







1、前言
本文章主要针对大学本科阶段学生;
读文章之前先来几个灵魂拷问:
1、你是否学过《微机原理》、《单片机》、《汇编语言》之类有关微型计算机的课程?
2、上这些课时你的老师是否只是机械的讲着PPT,你听着无聊,听不懂,逐渐对计算机专业产生了畏惧?
3、这些计算机专业的基础课程你学懂了吗?悟了吗?真正理解了吗?
4、这些课里面的专业术语你理解吗?寄存器、总线、累加器。。。
以上4条都真正理解的人少之又少,你上学时怎么都理解不了,出来上班后就逐渐理解了,这是为啥呢?
因为上学时你面对的是枯燥的课本和混日子至念PPT的老师,加之这些东西都是抽象的没有实物,你只能靠脑子想象,所以难以理解;
出来上班后你面对的是代码,电路,板子,项目,以及公司里的大佬,你接触的是实实在在的东西,所以没有距离感,你天天敲着代码,书本里的寄存器什么的都是你敲出来的,加之专业的大佬给你指点明津,所以你很容易就理解了;
2、设计思想和架构
本设计采用纯verilog代码编写,可在FPGA上综合、编译、运行,起实质就是一个小型CPU;
主要参数如下:
8位数据总线;
8位地址总线;
2位控制总线;
256字节ROM;用于存放cpu指令;
256字节RAM;用于存放cpu数据;
1字节的cache,用于存放cpu计算的中间结果和预取;
32字节通用计算器,用于暂存cpu计算的中间结果;
2字节指令寄存器,用于暂存cpu指令和预取;
CPU功能很简单,取ROM里面的65、66、67地址的三个常数累加和并输出,整个过程由CPU自动完成,功能虽然简单,却涵盖了计算机架构的基本内容和操作顺序,后续的功能强大的CPU,也是由这样简单的计数慢慢发展起来的,其实CPU的本质是很笨的,他只会最简单的1+1的数学题,小学生水平都不如,只不过他的计算速度很快,显得很聪明而已,当你看懂了代码就会明白,计算机真的很蠢。
设计架构如下:
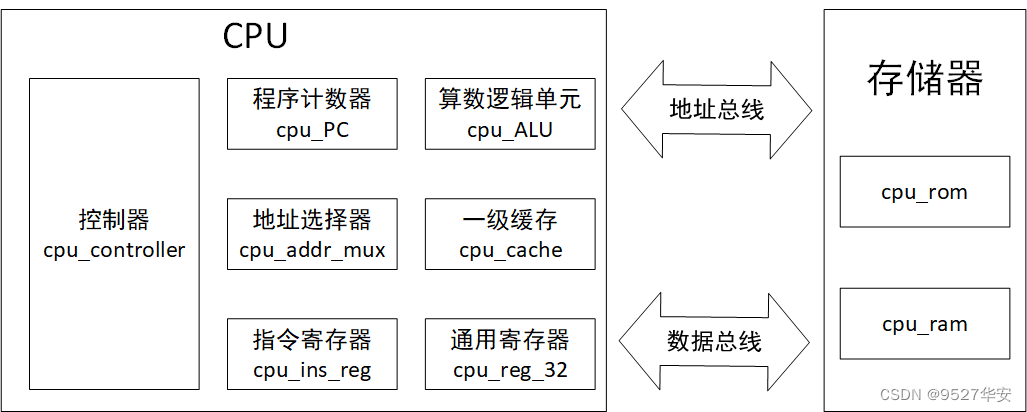
由于线太多不好连接,就画了一个框架;后面会一一讲解;
3、硬件组成讲解
ROM用于存储要执行的指令;指令采用精简指令集;
我们定义的RISC指令集长度类型两种,分别为短指令和长指令:
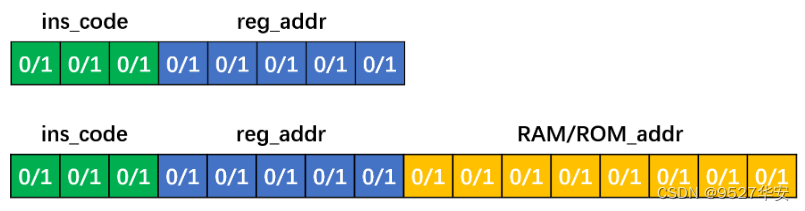
其中指令编码采用三位二进制表示,共定义有8种指令。短指令共8位,高三位为指令编码,低五位为通用寄存器地址。长指令为16位,每个长指令分两次取,每次取8位,首先取高8位,格式和短指令相通,也是高3位为指令编码,低5位为通用寄存器地址;第二次取低8位,表示ROM或者RAM地址,取决于指令编码。
所谓的指令集,听着很高级,其实就这么简单,就是认为规定的一些协议而已;
因此有指令集如下表所示,为了方便理解指令的缩写含义,表中用英文进行了描述并将缩写的由来使用加粗来表示:
//rom存储的是指令集
//短指令(8bit): 高三位为指令编码,低五位为通用寄存器地址
//3'b000 -->NOP 空操作
//3'b001 -->LDO Loads the contents of the ROM address into the REG address
//3'b010 -->LDA Loads the contents of the RAM address into the REG address
//3'b011 -->STO Store intermediate results into RAM address
