for practical purposes (i.e., though in theory there could still be a test the AGI would fail, at some point unprobed failures are so specialized or atypical as to be practically irrelevant). | 要确定某件事在给定级别上是不是AGI,只需找出几个典型的人可以完成而系统无法充分执行的任务即可。在特定性能水平(“Emerging”、“Competent”等)上通过大多数设想的AGI基准的系统,包括测试人员添加的新任务,可以被认为具有与实际目的相关的通用性水平(即,尽管理论上仍然可能存在AGI会失败的测试,但在某些时候,未被探测到的失败案是如此专业或非典型,以至于实际上无关紧要) |
构建AGI标准将是长期工作,但有助明确目标和衡量进步
| Developing an AGI benchmark will be a challenging and iterative process. It is nonetheless a valuable north-star goal for the AI research community. Measurement of complex concepts may be imperfect, but the act of measurement helps us crisply define our goals and provides an indicator of progress. | 制定AGI基准将是一个具有挑战性和迭代的过程。尽管如此,它仍然是AI研究界一个有价值的北极星目标。测量复杂概念可能是不完美的,但是度量的行为可以帮助我们清晰地定义我们的目标,并提供一个进度指示器。 |
Risk in Context: Autonomy and Human-AI Interaction情境中的风险:自主性与人工智能交互
| Discussions of AGI often include discussion of risk, including "x-risk" – existential (for AI Safety, 2023) or other very extreme risks (Shevlane et al., 2023). A leveled approach to defining AGI enables a more nuanced discussion of how different combinations of performance and generality relate to different types of AI risk. While there is value in considering extreme risk scenarios, understanding AGI via our proposed ontology rather than as a single endpoint (per Principle 6) can help ensure that policymakers also identify and prioritize risks in the near-term and on the path to AGI. | 情境中的风险:自主性和人机交互 关于AGI的讨论通常包括对风险的讨论,包括“x风险”——存在性风险(对人机安全来说,2023)或其他非常极端的风险(Shevlane et al., 2023)。定义AGI的分层方法可以更细致地讨论性能和通用性的不同组合如何与不同类型的AI风险相关。虽然考虑极端风险场景是有价值的,但通过我们提出的本体来理解AGI,而不是作为一个单一的端点(根据原则6),可以帮助确保政策制定者在近期和实现AGI的道路上识别和优先考虑风险。 |
Levels of AGI as a Framework for Risk Assessment—AGI级别作为风险评估框架
随着水平向ASI提升,会引入利用风险、对齐风险与结构风险,Expert AGI水平可能面临经济影响与就业替代风险+Virtuoso AGI与ASI水平易产生超级风险(如模型误导人类实现误指定目标)
| As we advance along our capability levels toward ASI, new risks are introduced, including misuse risks, alignment risks, and structural risks (Zwetsloot and Dafoe, 2019). For example, the “Expert AGI” level is likely to involve structural risks related to economic disruption and job displacement, as more and more industries reach the substitution threshold for machine intelligence in lieu of human labor. On the other hand, reaching “Expert AGI” likely alleviates some risks introduced by “Emerging AGI” and “Competent AGI,” such as the risk of incorrect task execution. The “Virtuoso AGI” and “ASI” levels are where many concerns relating to x-risk are most likely to emerge (e.g., an AI that can outperform its human operators on a broad range of tasks might deceive them to achieve a mis-specified goal, as in misalignment thought experiments (Christian, 2020)). | AGI级别作为风险评估框架 当我们沿着我们的能力水平向ASI推进时,引入了新的风险,包括滥用风险、对齐风险和结构风险(Zwetsloot和Dafoe, 2019)。例如,随着越来越多的行业达到机器智能取代人类劳动的替代阈值,“Expert AGI”级别可能涉及与经济中断和工作岗位取代相关的结构性风险。另一方面,达到“Expert AGI”可能会减轻“Emerging AGI”和“Competent AGI”带来的一些风险,例如错误执行任务的风险。“Virtuoso AGI”和“ASI”级别是最有可能出现与x风险相关的许多问题的地方(例如,在错位思想实验中,在广泛的任务中表现优于人类操作员的AI可能会欺骗他们实现错误的目标(Christian, 2020))。 |
