







LLMs之Bench:LiveBench的简介、安装和使用方法、案例应用之详细攻略
导读:2024年6月12日,LiveBench提出了一种创新的基准测试方法,旨在解决LLM基准测试中的关键问题,特别是测试集污染和评估偏差。通过定期更新的问题集和客观的自动化评分方法,LiveBench不仅提供了一个公平、准确的评估平台,还推动了LLM的持续改进和社区参与。
背景痛点:现代大型语言模型(LLM)在评估中常遇到两个主要问题:首先是测试集污染,模型在训练中可能见过测试问题,导致其表现被高估;其次是评估过程中的偏差,无论是使用LLM评判还是人工评判,都存在主观偏见、错误和一致性低的问题,特别是在处理复杂的数学和推理任务时,这使得评估结果难以真实反映模型的实际能力。
解决方案:LiveBench提出了一种创新的基准测试方法,旨在解决上述问题:
>> 月度更新和新数据源:为了避免测试集污染,LiveBench每月发布新的问题,这些问题基于最新的数据集、arXiv论文、新闻文章和IMDb电影梗概。这确保了问题的新颖性,使得模型无法通过训练数据中见过类似问题而获益。
>> 客观的地面真实评判:每个问题都有可验证的、客观的真实答案,允许使用自动化的方式精确评分,而无需依赖LLM或人工评判。这种方法避免了评估过程中可能引入的偏差和错误。
>> 多样的任务集合:初始的LiveBench包含18个任务,涵盖6大类:推理、数据分析、数学、编程、语言理解和指令执行。通过不断引入更困难的任务,LiveBench旨在逐步区分模型的能力。
优势:LiveBench相较于传统基准测试有显著优势:它通过持续引入新问题有效避免了测试集污染,并使用客观真实答案进行自动化评分,确保了评估的公平性和准确性;涵盖多种任务类型,可以全面测试模型的多种能力;同时,通过开放共享问题和代码,鼓励社区参与和协作,推动LLM领域的持续创新和进步。
>> 避免测试集污染:通过月度更新和新颖的数据来源,LiveBench有效避免了传统基准测试中因见过类似问题而导致的表现高估。
>> 客观与公正的评估:使用地面真实答案进行自动化评分,减少了人工和LLM评判中的偏差和错误,提高了评估的公平性和准确性。
>> 覆盖广泛的任务类别:LiveBench包含多种任务类型,能够全面测试LLM的不同能力,确保模型在各个方面的性能得到合理评估。
>> 开放与协作:所有问题、代码和模型答案均开放共享,鼓励社区参与和合作,推动基准测试任务和模型的不断扩展和改进。
目录
LiveBench的简介
2024年6月12日,LiveBench团队发布LiveBench基准,这是一个为LLMs设计的基准,考虑了测试集污染和客观评估。
LiveBench具有以下特点:
>> 为了限制潜在的污染,LiveBench每月发布新的问题,并基于最近发布的数据集、arXiv论文、新闻文章和IMDb电影简介提出问题。
>> 每个问题都有可验证的、客观的真实答案,允许难题被准确且自动地评分,而无需使用LLM裁判。
