






LLMs之Agent:Coze(字节版的GPTs/偏低代码场景)的简介、安装和使用方法、案例应用之详细攻略
目录
Coze的简介
2024年2月1日正式发布,Coze 是一个 AI 应用开发平台,适用于所有技能水平的用户,可以帮助用户安全、可靠、负责任地开发和部署生成式AI应用。无论是初学者还是有编程经验者,都可以使用 Coze 轻松开发和部署 AI 应用。Coze提供可视化设计和编排工具,支持无代码(no-code)或低代码(low-code)方式快速构建AI项目,利用大型语言模型(LLMs)满足个性化需求,实现商业价值。
1、Coze 的核心功能:智能体+AI应用
>> AI 代理(Agent)/智能体:通过对话与用户交互的 AI 项目,自动调用插件或工作流以执行任务并生成响应。典型应用包括智能客服、虚拟助手、英语导师等。
>> AI 应用(AI Application):具备完整业务逻辑和可视化用户界面的 AI 项目,适用于各种场景,如 AI 搜索、翻译工具、健康管理等。
2、Coze 的能力
>> 先进 AI 模型支持: 集成 OpenAI、Cohere、Google Gemini、Anthropic 等主流大模型,适用于不同 AI 生成场景。
>> 开箱即用的工具: 提供 UI 构建器、语音交互、快捷指令等,提高开发效率。
>> 高精度与自定义数据支持: 可利用自有数据增强 AI 生成效果,并集成插件访问外部实时数据。
>> 易用的编排与调试: 提供可视化交互界面,简化开发、追踪与调试流程。
>> 多渠道部署: 支持 AI 应用发布到网站、移动端、社交平台,并可作为 API 端点扩展使用。