若进度超过监管,不同国家获得ASI可能带来地缘政治风险+标准测试是否包含危险能力存在争议
| Systemic risks such as destabilization of international relations may be a concern if the rate of progression between levels outpaces regulation or diplomacy (e.g., the first nation to achieve ASI may have a substantial geopolitical/military advantage, creating complex structural risks). At levels below “Expert AGI” (e.g., “Emerging AGI,” “Competent AGI,” and all “Narrow” AI categories), risks likely stem more from human actions (e.g., risks of AI misuse, whether accidental, incidental, or malicious). A more complete analysis of risk profiles associated with each level is a critical step toward developing a taxonomy of AGI that can guide safety/ethics research and policymaking. We acknowledge that whether an AGI benchmark should include tests for potentially dangerous capabilities (e.g., the ability to deceive, to persuade (Veerabadran et al., 2023), or to perform advanced biochemistry (Morris, 2023)) is controversial. We lean on the side of including such capabilities in benchmarking, since most such skills tend to be dual use (having valid applications to socially positive scenarios as well as nefarious ones). Dangerous capability benchmarking can be de-risked via Principle 4 (Potential, not Deployment) by ensuring benchmarks for any dangerous or dual-use tasks are appropriately sandboxed and not defined in terms of deployment. However, including such tests in a public benchmark may allow malicious actors to optimize for these abilities; understanding how to mitigate risks associated with benchmarking dual-use abilities remains an important area for research by AI safety, AI ethics, and AI governance experts. | 如果水平之间的进展速度超过了监管或外交的速度(例如,第一个实现ASI的国家可能具有实质性的地缘政治/军事优势,从而产生复杂的结构性风险),那么诸如国际关系不稳定之类的系统性风险可能是一个问题。在“Expert AGI”(例如,“Emerging AGI”,“Competent AGI”和所有“狭义”人工智能类别)以下的级别,风险可能更多地源于人类行为(例如,AI误用的风险,无论是意外、偶然还是恶意)。对与每个级别相关的风险概况进行更完整的分析是制定AGI分类的关键一步,可以指导安全/伦理研究和政策制定。 我们承认,AGI基准是否应该包括对潜在危险能力(例如,欺骗能力、说服能力(Veerabadran et al., 2023)或执行高级生物化学(Morris, 2023))的测试是有争议的。我们倾向于将这些能力包括在基准测试中,因为大多数此类技能往往具有双重用途(对社会积极的场景和邪恶的场景都有有效的应用)。危险能力基准测试可以通过原则4(潜在的,而不是部署的)来降低风险,方法是确保任何危险任务或两用任务的基准测试都被适当地沙盒化(适当的环境下进行),而不是根据部署来定义。但是,在公共基准测试中包含此类测试可能使恶意行为者优化这些能力;了解如何降低与对军民两用能力进行基准测试相关的风险,仍然是AI安全、AI伦理和AI治理专家研究的重要领域。 |
风险分析要归入AGI分类体系指导安全研究与政策