>> LiveBench目前包含18个多样化的任务,分为6个类别,并且我们将随着时间的推移发布新的、更难的任务。
官网:LiveBench
博客地址:LiveBench
1、Leaderboard
| Model | Global Average | Reasoning Average | Coding Average | Mathematics Average | Data Analysis Average | Language Average | IF Average |
|---|---|---|---|---|---|---|---|
| gpt-4o-2024-05-13 | 53.79 | 48.00 | 46.37 | 49.88 | 52.41 | 53.94 | 72.17 |
| gpt-4-turbo-2024-04-09 | 53.34 | 56.00 | 47.05 | 48.99 | 51.32 | 45.26 | 71.39 |
| claude-3-opus-20240229 | 51.92 | 48.00 | 40.05 | 46.54 | 54.32 | 51.72 | 70.87 |
| gpt-4-1106-preview | 50.61 | 42.67 | 44.37 | 47.55 | 51.33 | 48.37 | 69.39 |
| gpt-4-0125-preview | 48.17 | 40.67 | 44.05 | 42.75 | 54.06 | 43.55 | 63.92 |
| gemini-1.5-pro-latest | 43.52 | 28.00 | 32.79 | 42.07 | 52.81 | 38.25 | 67.20 |
| mistral-large-2402 | 39.97 | 38.67 | 29.47 | 32.20 | 42.55 | 28.74 | 68.19 |
| claude-3-sonnet-20240229 | 39.31 | 33.33 | 25.21 | 29.65 | 44.56 | 38.08 | 65.00 |
| qwen2-72b-instruct | 38.49 | 32.00 | 31.79 | 43.44 | 26.24 | 29.21 | 68.27 |
| claude-3-haiku-20240307 | 36.09 | 30.67 | 24.53 | 25.72 | 41.54 | 30.07 | 64.03 |
| meta-llama-3-70b-instruct | 35.99 | 22.67 | 20.95 | 32.31 | 42.41 | 34.11 | 63.50 |
| mixtral-8x22b-instruct-v0.1 | 35.00 | 30.00 | 33.11 | 26.94 | 30.33 | 26.48 | 63.17 |