>> 探索最新 AI 服务: 在 Coze 商店中浏览并尝试热门 AI 服务和模型。
3、架构
Coze 提供端到端的 AI 开发解决方案,涵盖开发、评估、监控和发布等全流程,支持 AI 代理(Agent)和 AI 应用(AI App),并提供多样化的发布选项。Workspace(工作区)是最高级别的资源组织单位,不同工作区间的数据相互隔离,多个 AI 应用和代理可以共享同一工作区的资源库。
| 工作区 | 工作区(Workspace): 资源和数据的基本组织单元,不同工作区间互不干扰。 |
| 项目 | 项目(Project): 包含 AI 代理和 AI 应用,可在项目中创建特定资源,或共享工作区的资源库。 |
| AI 代理 | AI 代理(Agent):具有自动化任务执行、决策和学习能力的 AI 项目。可调用 LLMs、知识库、插件等执行用户指令。 |
| AI 应用 | AI 应用(AI App):使用 LLMs 进行数据分析和决策,支持复杂任务处理。 |
| 资源库 | 资源库(Resource Library): 工作区资源库:为该工作区内所有 AI 代理和 AI 应用提供共享资源。 项目资源库:仅限于该项目使用,默认不可共享,但可以手动转移至工作区资源库。 |
4、核心功能
>> 编排和开发:Coze提供最新的大型语言模型选择、提示工程、编排模式(单代理和多代理)、任务执行能力(插件/工作流/触发器)等功能。
>> 知识管理:利用检索增强生成(RAG)功能,通过上传数据到知识库,增强LLMs的响应。
>> 记忆系统:Coze提供变量、数据库、长期记忆、文件管理等功能,以存储、检索和利用信息,提高模型的响应准确性和相关性。