| Concurrent with this work, Anthropic released Version 1.0 of its Responsible Scaling Policy (RSP) (Anthropic, 2023b). This policy uses a levels-based approach (inspired by biosafety level standards) to define the level of risk associated with an AI system, identifying what dangerous capabilities may be associated with each AI Safety Level (ASL), and what containment or deployment measures should be taken at each level. Current SOTA generative AIs are classified as an ASL-2 risk. Including items matched to ASL capabilities in any AGI benchmark would connect points in our AGI taxonomy to specific risks and mitigations. | 与此同时,Anthropic发布了1.0版本的负责任扩展政策(RSP) (Anthropic, 2023b)。该政策采用基于级别的方法(受生物安全级别标准的启发)来定义与AI系统相关的风险级别,确定可能与每个AI安全级别(ASL)相关的危险能力,以及应在每个级别采取哪些遏制或部署措施。目前最先进的生成AI被归类为ASL-2风险。在任何AGI基准中包括与ASL功能匹配的项目,将我们的AGI分类法与特定风险和缓解措施联系起来。 |
Capabilities vs. Autonomy——能力vs.自主性:从系统运行背景出发,阐述AGI水平与人机交互水平如何相互匹配,并强调环境因素在交互设计中的重要性
提出六个人机交互自主水平,与AGI水平相匹配但存在选择空间
| While capabilities provide prerequisites for AI risks, AI systems (including AGI systems) do not and will not operate in a vacuum. Rather, AI systems are deployed with particular interfaces and used to achieve particular tasks in specific scenarios. These contextual attributes (interface, task, scenario, end-user) have substantial bearing on risk profiles. AGI capabilities alone do not determine destiny with regards to risk, but must be considered in combination with contextual details. Consider, for instance, the affordances of user interfaces for AGI systems. Increasing capabilities unlock new interaction paradigms, but do not determine them. Rather, system designers and end- users will settle on a mode of human-AI interaction (Morris et al., 2023) that balances a variety of considerations, including safety. We propose characterizing human-AI interaction paradigms with six Levels of Autonomy, described in Table 2. These Levels of Autonomy are correlated with the Levels of AGI. Higher levels of autonomy are “unlocked” by AGI capability progression, though lower levels of autonomy may be desirable for particular tasks and contexts (including for safety reasons) even as we reach higher levels of AGI. Carefully considered choices around human-AI interaction are vital to safe and responsible deployment of frontier AI models. | 尽管能力为AI风险提供了先决条件,但AI系统(包括AGI系统)现在和将来,并不会在真空中运作。相反,AI系统部署了特定的接口,用于在特定场景中完成特定的任务。这些上下文属性(界面、任务、场景、最终用户)对风险概况有很大的影响。AGI能力本身并不能决定与风险相关的命运,但必须结合上下文细节来考虑。 例如,考虑一下AGI系统的用户界面的功能。不断增加的功能开启了新的交互范例,但并不能决定它们。相反,系统设计师和最终用户将选择一种人类与人工智能交互的模式(Morris et al., 2023),平衡各种考虑因素,包括安全性。我们建议用六个自治级别来描述人类-AI交互范式,如表2所示。 这些自治水平与AGI水平相关。更高级别的自治是随着AGI能力的进步“解锁”的,尽管在我们达到更高级别的AGI时,对于特定的任务和上下文(包括出于安全原因)较低层次的自主性(包括出于安全原因)可能仍然具有吸引力。仔谨慎考虑人类AI交互方式对于确保前沿AI模型安全、负责任地部署至关重要。 |
“No AI”模式在教育、乐趣、评估、安全场景下有应用。
| We emphasize the importance of the “No AI” paradigm. There may be many situations where this is desirable, including for education, enjoyment, assessment, or safety reasons. For example, in the domain of self-driving vehicles, when Level 5 Self-Driving technology is widely available, there may be reasons for using a Level 0 (No Automation) vehicle. These include for instructing a new driver (education), for pleasure by driving enthusiasts (enjoyment), for driver’s licensing exams (assessment), or