| gpt-3.5-turbo-0125 | 34.77 | 28.00 | 29.16 | 25.54 | 41.21 | 24.22 | 60.47 |
| gpt-3.5-turbo-1106 | 34.19 | 28.67 | 26.84 | 27.78 | 41.70 | 28.63 | 51.53 |
| command-r-plus | 33.19 | 34.00 | 20.26 | 24.85 | 24.60 | 23.92 | 71.51 |
| mistral-small-2402 | 32.69 | 27.33 | 24.21 | 26.76 | 31.88 | 22.06 | 63.91 |
| qwen1.5-72b-chat | 29.61 | 25.33 | 22.89 | 26.82 | 32.98 | 11.37 | 58.25 |
| qwen1.5-110b-chat | 28.73 | 24.67 | 22.21 | 25.58 | 31.45 | 13.22 | 55.26 |
| command-r | 26.67 | 24.67 | 14.95 | 16.92 | 31.69 | 14.64 | 57.16 |
| meta-llama-3-8b-instruct | 25.73 | 19.33 | 18.26 | 17.58 | 23.33 | 18.72 | 57.14 |
| mixtral-8x7b-instruct-v0.1 | 23.39 | 23.33 | 11.32 | 18.97 | 28.13 | 13.76 | 44.81 |
| phi-3-mini-128k-instruct | 20.60 | 25.33 | 11.63 | 21.48 | 8.69 | 6.80 | 49.65 |
| phi-3-mini-4k-instruct | 19.89 | 22.67 | 14.95 | 19.88 | 14.67 | 7.10 | 40.05 |
| mistral-7b-instruct-v0.2 | 19.83 | 16.00 | 11.63 | 16.04 | 14.62 | 9.05 | 51.65 |
| zephyr-7b-alpha | 19.05 | 16.00 | 11.32 | 9.61 | 17.40 | 7.20 | 52.79 |
| starling-lm-7b-beta | 17.72 | 26.67 | 18.26 | 13.82 | 2.00 | 7.26 | 38.32 |
| zephyr-7b-beta | 17.43 | 16.67 | 8.32 | 11.23 | 15.75 | 4.28 | 48.32 |
| qwen1.5-7b-chat | 16.89 | 15.33 | 6.63 | 12.86 | 16.23 | 6.18 | 44.12 |