>> 聊天体验:Coze提供丰富的功能,用于增强AI聊天机器人的体验,如设置欢迎文本、建议问题、选择声音等。
>> 部署和集成:Coze支持将AI应用部署到多个渠道,如Discord、Telegram、Facebook Messenger等,并提供API或Web SDK集成能力。
>> 团队协作与权限:工作区(Workspace)作为团队协作单位,支持资源共享与权限管理。支持 API 级别权限配置,确保数据安全性。
Coze的安装和使用方法
1、安装
在线使用地址:扣子
2、使用方法
在Coze平台上快速构建一个AI智能体,以一个“赞美机器人”为例,循序渐进地在Coze平台上创建、配置和发布一个AI智能体的完整流程,并详细介绍了每个步骤的关键操作和注意事项,旨在帮助用户快速上手Coze平台并构建自己的AI应用。提示词非常重要,通过添加技能来扩展AI能力,让用户能够轻松地将AI智能体应用于各种实际场景。
第1步,创建智能体
在Coze平台上创建新的AI智能体。用户可以通过两种方式创建:
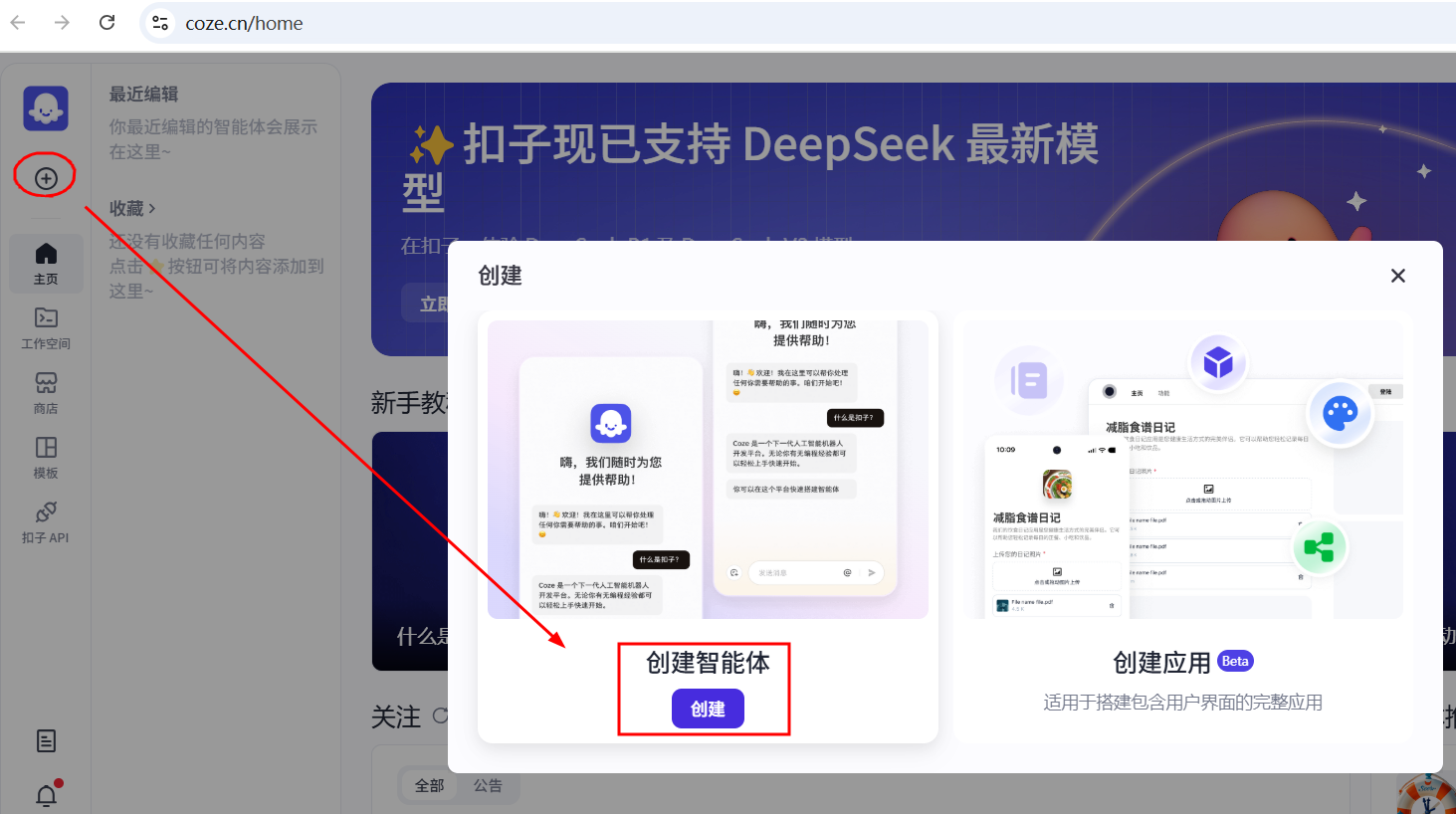
T1、手动创建
用户需要输入智能体的名称和功能描述,系统会自动生成头像。
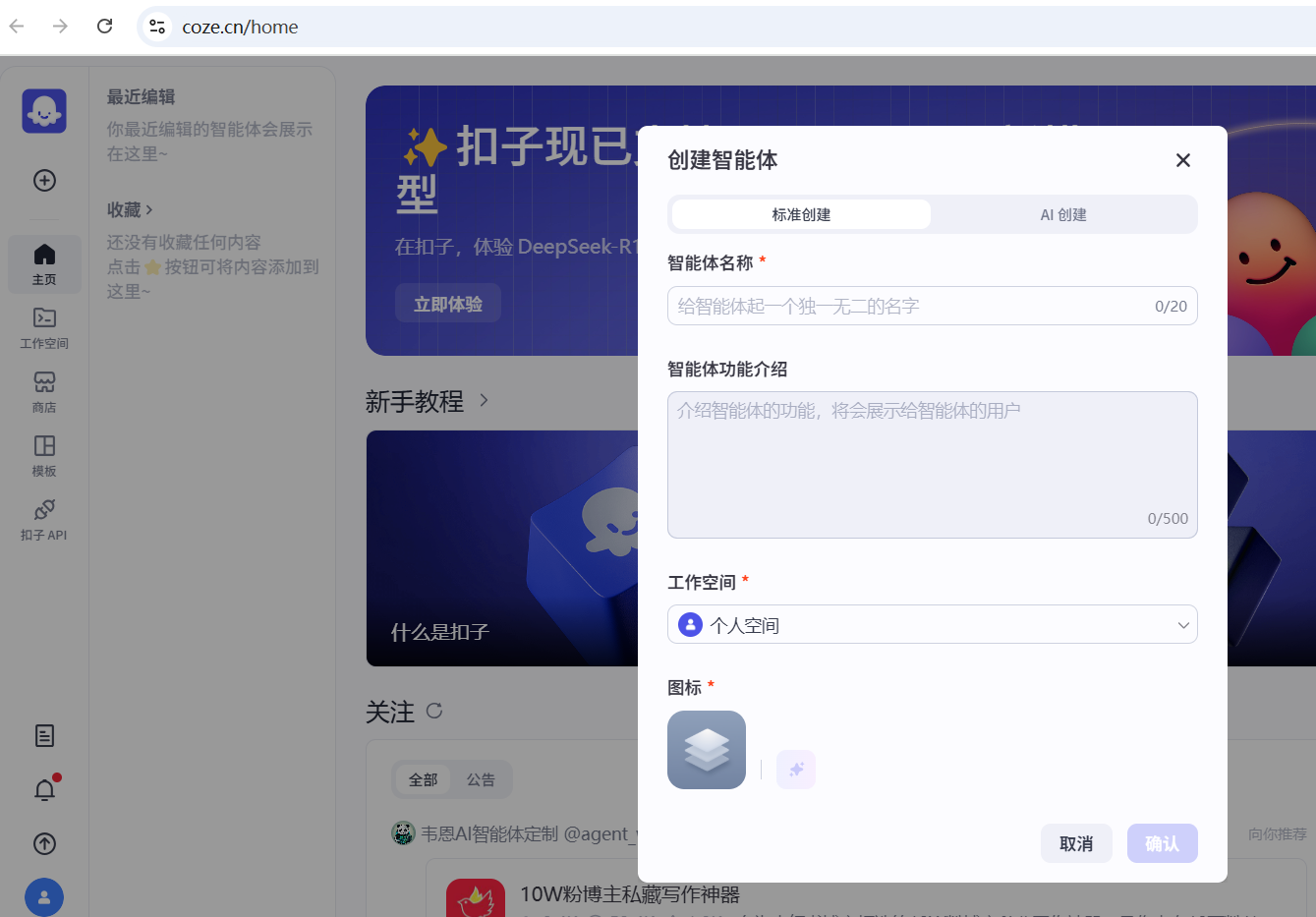
T2、AI辅助创建
用户可以使用自然语言描述需求,Coze平台会根据描述自动创建一个智能体。
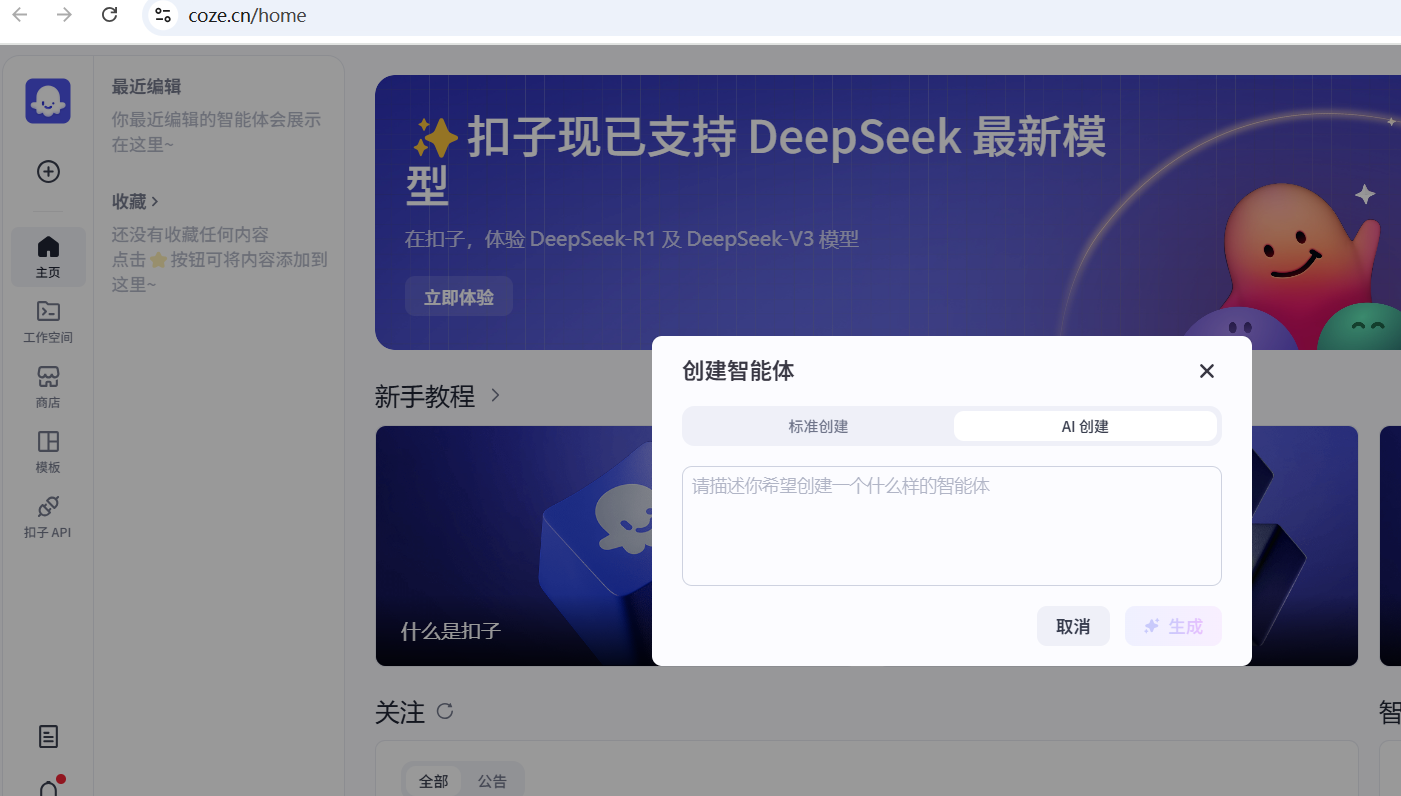
智能体开发页面
创建完成后,用户会进入智能体开发页面,该页面包含三个主要区域:
>> Persona & Prompt (角色和提示词):用于定义智能体的角色、语言风格和行为边界。
