









LLMs之Agent:OpenAI Operator的简介、安装和使用方法、案例应用之详细攻略
目录
1、安全和隐私:三层防护措施=用户控制+数据管理+反欺诈机制
OpenAI Operator的简介
Operator 是 OpenAI 推出的一款 AI 代理,它能够使用自己的浏览器自主完成用户在网页上的各种任务。它通过模拟人类操作(例如:打字、点击、滚动)与网页交互,无需自定义 API 集成。目前 Operator 处于研究预览阶段,这意味着它仍存在一些局限性,并会根据用户反馈不断改进。Operator 是 OpenAI 推出的首批能够独立完成用户任务的 AI 代理之一——你只需下达指令,它就会执行。它可以处理各种重复性的浏览器任务,例如填写表格、订购商品,甚至创建表情包等,从而节省用户时间,并为企业带来新的参与机会。目前仅限美国专业版用户使用,未来计划扩展到 Plus、Team 和 Enterprise 用户,并集成到 ChatGPT 中。Operator 目前仍处于早期研究预览阶段,虽然它已经能够处理各种各样的任务,但它仍在学习和发展中,可能会犯错。例如,它目前在处理复杂界面(例如:创建幻灯片或管理日历)方面存在挑战。早期用户反馈对于提高其准确性、可靠性和安全性至关重要。Operator 是一款功能强大的 AI 代理,但仍处于发展阶段,未来潜力巨大。
- 核心功能: Operator是一个能够自主使用浏览器完成用户指令的AI代理,可以进行网页交互(例如:输入、点击、滚动),从而执行各种网络任务。
- 技术基础: 基于名为Computer-Using Agent (CUA)的新模型,该模型结合了GPT-4的视觉能力和强化学习的高级推理能力,能够与图形用户界面(GUI)进行交互。
- 当前状态: 目前处于研究预览阶段,仅限美国专业版用户使用,未来计划扩展到Plus、Team和Enterprise用户,并集成到ChatGPT中。
- 应用场景: 可以处理各种重复性的浏览器任务,例如填写表格、订购商品、创建表情包等,提升效率,拓展商业机会。
- 发布策略: 分阶段逐步推广,先向专业版用户开放,收集反馈,再逐步扩展到其他用户群体。
官网文章:https://openai.com/index/introducing-operator/
1、安全和隐私:三层防护措施=用户控制+数据管理+反欺诈机制
OpenAI 将 Operator 的安全和隐私放在首位,设置了三层防护措施:
>> 用户控制:Operator 经过训练,会在关键步骤(例如:登录、支付等)主动请求用户接管,确保用户始终掌控操作流程。在用户接管模式下,Operator 不会收集或截取用户输入的信息。此外,在执行重要操作(例如:提交订单、发送邮件)前,Operator 会要求用户确认。它还会拒绝处理某些敏感任务,例如银行交易或需要高风险决策的任务(例如:求职申请)。对于特别敏感的网站(例如:邮箱或金融服务网站),Operator 需要用户密切监督其操作,以便用户及时发现潜在错误。
>> 数据管理:用户可以轻松管理数据隐私。可以通过关闭 ChatGPT 设置中的“改进所有人的模型”选项,来阻止 Operator 数据用于模型训练。用户可以在 Operator 设置的“隐私”部分一键删除所有浏览数据和注销所有网站,也可以一键删除过去的对话记录。
>> 反欺诈机制:Operator 具备防御恶意网站的能力。它能够检测并忽略隐藏的提示和恶意代码,并通过一个专门的“监控模型”来检测可疑行为,并在发现异常时暂停任务。此外,OpenAI 还采用了自动化和人工审核流程来持续识别新的威胁并快速更新安全措施。OpenAI 还明确表示,会拒绝有害请求并阻止不允许的内容,并会对违规行为进行警告甚至撤销访问权限。
2、未来规划
>> CUA API 开放:OpenAI 计划很快通过 API 公开 Operator 背后的 CUA 模型,以便开发者能够使用它来构建自己的计算机使用代理。
>> 能力增强:OpenAI 将继续改进 Operator 处理更长、更复杂工作流程的能力。
>> 用户扩展:OpenAI 计划在确保安全性和可用性之后,将 Operator 扩展到 Plus、Team 和 Enterprise 用户,并将其功能直接集成到 ChatGPT 中,从而实现无缝的实时和异步任务执行。
OpenAI Operator的安装和使用方法
1、安装
Operator 目前仅限美国专业版 ChatGPT 用户使用,访问地址:https://operator.chatgpt.com/
2、使用方法
比如让Operator自动帮你发一个微博,它首先会自动打开网页版的微博界面,其次,撰写一个微博内容,如果其中内容不合适,你可以在下方实时页面中随时接入,然后让它发送微博内容即可。