//3'b100 -->PRE Prefetch Data from REG address
//3'b101 -->ADD Adds the contents of the REG address or integer to the accumulator
//3'b110 -->LDM Load Multiple
//3'b111 -->HLT 停机指令
ROM顶层接口如下:
module cpu_rom #(
parameter ADD_NUMBER_0 = 37, //测试的第一个累加数
parameter ADD_NUMBER_1 = 89, //测试的第二个累加数
parameter ADD_NUMBER_2 = 53 //测试的第三个累加数
)
(
input i_rom_read,
input i_rom_ena ,
input [7:0] i_rom_addr,
output [7:0] o_rom_data
);
ROM,只读指令。接受输入地址,当读信号和使能信号高电平时输出对应地址存储的指令,否则输出保持高阻态。地址和数据都是8位,可寻址以及内部存储的大小为256Bytes。
RAM存储数据,可读可写;接收8位地址,当读信号和使能信号有效时,输出对应地址存储的数据,否则输出保持高阻态。当写信号上升沿是触发,将输入输出写入地址对应位置。内部存储以及可循址大小也为256Byters。
RAM顶层接口如下:
module cpu_ram(
input i_ram_ena ,
input i_ram_read ,
input i_ram_write,
input [7:0] i_ram_addr ,
inout [7:0] io_ram_data
);
cpu_PC程序计数器,有时也叫做指令地址寄存器(Instruction Address Register, IAR),对应于Intel X86体系CPU中的指令指针(Instruction pointer)寄存器。其功能是用来存放要执行的下一条指令在现行代码段中的偏移地址。本文中PC由Controller自动修改,使得其中始终存放着下一条将要执行指令的地址。因此,PC是用来控制指令序列执行流程的寄存器。
cpu_PC顶层接口如下:
module cpu_PC(
input clk ,
input rstn ,
input i_en ,
output reg [7:0] o_pc_addr
);
异步清零。时钟上升沿触发,高电平使能时程序计数器计数,指向下一条要执行指令的地址。指令存储在ROM中,故每次pc_addr加1。
cpu_cache一级缓存,用于储存计算的中间结果。
cpu_cache顶层接口如下:
module cpu_cache(
input clk ,
input rstn ,
input i_ena ,
input [7:0] i_data,
output reg [7:0] o_data
);
异步清零。时钟上升沿触发,高电平使能时输出当前输入信号。
cpu_addr_mux地址选择器,接受控制使能信号对输入的来自程序计数器和指令寄存器的地址进行选择;
cpu_addr_mux顶层接口如下:
module cpu_addr_mux(
input [7:0] i_ir_ad,
input [7:0] i_pc_ad,
input i_addr_sel ,
output [7:0] o_addr_bus
);
当选择信号为1时,选择来自寄存器输入的地址到数据总线,否则将程序计数器中的地址加载到数据总线。