in conditions where sensors cannot be relied upon such as technology failures or extreme weather events (safety). While Level 5 Self-Driving (SAE International, 2021) vehicles would likely be a Level 5 Narrow AI (“Superhuman Narrow AI”) under our taxonomy6, the same considerations regarding human vs. computer autonomy apply to AGIs. We may develop an AGI, but choose not to deploy it autonomously (or choose to deploy it with differentiated autonomy levels in distinct circumstances as dictated by contextual considerations). | 我们强调“No AI”范式的重要性。在许多情况下,这可能是可取的,包括教育、娱乐、评估或安全原因。例如,在自动驾驶汽车领域,当Level 5自动驾驶技术广泛应用时,可能会有理由使用Level 0(无自动化)车辆。这些包括指导新驾驶员(教育),让驾驶爱好者的乐趣(享受),驾驶执照考试(评估),或在技术故障或极端天气事件等传感器无法依赖的情况下(安全)。虽然Level 5自动驾驶汽车(SAE International, 2021年)在我们的分类下可能是Level 5狭义人工智能(“Superhuman Narrow AI”),但人类与计算机自主的考虑同样适用于AGI。我们可以开发AGI,但选择不自主地部署它(或者根据上下文考虑,选择在不同的环境中以不同的自治级别部署它)。 |
高自主模式可能需要系统具备学习请求帮助等元认知能力
| Certain aspects of generality may be required to make particular interaction paradigms desirable. For example, the Autonomy Levels 3, 4, and 5 ("Collaborator," "Expert," and "Agent") may only work well if an AI system also demonstrates strong performance on certain metacognitive abilities (learning when to ask a human for help, theory of mind modeling, social-emotional skills). Implicit in our definition of Autonomy Level 5 ("AI as an Agent") is that such a fully autonomous AI can act in an aligned fashion without continuous human oversight, but knows when to consult humans (Shah et al., 2021). Interfaces that support human-AI alignment through better task specification, the bridging of process gulfs, and evaluation of outputs (Terry et al., 2023) are a vital area of research for ensuring that the field of human-computer interaction keeps pace with the challenges and opportunities of interacting with AGI systems. | 为了使特定的交互范式具有吸引力,可能需要某些通用性方面。例如,自主性Levels 3、4和5(“合作者”、“专家”和“代理”)可能只有在人工智能系统在某些元认知能力(学习何时向人类寻求帮助、心智理论建模、社交情感技能)上表现出色时才会发挥作用。我们对自治级别Level 5(“AI作为代理”)暗示,这种完全自主的AI可以在没有持续的人类监督下采取一致的行动,但知道何时咨询人类(Shah等,2021)。通过更好的任务规范、弥合过程鸿沟和评估输出(Terry et al., 2023)来支持人机对齐的接口是一个重要的研究领域,可以确保人机交互领域跟上与AGI系统交互的挑战和机遇。 |
Table 2 | More capable AI systems unlock new human-AI interaction paradigms 表2 | 更强大的AI系统解锁新的人机交互范式
| Table 2 | More capable AI systems unlock new human-AI interaction paradigms (including fully autonomous AI). The choice of appropriate autonomy level need not be the maximum achievable given the capabilities of the underlying model. One consideration in the choice of autonomy level are resulting risks. This table’s examples illustrate the importance of carefully considering human-AI interaction design decisions. | 表2 |更强大的AI系统开启了新的人机交互范式(包括完全自主的AI)。选择合适的自主级别不必是底层模型所能达到的最高级别。选择自主级别的考虑因素之一是产生的风险。表2的示例说明了仔细考虑人机交互设计决策的重要性。 |
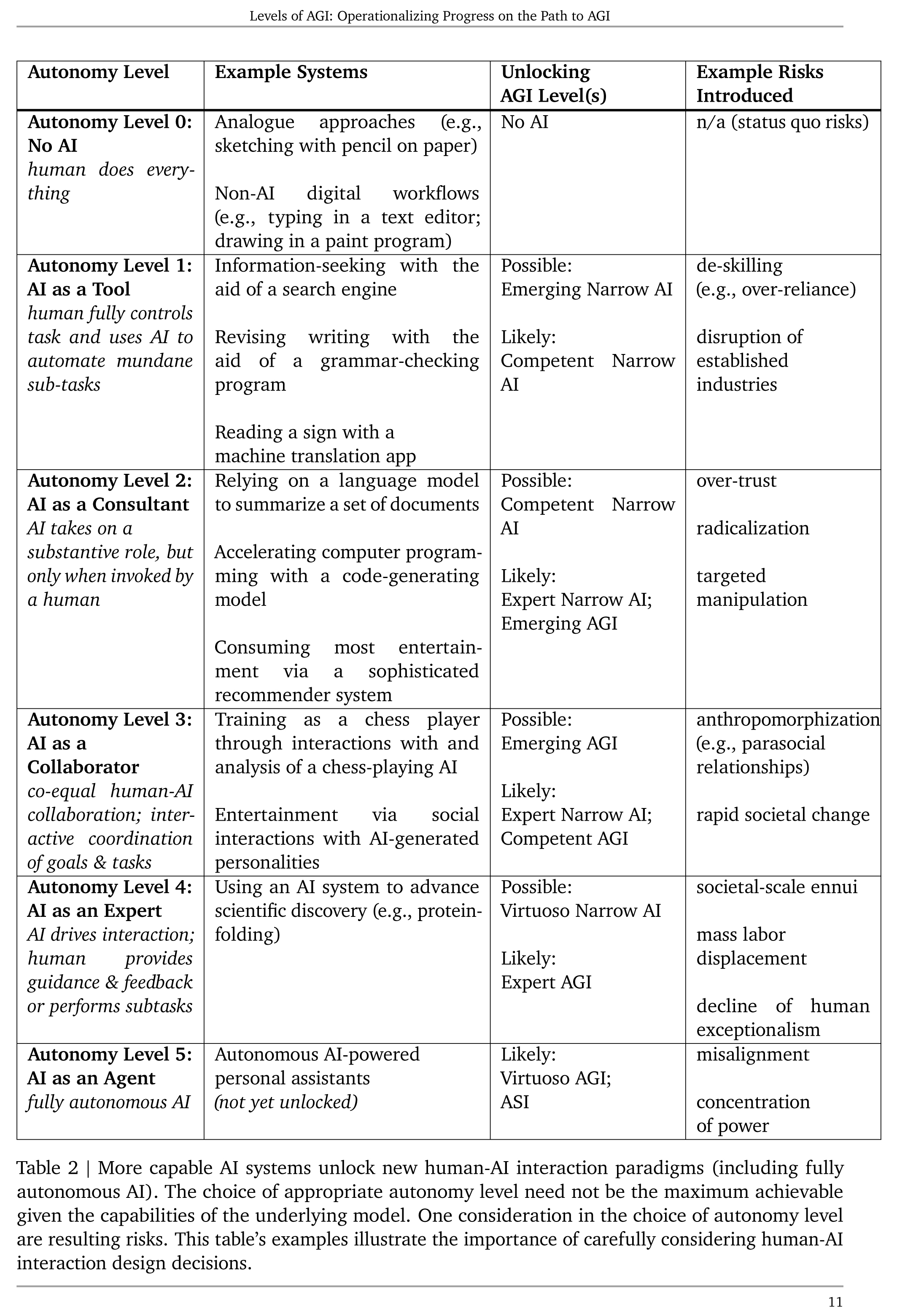
人机交互中的自主级别—人机交互决策设计的重要性:No AI→作为工具(搜索信息/机器翻译)→作为顾问(文本摘要/代码生成/复杂推荐)→作为合作者(象棋博弈/与AI生成互动)→作为专家(科学发现-蛋白质折叠)→作为代理(AI驱动的个人助手)