使用方法很简单:用户只需描述想要完成的任务,Operator 就会处理剩下的工作。用户可以随时接管远程浏览器的控制权。用户还可以通过添加自定义指令来个性化工作流程,例如为 Booking.com 上的航空公司设置偏好。Operator 允许用户保存提示以方便快速访问,这对于重复性任务(例如:在 Instacart 上补充库存)非常理想。类似于使用浏览器的多个标签页,用户可以通过创建新的对话来同时让 Operator 执行多个任务(例如:在 Etsy 上订购个性化珐琅杯的同时,在 Hipcamp 上预订营地)。
测试地址:https://operator.chatgpt.com/
- 任务提交: 用户只需描述想要完成的任务,Operator即可执行。
- 用户接管: 用户可以随时接管远程浏览器控制权。
- 自动请求用户干预: 在需要登录、输入支付信息或解决验证码等情况下,Operator会主动请求用户干预。
- 自定义指令: 用户可以添加自定义指令,个性化工作流程,例如设置特定网站的偏好设置。
- 保存提示: 用户可以保存常用提示,方便重复任务的执行。
- 多任务处理: 用户可以通过创建新的对话来同时执行多个任务。
OpenAI Operator的案例应用
可以处理各种重复性的浏览器任务,例如填写表格、订购商品、创建表情包等,提升效率,拓展商业机会。 OpenAI 还与 DoorDash、Priceline、StubHub、Thumbtack、Uber 等多家公司合作,以确保 Operator 能够满足现实世界的需求。
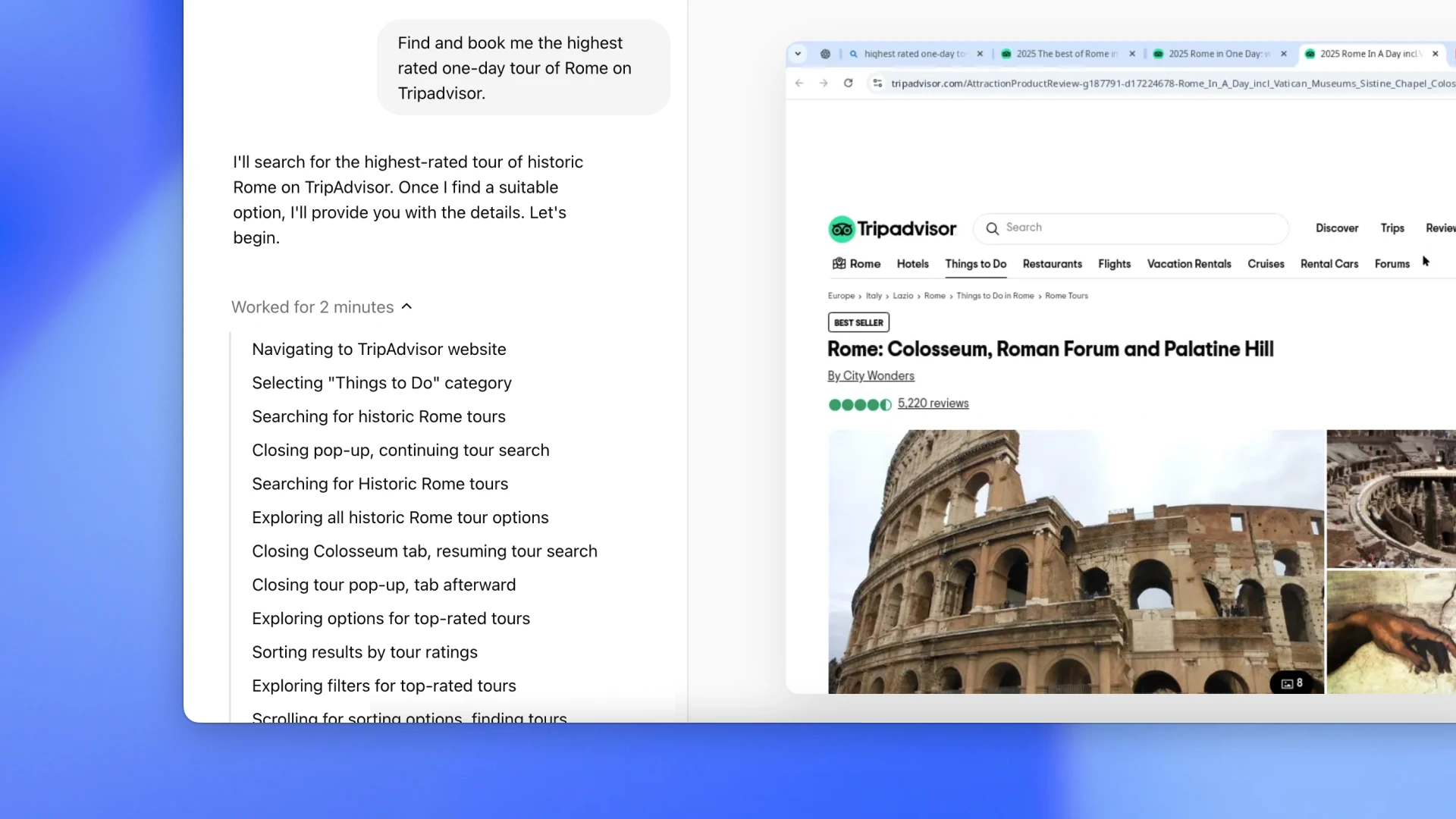
旅游预订
根据用户需求,在 TripAdvisor 上查找并预订评价最高的罗马一日游。
购物
订购杂货(Instacart)、订购个性化商品(Etsy)。
预订服务
预订营地(Hipcamp)、预订餐馆(OpenTable)。
公共服务
与 Stockton 市合作,简化城市服务的注册流程。



















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