cpu_ALU算术逻辑运算单元,根据指令类型来决定进行哪种运算,从而将运算结果输出通用寄存器或者累加器中。
cpu_ALU顶层接口如下:
module cpu_ALU(
input [2:0] i_op ,
input [7:0] i_alu_in ,
input [7:0] i_accum ,
output reg [7:0] o_alu_out
);
cpu_reg_32通用寄存器,ALU输出结果,指令寄存器输出的操作数都可以存储到寄存器中的特定的地址。输出寄存器中存储的数据到数据总线。
cpu_reg_32顶层接口如下:
module cpu_reg_32(
input clk ,
input i_write,
input i_read ,
input [7:0] i_data ,
input [7:0] i_addr ,
output [7:0] o_data
);
当写信号有效时,将输入数据(来自ALU的输出)存储到寄存器中的特定地址。当读信号有效时,将寄存器中特定位置的数据输出(到数据总线)。寄存器大小为32Bytes。
cpu_ins_reg指令寄存器,从数据总线上获取数据,根据输入控制信号,根据指令类型将特定指令和地址输出到ALU,通用寄存器和地址选择器。
cpu_ins_reg顶层接口如下:
module cpu_ins_reg(
input clk ,
input rstn ,
input [1:0] i_fetch,
input [7:0] i_data ,
output [2:0] o_ins ,
output [4:0] o_ad1 ,
output [7:0] o_ad2
);
异步清零。当输入控制信号为01时表示数据总线当前为指令(形式为指令编码+寄存器地址,见第三章),将其从ins和ad1输出,当控制信号为10时,表示当前数据总线上的为数据(8位地址数据,见第三章),将其从ad2输出到地址选择器。
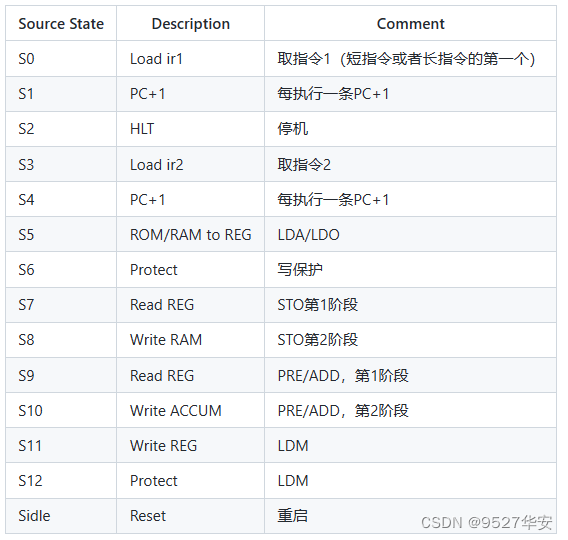
cpu_controller控制器是系统的核心,具有以下功能:取指令,指令排队,读写操作数,总线控制等。这里采用(Mealy型)有限状态机(FSM)来实现控制器,指令存储在ROM中来执行,控制器接受外界时钟和复位信号,控制器根据当前状态以及输入进行状态的转移。
根据指令的任务,设计了如上图所示的状态转移图,从左至右依次为状态Sidle,S0~S12。各个状态的含义如下:
cpu_controller顶层接口如下:
module cpu_controller(
input clk ,
input rstn , // clock, reset
input [2:0] i_ins , // i_instructions, 3 bits, 8 types
// Enable signals
output reg o_write_r,
output reg o_read_r ,
output reg o_PC_en , //控制地址总线, o_PC_en为高时地址总线+1
output reg o_ac_ena ,
output reg o_ram_ena,
output reg o_rom_ena,
// ROM: where i_instructions are storaged. Read only.
// RAM: where data is storaged, readable and writable.
output reg o_ram_write ,
output reg o_ram_read ,
