







《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
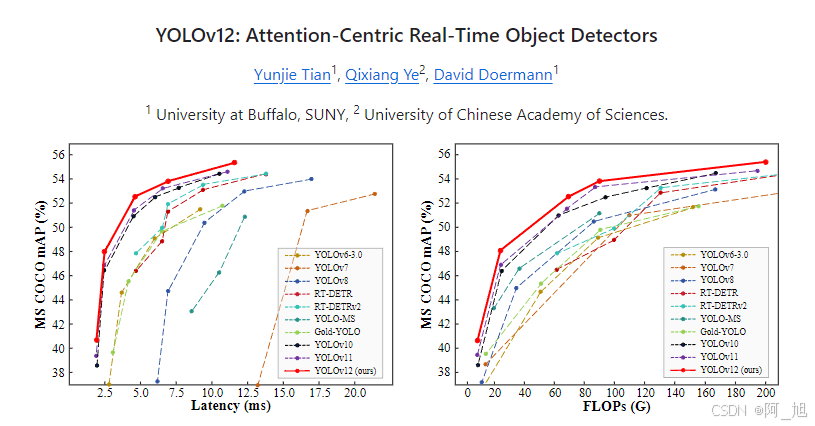
引言
本文将详细介绍如何使用YOLOv12进行目标检测模型的训练与推理,包含完整代码示例和实战技巧,建议收藏后阅读!
论文:https://arxiv.org/abs/2502.12524
代码:https://github.com/sunsmarterjie/yolov12
运行环境配置
#创建虚拟环境
conda create -n yolov12 python=3.11
#激活环境
conda activate yolov12
# 安装核心依赖
pip install ultralytics
默认使用的cpu,如果需要使用GPU进行训练,需要安装GPU版本的Pytorch, 需要去Pytorch官网:https://pytorch.org/get-started/locally/,选择适合自己GPU的Pytorch进行安装。
首先卸载原环境中的Torch与TorchVision,然后再安装GPU版本。
pip uninstall torch
pip uninstall torchvision
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118