| Autonomy Level 自主级别 | Example Systems 示例系统 | Unlocking AGI Level(s) 解锁通用人工智能级别 | Example Risks Introduced 引入的风险示例 |
| Autonomy Level 0: No AI human does everything 无人工智能 人类完成所有任务 | Analogue approaches (e.g., sketching with pencil on paper) Non-AI digital workflows(e.g., typing in a text editor;drawing in a paint program) 模拟方法(例如,在纸上用铅笔素描); 非人工智能数字工作流程(例如,在文本编辑器中打字;在绘图程序中绘图); | No AI 无人工智能 | n/a (status quo risks) 无(现状风险) |
| Autonomy Level 1: AI as a Tool human fully controls task and uses AI to automate mundane sub-tasks 人工智能作为工具; 人类完全控制任务并使用人工智能自动化琐碎子任务; | Information-seeking with the aid of a search engine Revising writing with the aid of a grammar-checking program Reading a sign with a machine translation app 利用搜索引擎进行信息检索; 在语法检查程序的帮助下修改写作; 利用机器翻译应用阅读标志; | Possible: Emerging Narrow AI Likely: Competent Narrow AI | de-skilling (e.g., over-reliance) disruption of established industries 技能丧失(例如,过度依赖)、打破已建立的行业 |
| Autonomy Level 2: AI as a Consultant AI takes on a substantive role, but only when invoked by a human 人工智能作为顾问; 人工智能承担实质性角色,但仅在被人类调用时; | Relying on a language model to summarize a set of documents Accelerating computer programming with a code-generating model Consuming most entertainment via a sophisticated recommender system 依赖语言模型总结一组文件; 利用代码生成模型加速计算机编程; 通过复杂的推荐系统消费大多数娱乐内容; | Possible: Competent Narrow AI Likely: Expert Narrow AI; Emerging AGI | over-trust radicalization targeted manipulation 过度信任、极端化、针对性操纵 |
| Autonomy Level 3: AI as a Collaborator co-equal human-AI collaboration; interactive coordination of goals & tasks 人工智能作为合作者; 人工智能与人类平等协作;目标和任务的互动协调; | Training as a chess player through interactions with and analysis of a chess-playing AI Entertainment via social interactions with AI-generated personalities 通过与国际象棋对弈人工智能的互动和分析培训国际象棋玩家; 通过与由人工智能生成的个性互动进行娱乐; | Possible: Emerging AGI Likely: Expert Narrow AI; Competent AGI | anthropomorphization (e.g., parasocial relationships) rapid societal change 拟人化(例如,社交关系中的偏执)、快速社会变革 |
| Autonomy Level 4: AI as an Expert AI drives interaction;human provides guidance & feedback or performs subtasks 人工智能作为专家; 人工智能主导互动;人类提供指导和反馈或执行子任务 | Using an AI system to advance scientific discovery (e.g., proteinfolding) 利用人工智能系统推动科学发现(例如,蛋白质折叠) | Possible: Virtuoso Narrow AI Likely: Expert AGI | societal-scale ennui mass labor displacement decline of human exceptionalism 社会规模的倦怠、大规模劳动力置换、人类例外主义的衰落 |
| Autonomy Level 5: AI as an Agent fully autonomous AI 人工智能作为代理; 完全自主的人工智能 | Autonomous AI-powered personal assistants (not yet unlocked) 自主的、由人工智能驱动的个人助手(尚未解锁) | Likely: Virtuoso AGI; ASI | misalignment concentration of power 不一致、权力集中 |
Human-AI Interaction Paradigm as a Framework for Risk Assessment人机交互范式作为风险评估框架:探讨了AGI水平与人机交互水平如何相互影响,并重点分析其在风险管理中的重要性。
AGI水平和人机交互水平共同决定不同交互模式解锁,从而影响风险评估。