output reg o_rom_read ,
output reg o_ad_sel ,
output reg [1:0] o_fetch // 01: to o_fetch from RAM/ROM; 10: to o_fetch from REG
);
最后将各个高性模块例化成一个顶层,顶层代码如下:
module risc_8bit_cpu #(
parameter ADD_NUMBER_0 = 20, //测试的第一个累加数
parameter ADD_NUMBER_1 = 40, //测试的第二个累加数
parameter ADD_NUMBER_2 = 6 //测试的第三个累加数
)(
input clk ,
input rstn ,
output [7:0] o_cpu_out
);
wire write_r, read_r, PC_en, ac_ena, ram_ena, rom_ena;
wire ram_write, ram_read, rom_read, ad_sel;
wire [1:0] fetch; //控制总线
wire [7:0] data; //地址总线
wire [7:0] addr; //数据总线
wire [7:0] accum_out, alu_out;
wire [7:0] ir_ad, pc_ad;
wire [4:0] reg_ad;
wire [2:0] ins;
assign o_cpu_out=accum_out;
//RAM存储数据,可读可写
cpu_ram u_cpu_ram(
.io_ram_data(data ),
.i_ram_addr(addr ),
.i_ram_ena (ram_ena ),
.i_ram_read(ram_read ),
.i_ram_write(ram_write)
);
//ROM用于存储要执行的指令,只读
cpu_rom #(
.ADD_NUMBER_0 (ADD_NUMBER_0), //测试的第一个累加数
.ADD_NUMBER_1 (ADD_NUMBER_1), //测试的第二个累加数
.ADD_NUMBER_2 (ADD_NUMBER_2) //测试的第三个累加数
)u_cpu_rom(
.o_rom_data(data ),
.i_rom_addr(addr ),
.i_rom_ena (rom_ena ),
.i_rom_read(rom_read)
);
//地址选择器,接受控制使能信号对输入的来自程序计数器和指令寄存器的地址进行选择
//sel-->1 输出指令寄存器地址
//sel-->0 输出程序计数器地址
cpu_addr_mux u_cpu_addr_mux(
.o_addr_bus(addr ),
.i_addr_sel(ad_sel),
.i_ir_ad (ir_ad ),
.i_pc_ad (pc_ad )
);
//PC程序计数器,用来存放要执行的下一条指令在现行代码段中的偏移地址
//输出地址总线的值
//PC_en为高时地址总线+1
cpu_PC u_cpu_PC(
.clk (clk ),
.rstn (rstn ),
.i_en (PC_en),
.o_pc_addr(pc_ad)
);
//缓存,用于储存计算的中间结果
cpu_cache u_cpu_cache(
.o_data(accum_out),
.i_data(alu_out ),
.i_ena (ac_ena ),
.clk (clk ),
.rstn (rstn )