>> Skills (技能):用于配置智能体的扩展能力,例如接入外部插件。
>> Preview & Debug (预览和调试):用于实时调试智能体。
第2步,编写提示词
这是配置智能体的关键步骤。提示词(Persona & Prompt)定义了智能体的基本人格和行为准则,它会持续影响智能体在所有对话中的回应。建议用户明确模型的角色、设计回复的语言风格,并限制模型的回复范围,以使聊天更符合用户预期。
本案例以“赞美机器人”为例,给出了详细的提示词示例,包括角色设定、不同类型的赞美技能(外貌、成就、性格)以及行为约束(始终使用积极的语言,避免负面评价)。 用户还可以点击“Optimize”按钮,让大型语言模型优化提示词结构。
第3步,(可选)添加技能
如果模型本身的能力足以满足智能体的功能需求,则只需编写提示词即可。但如果需要扩展智能体的功能,例如处理多模态内容(图片、PPT等)或访问特定领域的专业知识,则需要添加技能。以“赞美机器人”为例,通过添加Bing搜索插件来增强其信息检索能力。 这部分强调了模型能力的局限性以及扩展其能力的必要性。
第4步,调试智能体
在配置完成后,用户可以在“Preview & Debug”区域测试智能体是否符合预期。 这部分强调了测试的重要性,确保智能体能够正常工作。
第5步,发布智能体
调试完成后,用户可以将智能体发布到不同的渠道,例如Lark、微信、抖音、Cici等。用户可以根据自身需求和业务场景选择合适的渠道。可知智能体的应用场景和发布方式的多样性。
Coze的案例应用
持续更新中……



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