| Table 2 illustrates the interplay between AGI Level, Autonomy Level, and risk. Advances in model performance and generality unlock additional interaction paradigm choices (including potentially fully autonomous AI). These interaction paradigms in turn introduce new classes of risk. The interplay of model capabilities and interaction design will enable more nuanced risk assessments and responsible deployment decisions than considering model capabilities alone. | 作为风险评估框架的人机交互范式 表2说明了AGI级别、自治级别和风险之间的相互作用。模型性能和通用性的进步开启了额外的交互范式选择(包括潜在的完全自主的AI)。这些交互范例反过来又引入了新的风险类别。与单独考虑模型功能相比,模型功能和交互设计的相互作用将支持更细致的风险评估和负责任的部署决策。 |
表二给出六个人机交互水平例子并匹配其AGI触发水平
| Table 2 also provides concrete examples of each of our six proposed Levels of Autonomy. For each level of autonomy, we indicate the corresponding levels of performance and generality that "unlock" that interaction paradigm (i.e., levels of AGI at which it is possible or likely for that paradigm to be successfully deployed and adopted). | 表2还提供了我们提出的六个自治级别中的每个级别的具体示例。对于每个自治级别,我们指出相应的性能级别和“解锁”交互范式的通用性(即,可能或可能成功部署和采用该范式的AGI级别)。 |
一般AI系统能力发展不均衡,可能提前解锁某任务范围更高交互水平
| Our predictions regarding "unlocking" levels tend to require higher levels of performance for Narrow than for General AI systems; for instance, we posit that the use of AI as a Consultant is likely with either an Expert Narrow AI or an Emerging AGI. This discrepancy reflects the fact that for General systems, capability development is likely to be uneven; for example, a Level 1 General AI ("Emerging AGI") is likely to have Level 2 or perhaps even Level 3 performance across some subset of tasks. Such unevenness of capability for General AIs may unlock higher autonomy levels for particular tasks that are aligned with their specific strengths. | 我们关于“解锁”级别的预测往往要求狭窄AI的性能水平高于通用AI系统;例如,我们假设使用人工智能作为顾问可能是 Expert Narrow AI或Emerging AGI。这种差异反映了这样一个事实,即对于通用系统,能力发展可能是不平衡的;例如,1级通用AI(“Emerging AGI”)在某些任务子集上可能具有2级甚至3级的性能。这种通用AI能力的不平衡可能导致特定任务的自主级别更高,与它们的特定优势保持一致。 |
综合考虑模型能力和交互设计,可以进行更细致的风险评估和负责任部署决策
| Considering AGI systems in the context of use by people allows us to reflect on the interplay between advances in models and advances in human-AI interaction paradigms. The role of model building research can be seen as helping systems’ capabilities progress along the path to AGI in their performance and generality, such that an AI system’s abilities will overlap an increasingly large portion of human abilities. Conversely, the role of human-AI interaction research can be viewed as ensuring new AI systems are usable by and useful to people such that AI systems successfully extend people’s capabilities (i.e., "intelligence augmentation" (Brynjolfsson, 2022)). | 在人类使用的背景下考虑AGI系统,可以让我们反思模型的进步和人类-AI交互范式的进步之间的相互作用。模型构建研究的作用可以被看作是帮助系统的能力在性能和通用性方面沿着通往AGI的道路前进,使得AI系统的能力将与人类能力的越来越多部分重叠。相反,人类与人工智能交互研究的作用可以被视为确保新的AI系统对人们可用和有益,这样AI系统就能成功地扩展人们的能力(即“智能增强”(Brynjolfsson, 2022))。 |
Conclusion结论:阐述了对AGI概念和进度判断的原则式思考,以及其在安全研究中的应用价值。