);
//算术逻辑运算单元,根据指令类型来决定进行哪种运算,从而将运算结果输出通用寄存器或者累加器中
cpu_ALU u_cpu_ALU(
.o_alu_out(alu_out ),
.i_alu_in (data ),
.i_accum (accum_out),
.i_op (ins )
);
//通用寄存器,ALU输出结果,指令寄存器输出的操作数都可以存储到寄存器中的特定的地址。输出寄存器中存储的数据到数据总线
cpu_reg_32 u_cpu_reg_32(
.i_data (alu_out ),
.o_data (data ),
.i_write(write_r ),
.i_read (read_r ),
.i_addr ({ins,reg_ad}),
.clk (clk )
);
//指令寄存器,从数据总线上获取数据,根据输入控制信号,根据指令类型将特定指令和地址输出到ALU,通用寄存器和地址选择器
//fetch==2'b01 operation1, to fetch data from RAM/ROM
//fetch==2'b10 operation2, to fetch data from REG
cpu_ins_reg u_cpu_ins_reg(
.i_data (data ),
.i_fetch(fetch ),
.clk (clk ),
.rstn (rstn ),
.o_ins (ins ),
.o_ad1 (reg_ad),
.o_ad2 (ir_ad )
);
//控制器,核心部分
cpu_controller u_cpu_controller(
.i_ins (ins ),
.clk (clk ),
.rstn (rstn ),
.o_write_r (write_r ),
.o_read_r (read_r ),
.o_PC_en (PC_en ),
.o_fetch (fetch ),
.o_ac_ena (ac_ena ),
.o_ram_ena (ram_ena ),
.o_rom_ena (rom_ena ),
.o_ram_write(ram_write),
.o_ram_read (ram_read ),
.o_rom_read (rom_read ),
.o_ad_sel (ad_sel )
);
endmodule
4、vivado仿真
仿真代码如下:
`timescale 1ps / 1ps
module risc_8bit_cpu_tb ;
parameter T=10;
reg rstn ;
reg clk ;
risc_8bit_cpu #(
.ADD_NUMBER_0 (20),
.ADD_NUMBER_1 (60),
.ADD_NUMBER_2 (9 )
)u_risc_8bit_cpu(
.rstn (rstn),
.clk (clk ),
.o_cpu_out()
);
initial begin
rstn=0;
clk=0;
#100;
rstn=1;
#1000;
$stop;
end
always #(T/2) clk=~clk;
endmodule
仿真结果如下:
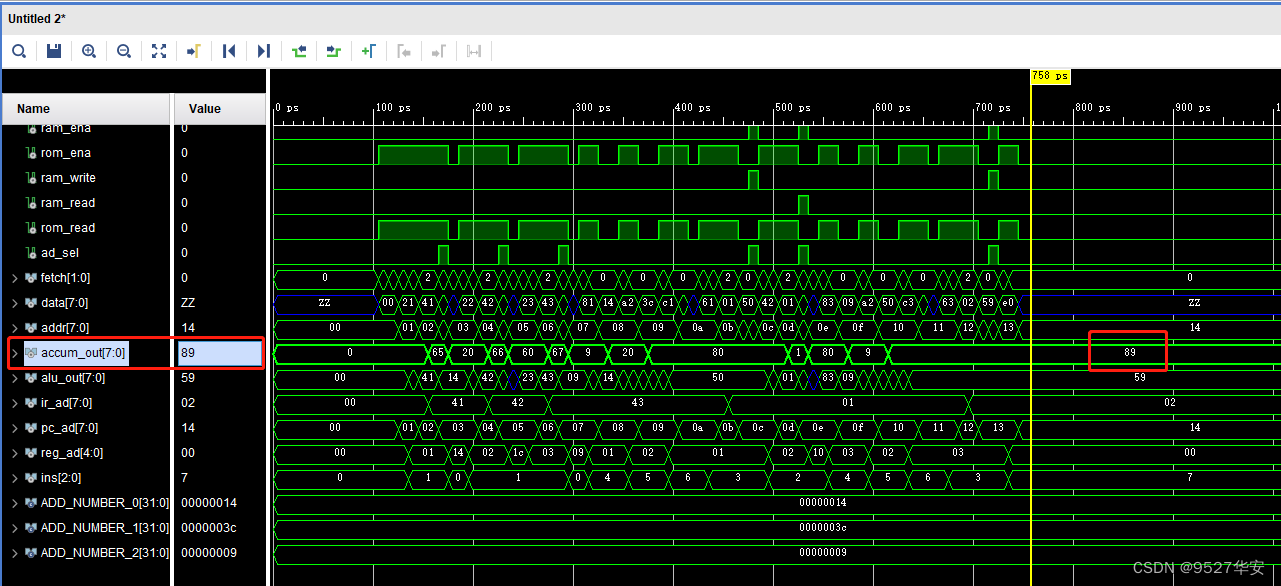
在testbench中我们填入的三个数如下:
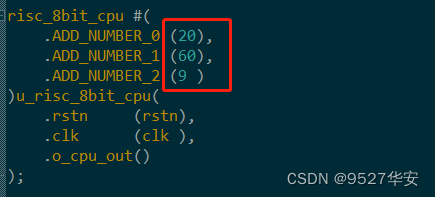
累加和等于89;仿真波形红圈的计算结果也是89;功能正常;
下面改变输入如下:
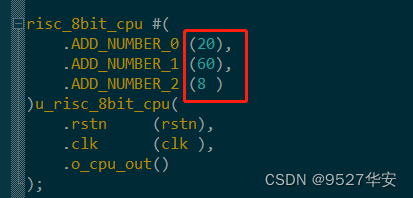