| vicuna-7b-v1.5-16k | 12.98 | 10.67 | 1.32 | 6.61 | 9.27 | 7.92 | 42.12 |
| vicuna-7b-v1.5 | 11.18 | 8.67 | 1.00 | 4.33 | 2.67 | 8.66 | 41.75 |
| qwen1.5-4b-chat | 10.68 | 10.67 | 4.00 | 6.73 | 9.13 | 5.80 | 27.75 |
| llama-2-7b-chat-hf | 9.98 | 3.33 | 0.00 | 4.78 | 0.00 | 6.86 | 44.88 |
| yi-6b-chat | 8.35 | 5.33 | 1.32 | 7.14 | 4.38 | 4.69 | 27.22 |
| qwen1.5-1.8b-chat | 5.81 | 3.33 | 0.00 | 2.14 | 3.33 | 3.16 | 22.90 |
| qwen1.5-0.5b-chat | 5.04 | 2.67 | 0.00 | 3.39 | 0.00 | 2.88 | 21.30 |
2、2024年6月12日发布LiveBench
原文地址:LiveBench
LiveBench是一个具有挑战性且无污染的大型语言模型基准测试。一个专为大型语言模型(LLM)设计的基准测试,考虑了测试集污染和客观评估
LiveBench具有以下特点:
>> LiveBench旨在通过每月发布新问题以及基于最近发布的数据集、arXiv论文、新闻文章和IMDb电影简介的问题来限制潜在的污染。
>> 每个问题都有可验证的、客观的真实答案,允许对难题进行准确和自动评分,无需使用LLM评审。
>> LiveBench目前包含6个类别中的18项多样化任务,并且我们将随着时间推移发布新的、更难的任务。
今天,我们发布了第一批960个问题,并计划每月发布一组问题。通过这种方式,我们旨在使LiveBench免受污染,因为每次发布都会有新的问题。
除了污染之外,LiveBench通过仅包含具有客观答案的问题来避免LLM评审的陷阱。虽然LLM评审和众包的提示与评估有许多好处,但它们也引入了显著的偏见,并且在评审难题答案时完全崩溃。例如,我们在论文中显示,对于具有挑战性的推理和数学问题,GPT-4-Turbo的通过/未通过判断与真实通过/未通过判断的相关性不到60%。
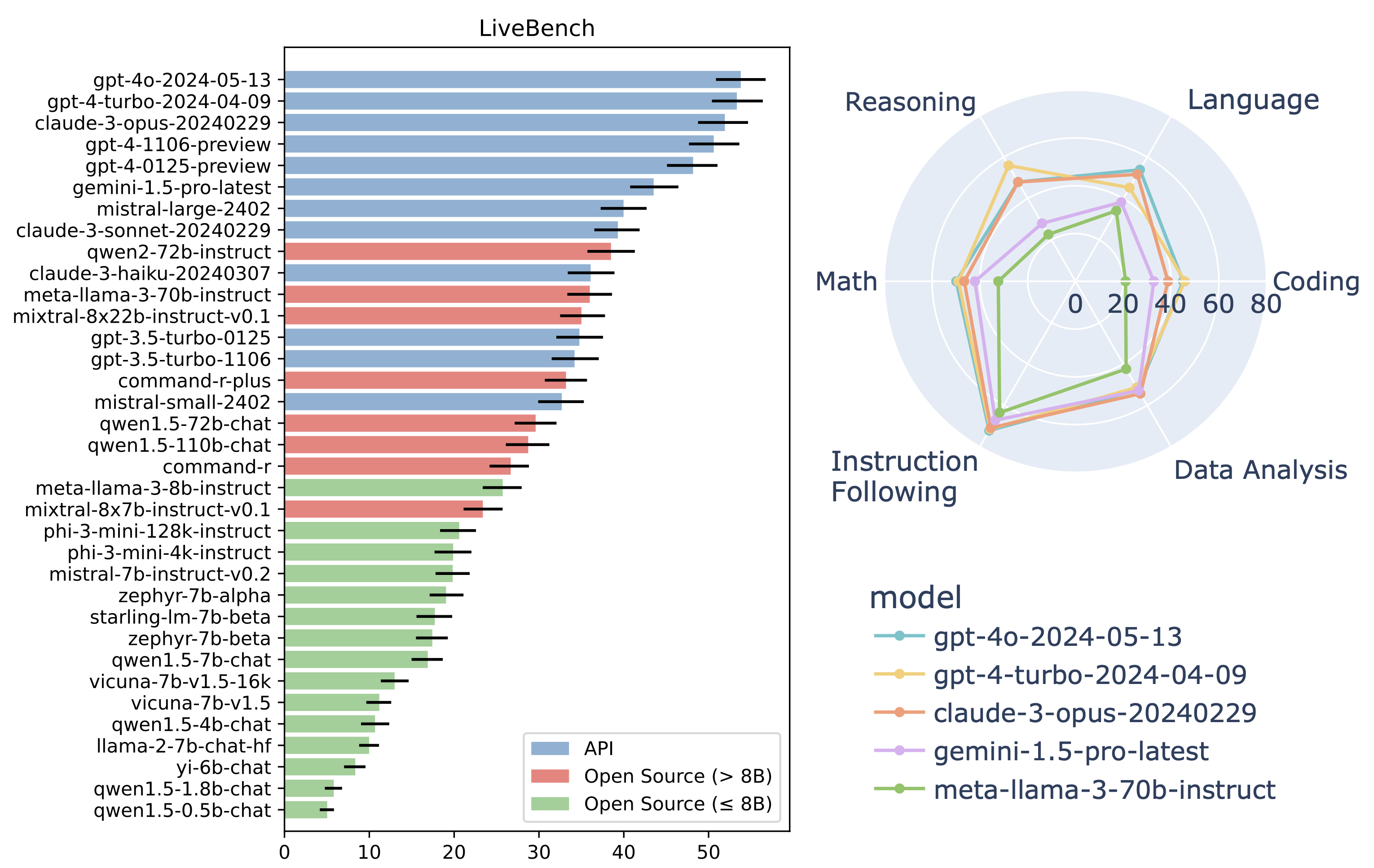
LiveBench目前评估了几种著名的闭源模型和几十种从0.5B到70B不等的开源模型。LiveBench的问题是困难的,例如,GPT-4-Turbo在LiveBench上的总体准确率约为50%。此外,在我们的每月更新中,我们将随着时间的推移发布新的任务和更难的任务版本,以便LiveBench能够区分LLM在未来改进时的能力。
我们发布所有问题、代码和模型答案,欢迎社区参与和合作以扩展基准测试任务和模型。
LiveBench概述