| Artificial General Intelligence (AGI) is a concept of both aspirational and practical consequences. In this paper, we analyzed nine prominent definitions of AGI, identifying strengths and weaknesses. Based on this analysis, we introduce six principles we believe are necessary for a clear, operationalizable definition of AGI: focusing on capabilities, not processes; focusing on generality and performance; focusing on cognitive and metacognitive (rather than physical) tasks; focusing on potential rather than deployment; focusing on ecological validity for benchmarking tasks; and focusing on the path toward AGI rather than a single endpoint. With these principles in mind, we introduced our Levels of AGI ontology, which offers a more nuanced way to define our progress toward AGI by considering generality (either Narrow or General) in tandem with five levels of performance (Emerging, Competent, Expert, Virtuoso, and Superhuman). We reflected on how current AI systems and AGI definitions fit into this framing. Further, we discussed the implications of our principles for developing a living, ecologically valid AGI benchmark, and argue that such an endeavor (while sure to be challenging) is a vital one for our community to engage with. | 通用人工智能(AGI)是一个既有理想又有实际意义的概念。在本文中,我们分析了九个著名的AGI定义,确定了其优势和劣势。基于这一分析,我们介绍了我们认为明确、可操作的AGI定义所必需的六个原则:关注能力,而不是过程;注重通用性和性能;专注于认知和元认知(而不是物理)任务;关注潜力而不是部署;关注基准任务的生态效度;专注于通往AGI的道路,而不是单一的终点。 考虑到这些原则,我们引入了AGI本体的水平,它提供了一种更细致的方式来定义我们在AGI方面的进展,通过考虑通用性(狭窄或一般)与五个性能水平(Emerging, Competent, Expert, Virtuoso, 和Superhuman)相结合。我们反思了当前的AI系统和AGI定义如何适应这一框架。此外,我们讨论了我们的原则对开发一个生活的、生态有效的AGI基准的影响,并认为这样的努力(虽然肯定是具有挑战性的)对我们的社区来说是至关重要的。 |
| Finally, we considered how our principles and ontology can reshape discussions around the risks associated with AGI. Notably, we observed that AGI is not necessarily synonymous with autonomy. We introduced Levels of Autonomy that are unlocked, but not determined by, progression through the Levels of AGI. We illustrated how considering AGI Level jointly with Autonomy Level can provide more nuanced insights into likely risks associated with AI systems, underscoring the importance of investing in human-AI interaction research in tandem with model improvements. | 最后,我们考虑了我们的原则和本体如何重塑围绕AGI相关风险的讨论。值得注意的是,我们观察到AGI不一定是自治的同义词。我们引入了可解锁的自治级别,但不受AGI级别的进展所决定。我们说明了将AGI Level与Autonomy Level联合考虑可以如何提供与人工智能系统相关的更细致入微的风险洞察,强调在人机交互研究方面与模型改进同步投资的重要性。 |
Acknowledgements致谢
| Thank you to the members of the Google DeepMind PAGI team for their support of this effort, and to Martin Wattenberg, Michael Terry, Geoffrey Irving, Murray Shanahan, Dileep George, and Blaise Agüera y Arcas for helpful discussions about this topic. | 感谢Google DeepMind PAGI团队成员对这一努力的支持,感谢Martin Wattenberg、Michael Terry、Geoffrey Irving、Murray Shanahan、Dileep George和Blaise agera y Arcas对这一主题的有益讨论。 |



















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