此时累加和等于88,再仿真结果如下:
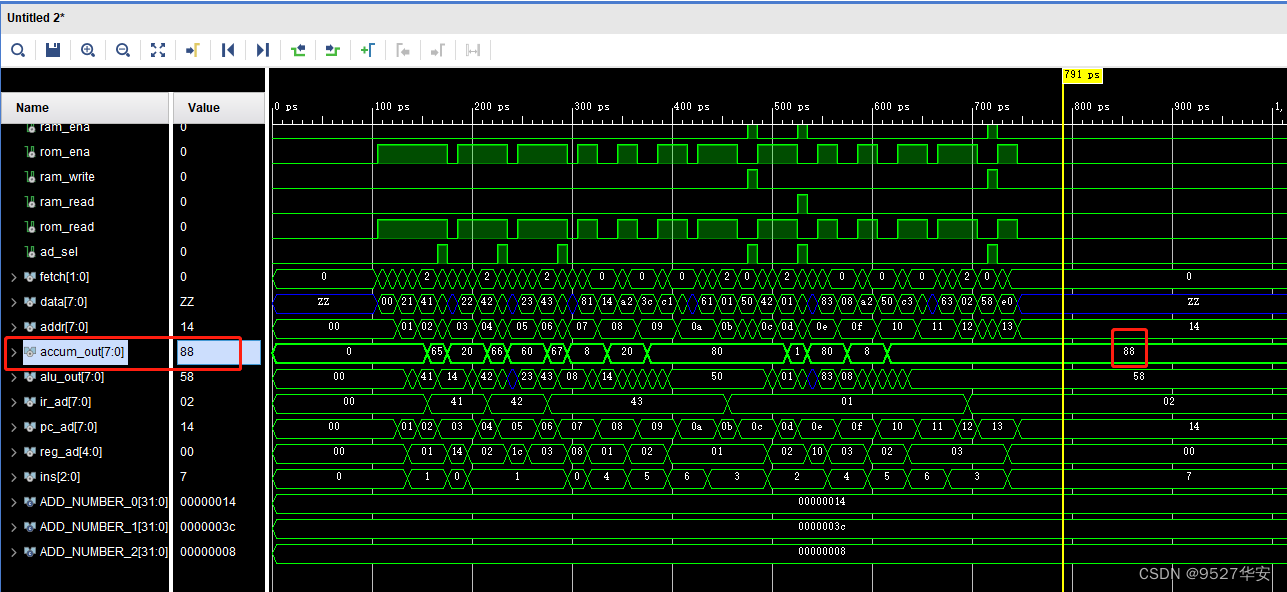
仿真波形红圈的计算结果也是88;功能正常;
5、vivado工程
开发板:Xilinx Artix7开发板;
开发环境:vivado2019.1;
输出:led灯;
系统上电后cup核自动运行,并输出累加和,若输出的累加和与输入的一致则led等闪烁,否则led常灭;
工程顶层代码如下:
module top(
input clk_in1_p,
input clk_in1_n,
output led
);
parameter ADD_NUMBER_0 = 20; //测试的第一个累加数
parameter ADD_NUMBER_1 = 60; //测试的第二个累加数
parameter ADD_NUMBER_2 = 8; //测试的第三个累加数
parameter CPU_SUM=ADD_NUMBER_0+ADD_NUMBER_1+ADD_NUMBER_2;
parameter SYS_TIME=100;
parameter SYS_TIPS=1000/SYS_TIME;
parameter LED_CYC_80MS=80000000/SYS_TIPS;
wire [7:0] o_cpu_out;
wire led_run;
reg [31:0] cnt;
assign led_run=(o_cpu_out==CPU_SUM)? 1'b1: 1'b0;
assign led= (cnt<LED_CYC_80MS/2)? 1'b0: 1'b1;
always @(posedge clk_100m) begin
if(~rstn) cnt<='d0;
else if(led_run) begin
if(cnt<LED_CYC_80MS) cnt<=cnt+'d1;
else cnt<='d0;
end
else cnt<='d0;
end
clk_wiz_0 u_clk_wiz_0
(
.clk_100m(clk_100m), // output clk_100m
.locked(rstn), // output locked
.clk_in1_p(clk_in1_p), // input clk_in1_p
.clk_in1_n(clk_in1_n)
);
risc_8bit_cpu #(
.ADD_NUMBER_0(ADD_NUMBER_0), //测试的第一个累加数
.ADD_NUMBER_1(ADD_NUMBER_1), //测试的第二个累加数
.ADD_NUMBER_2(ADD_NUMBER_2) //测试的第三个累加数
)helai_risc_8bit_cpu(
.clk (clk_100m ),
.rstn (rstn ),
.o_cpu_out(o_cpu_out)
);
endmodule
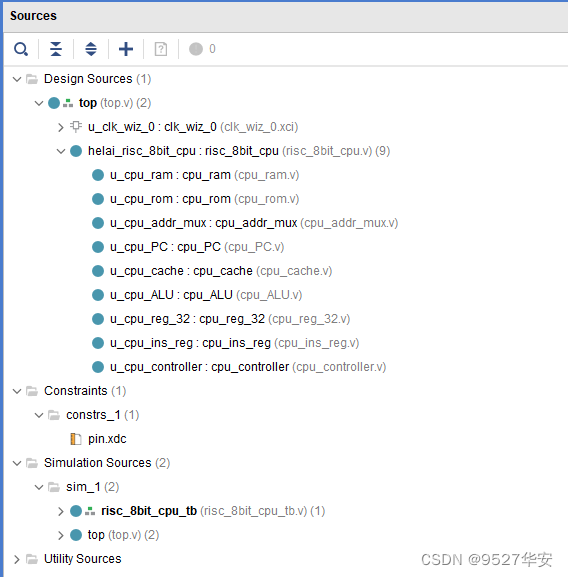
代码架构如下:
6、上板调试验证
上板输出演示视频如下:
上板输出演示视频
7、福利:工程源码获取
福利:工程代码的获取
代码太大,无法邮箱发送,以某度网盘链接方式发送,
资料如下:获取方式:文章末尾的V名片。
网盘资料如下:
也可直接下载工程源码,
点击下载工程源码

















 3751
3751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