LiveBench目前由6个类别中的18个任务组成:推理、数据分析、数学、编码、语言理解和指令执行。每个任务分为以下两种类型之一:
>> 使用不断更新的信息源进行提问的任务,例如基于最近的Kaggle数据集进行数据分析,或修正最近arXiv摘要中的错别字。
>> 更具挑战性或多样化的现有基准测试任务版本,例如来自AMPS、Big-Bench Hard、IFEval或bAbI的任务
LiveBench包含的类别和任务有:
>> 数学:来自过去12个月的高中数学竞赛(AMC12、AIME、USAMO、IMO、SMC)的问题,以及更难的AMPS问题版本
>> 编码:来自Leetcode和AtCoder(通过LiveCodeBench)的两个任务:代码生成和一个新的代码补全任务
>> 推理:来自Big-Bench Hard的更难版本的Web of Lies,来自bAbI的更难版本的定位推理,以及斑马谜题
>> 语言理解:三个任务,分别是Connections单词谜题、错别字去除任务以及来自最近IMDb和维基百科电影的电影简介解谜任务Zebra Puzzles
>> 指令执行:四个任务,用于根据来自《卫报》的最近新闻文章进行改写、简化、总结或生成故事,需遵循一个或多个指令,例如字数限制或在响应中包含特定元素
>> 数据分析:三个任务,全部使用来自Kaggle和Socrata的最近数据集:表格重新格式化(包括JSON、JSONL、Markdown、CSV、TSV和HTML),预测哪些列可以用于连接两张表,以及预测数据列的正确类型注释
动机
创建LiveBench的目标是确保其问题不易受到污染,并且易于、准确且公平地评估。
许多LLM基准测试很容易被污染,因为现代LLM在其训练数据中包含了大量的互联网内容。这对于LLM评估是个问题,因为如果LLM在训练期间见过基准测试的问题,其在基准测试中的表现将被人为提高或污染。
例如,最近的研究表明,LLM在Codeforces上的表现会在LLM训练数据截止日期之后急剧下降,而在截止日期之前,表现高度与问题在GitHub上出现的次数相关。同样,最近手工制作的经典数学数据集GSM8K的变体显示,几个模型对该基准测试存在过拟合的证据。
还需要确保我们评估LLM答案的方式是公平且无偏见的。在无污染的基准测试中,基准测试主要采用两种方法:LLM作为评审和人类作为评审。
LLM作为评审
LLM作为评审:LLM评审速度快且相对便宜。此外,其最大的优势是能够评审开放式问题、指令跟随问题和聊天机器人。然而,LLM评审也有一些重要的缺点。(1) LLM对自己的答案有偏见。通常只有GPT-4和Claude-3-Opus被用作评审,因为它们是性能最高的LLM。然而,GPT-4和Claude-3-Opus都偏向自己的答案。(2) 它们在其他模型的偏好和差异方面也存在显著差异,甚至在温度为0的情况下,GPT-4在其自身评审中的差异也很明显。(3) 对于有真实答案的问题,LLM评审可能会出错。例如,Arena-Hard中的问题2要求编写一个C++程序来计算给定字符串是否可以通过交换两个字母转换为'abc'。GPT-4错误地判断自己的解决方案为不正确。我们在下面提供了更多这种现象的证据。