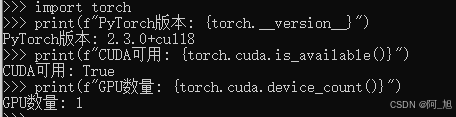
环境验证
import torch
print(f"PyTorch版本: {torch.__version__}")
print(f"CUDA可用: {torch.cuda.is_available()}")
print(f"GPU数量: {torch.cuda.device_count()}")
数据集准备
-
免费标注工具推荐:
- LabelImg(本地标注)
- LabelMe(本地标注)
-
安装标注工具
pip install labelImg labelImg # 启动图形界面 -
标注规范:
- 标注框紧贴目标边缘
- 遮挡目标需标注可见部分
- 小目标(<32x32)使用特殊标记
-
标注格式转换脚本(Pascal VOC转YOLO格式)
import xml.etree.ElementTree as ET
import os
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
classes = ["person", "car", "dog"] # 自定义类别
for xml_file in os.listdir("Annotations"):
tree = ET.parse(f"Annotations/{xml_file}")
root = tree.getroot()
with open(f"labels/{xml_file[:-4]}.txt", 'w') as f:
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
bbox = obj.find('bndbox')
pts = ['xmin', 'ymin', 'xmax', 'ymax']
bndbox = []
for pt in pts:
cur_pt = int(bbox.find(pt).text)
bndbox.append(cur_pt)
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
bb = convert((w,h), bndbox)
f.write(f"{cls_id} {' '.join([str(a) for a in bb])}\n")
- 数据集目录结构规范:
dataset/
├── images/
│ ├── train/
│ └── val/
└── labels/
├── train/
└── val/
- 创建数据集配置文件(
dataset.yaml):
path: ./dataset
train: images/train
val: images/val
names:
0: person
1: car
2: traffic_light
模型训练全流程
步骤1:选择预训练模型
| 模型 | 尺寸 (像素) | mAPval 50-95 | 速度 T4 TensorRT (ms) | params (M) | FLOPs (B) | 比较 (mAP/Speed) |
|---|---|---|---|---|---|---|
| YOLO12n | 640 | 40.6 | 1.64 | 2.6 | 6.5 | +2.1%/-9%(与 YOLOv10n 相比) |
| YOLO12s | 640 | 48.0 | 2.61 | 9.3 | 21.4 | +0.1%/+42%(与 RT-DETRv2 相比) |
| YOLO12m | 640 | 52.5 | 4.86 | 20.2 | 67.5 | +1.0%/-3%(与 YOLO11m 相比) |
| YOLO12l | 640 | 53.7 | 6.77 | 26.4 | 88.9 | +0.4%/-8%(与 YOLO11l 相比) |
| YOLO12x | 640 | 55.2 | 11.79 | 59.1 | 199.0 | +0.6%/-4%(与 YOLO11x 相比) |
根据需要选择自己想训练的模型大小,一般来说模型越大检测效果越好【但不绝对】。
- 官方提供的预训练权重:
- yolov12n.pt(纳米级)
- yolov12s.pt(轻量级)
- yolov12m.pt(均衡版)
- yolov12l.pt(大型版本)
- yolov12x.pt(超大型版本)
步骤2:模型训练
from ultralytics import YOLO
model = YOLO('yolov12s.pt') # 加载预训练模型
results = model.train(
data='dataset.yaml',
epochs=300,
imgsz=640,
batch=16,
device=0, # 使用GPU 0
optimizer='SGD',
lr0=0.001
)
关键训练参数解析
以下是一些常用的模型训练参数和说明:
| 参数名 | 默认值 | 说明 |
|---|---|---|
model | None | 指定用于训练的模型文件。接受指向 .pt 预训练模型或 .yaml 配置文件。对于定义模型结构或初始化权重至关重要。 |
data | None | 数据集配置文件的路径(例如 coco8.yaml).该文件包含特定于数据集的参数,包括训练数据和验证数据的路径、类名和类数。 |
epochs | 100 | 训练总轮数。每个epoch代表对整个数据集进行一次完整的训练。调整该值会影响训练时间和模型性能。 |
patience | 100 | 在验证指标没有改善的情况下,提前停止训练所需的epoch数。当性能趋于平稳时停止训练,有助于防止过度拟合。 |
batch | 16 | 批量大小,有三种模式:设置为整数(例如,’ Batch =16 ‘), 60% GPU内存利用率的自动模式(’ Batch =-1 ‘),或指定利用率分数的自动模式(’ Batch =0.70 ')。 |
imgsz | 640 | 用于训练的目标图像尺寸。所有图像在输入模型前都会被调整到这一尺寸。影响模型精度和计算复杂度。 |
device | None | 指定用于训练的计算设备:单个 GPU (device=0)、多个 GPU (device=0,1)、CPU (device=cpu),或苹果芯片的 MPS (device=mps). |
workers | 8 | 加载数据的工作线程数(每 RANK 多 GPU 训练)。影响数据预处理和输入模型的速度,尤其适用于多 GPU 设置。 |
name | None | 训练运行的名称。用于在项目文件夹内创建一个子目录,用于存储训练日志和输出结果。 |
pretrained | True | 决定是否从预处理模型开始训练。可以是布尔值,也可以是加载权重的特定模型的字符串路径。提高训练效率和模型性能。 |
optimizer | 'auto' | 为训练模型选择优化器。选项包括 SGD, Adam, AdamW, NAdam, RAdam, RMSProp 等,或 auto 用于根据模型配置进行自动选择。影响收敛速度和稳定性 |
lr0 | 0.01 | 初始学习率(即 SGD=1E-2, Adam=1E-3) .调整这个值对优化过程至关重要,会影响模型权重的更新速度。 |
lrf | 0.01 | 最终学习率占初始学习率的百分比 = (lr0 * lrf),与调度程序结合使用,随着时间的推移调整学习率。 |
步骤3:模型验证
from ultralytics import YOLO
model = YOLO('yolov12n.pt')
model.val(data='dataset.yaml', save_json=True)
步骤4:模型推理预测
1. 图像检测
model = YOLO('best.pt') # 加载训练好的模型
results = model('test.jpg',
conf=0.5, # 置信度阈值
save=True,
show_labels=True)
2. 视频流处理
results = model.predict(
source='input.mp4',
stream=True, # 启用流式处理
save_txt=True # 保存检测结果
)
3. 实时摄像头检测
model.predict(
source=0, # 默认摄像头
show=True, # 实时显示
classes=[0,2] # 只检测人和交通灯
)
模型导出
from ultralytics import YOLO
model = YOLO('yolo12n.pt')
model.export(format="engine", half=True) # or format="onnx"
常用导出格式:
| 格式 | format | 模型 | 是否支持 | 参数 |
|---|---|---|---|---|
| PyTorch | - | yolo12n.pt | ✅ | - |
| ONNX | onnx | yolo12n.onnx | ✅ | imgsz, half, dynamic, simplify, opset, nms, batch |
| OpenVINO | openvino | yolo12n_openvino_model/ | ✅ | imgsz, half, dynamic, int8, nms, batch, data |
| TensorRT | engine | yolo12n.engine | ✅ | imgsz, half, dynamic, simplify, workspace, int8, nms, batch, data |
性能优化技巧
- TensorRT加速:转换模型到
.engine格式 - 量化压缩:使用FP16精度减少模型体积
- 多尺度推理:增强小目标检测能力
model.predict(..., imgsz=[640, 1280]) # 多尺度测试

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