人类作为评审
人类作为评审:虽然人类评估对于捕捉群众偏好非常有用,但使用人类作为评审也有许多缺点:(1) 人类评审相当费力,尤其是对于某些类型的问题,例如复杂的数学积分、编码问题或长上下文推理问题。(2) 对于这些类型的问题,人类也常常会犯错误。(3) 不同人类之间的评审结果也会有很大的差异。最后,(4) 人类也会根据正确性以外的指标进行评估——例如,他们可能偏好特定长度、特定格式和正式程度的输出。
与这些方法相比,LiveBench采用客观的真实答案评估每个问题。
客观的真实答案评估
客观的真实答案评估将LLM的输出与预定的真实答案进行比较。这种方法非常好,因为它在时间和成本方面很容易评分。此外,它避免了上述在偏见、错误和评审差异方面的弱点。一个缺点是某些类型的问题没有真实答案,例如“写一篇夏威夷旅行指南”。然而,虽然这限制了可评估的问题类型,但并不影响评估这种方式能够评估的问题的有效性。
LLM评审在具有挑战性的数学(AMC、AIME、SMC)和推理(斑马谜题)任务上的错误率。评审者是GPT-4-Turbo,它评审GPT-4-Turbo和Claude-3-Opus的模型输出。在所有任务中,错误率惊人地高,表明LLM不是这些任务的可靠评审者。
在这里,我们可以看到,使用客观的真实答案评估在我们的任务中优于LLM评审。在这四个任务中,虽然客观的真实答案评估是完美的,但我们发现LLM评审的错误率远高于合理值,表明LLM评审不适用于具有挑战性的数学和逻辑任务。
与其他基准测试的比较
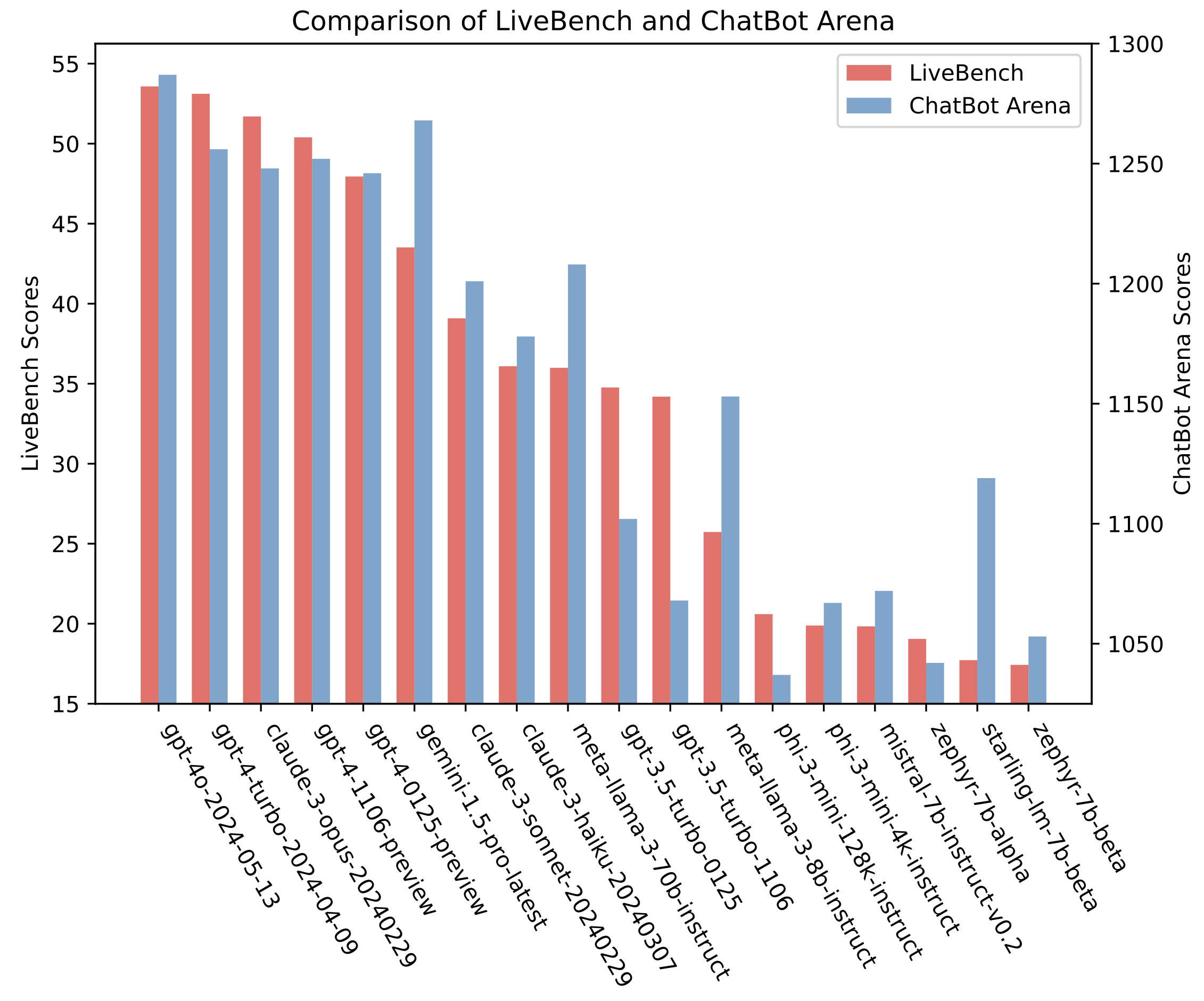
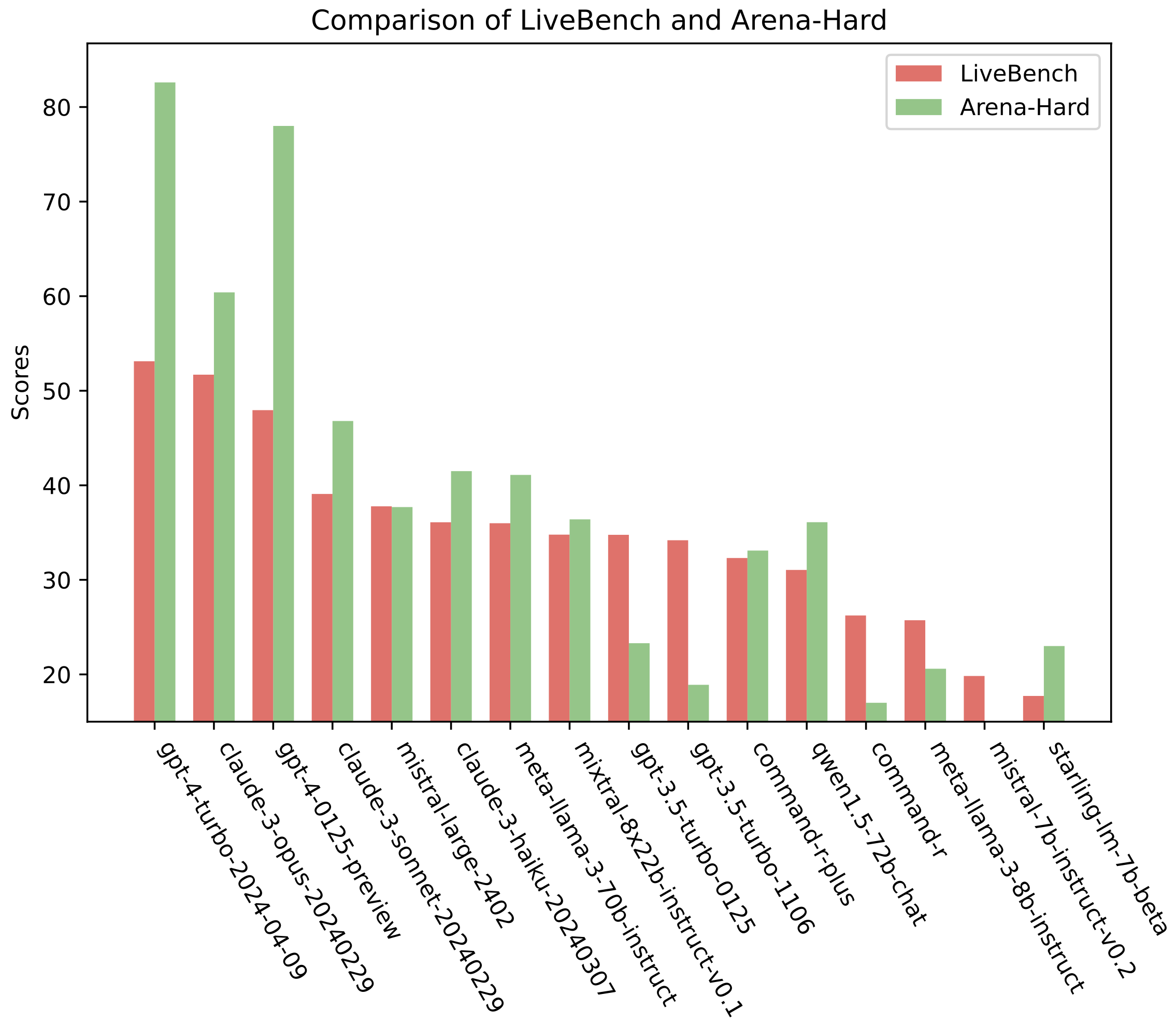
我们将我们的基准测试与当前著名的LLM基准测试:ChatBot Arena和Arena-Hard进行了比较。我们看到,尽管总体趋势类似,但某些模型在一个基准测试上明显强于另一个,这可能表明LLM评审的一些缺点。
比较相同模型在LiveBench和ChatBot Arena上的分数的条形图。
比较相同模型在LiveBench和Arena-Hard上的分数的条形图。令人惊讶的是,GPT-4模型在Arena-Hard上的表现相对LiveBench好得多,这可能是由于使用GPT-4本身作为LLM评审所带来的已知偏见。
我们发现LiveBench与ChatBot Arena之间模型得分的Pearson相关系数为0.90,与Arena-Hard之间为0.89。
根据这些图表和相关系数,我们看到LiveBench通常遵循相似的趋势,但某些模型在一个基准测试上明显强于另一个。例如,gpt-4-0125-preview和gpt-4-turbo-2024-04-09在Arena-Hard上的表现明显优于LiveBench——这可能是由于使用gpt-4本身作为LLM评审所带来的已知偏见。
LiveBench的安装和使用方法
原文地址:https://github.com/livebench/livebench
1、安装
已在Python 3.10上测试通过
cd LiveBench
pip install torch packaging # 这些需要在安装其他依赖项之前安装。
pip install -e .关于fschat的说明:当前pip上的fschat包版本(即lmsys/fastchat)已经过时,因此我们强烈建议在运行上述命令之前卸载fschat,这样它将自动安装fastchat的更新版本。
针对CPU用户的注意事项:如果在仅CPU的机器上安装(例如仅运行api模型),您需要在pyproject.toml的需求列表中手动移除flash-attn。
我们的存储库改编自FastChat出色的llm_judge模块,并包含来自LiveCodeBench和IFEval的代码。
2、使用方法
cd livebench要在LiveBench上生成模型答案,请运行:
python gen_model_answer.py --model-path /path/to/Mistral-7B-Instruct-v0.2/ --model-id Mistral-7B-Instruct-v0.2 --dtype bfloat16 --bench-name live_bench对于基于API的模型,首先设置适当的密钥,然后运行gen_api_answer.py。我们目前支持以下API:OpenAI、Anthropic、Mistral、Cohere和Gemini。要在api_model_name上运行LiveBench的所有内容,请运行以下命令:
export OPENAI_API_KEY=<your_key>
export ANTHROPIC_API_KEY=<your_key>
export MISTRAL_API_KEY=<your_key>
export CO_API_KEY=<your_key>
export GEMINI_API_KEY=<your_key>
python gen_api_answer.py --model <api_model_name> --bench-name live_bench要使用VLLM或其他符合OpenAI API格式的任意API生成模型答案,请运行:
export LIVEBENCH_API_KEY=<your API key if needed. Usually not needed for VLLM>
python gen_api_answer.py --model <api_model_name> --bench-name live_bench --api-base <your endpoint. Often, for VLLM, this is http://localhost:8000/v1>要评分模型输出:
python gen_ground_truth_judgment.py --bench-name live_bench显示所有结果:
python show_livebench_results.py您可能希望仅对某些模型运行这些命令。要为特定模型运行上述任何python文件(gen_model_answer.py、gen_api_answer.py、gen_ground_truth_judgment或show_livebench_results),请使用以下参数样式:
python gen_model_answer.py --bench-name live_bench --model-path /path/to/Mistral-7B-Instruct-v0.2/ --model-id Mistral-7B-Instruct-v0.2 --dtype bfloat16
python gen_api_answer.py --bench-name live_bench --model gpt-4-turbo
python gen_ground_truth_judgment.py --bench-name live_bench --model-list Mistral-7B-Instruct-v0.2 Llama-2-7b-chat-hf claude-3-opus-20240229
python show_livebench_results.py --bench-name live_bench --model-list Mistral-7B-Instruct-v0.2 Llama-2-7b-chat-hf claude-3-opus-20240229或者,您可能希望通过使用--bench-name参数显示LiveBench特定类别或任务的结果。在这里,我们仅对web_of_lies_v2任务运行show_livebench_results.py:
python show_livebench_results.py --bench-name live_bench/reasoning/web_of_lies_v2要选择性地从排行榜上的34个模型下载所有模型答案和判断结果,请使用
python download_leaderboard.py
python show_livebench_results.py # 现在将显示所有模型在排行榜上的结果要选择性地下载question.jsonl文件(用于检查),请使用
python download_questions.py3、数据
每个类别的问题可以在以下位置找到:
还可获取模型答案和模型判断结果。
LiveBench的案例应用
更新中……



















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











