







7.2.4 仿真与调试结果
1.Testbench设计 Testbench的设计非常简单,我们可以直接将捕获到的视频流接入 本模块即可,关键代码如下:
/*mean data*/
wire mean_dvalid;
wire [local_dw - 1:0]mean_data;
wire [local_dw+3-1:0]mean_data_frac;
wire mean_vsync;
/*mean data input*/
wire mean_dvalid_in;
wire [local_dw - 1:0]mean_data_in;
wire mean_vsync_in;
/*mean operation module*/
generate
if(mean_2d_en != 0)begin :mean_operation
Mean_2D_New#(local_dw,ksz_mean,ih,iw)
Mean_2D_New_ins(
.rst_n (reset_l),
.clk (cap_clk),
.din (mean_data_in),
.din_valid (mean_dvalid_in),
.dout_valid (mean_dvalid),.vsync(mean_vsync_in),
.vsync_out(mean_vsync),
.dout (mean_data),
.dout_frac(mean_data_frac)
);
assign mean_data_in = cap_data;
assign mean_vsync_in = cap_vsync;
assign mean_dvalid_in = cap_dvalid;
always @(posedge cap_clk or posedge mean_vsync )
if (((~(mean_vsync))) == 1'b0)
cnt_mean=0;
else
begin
if (mean_dvalid == 1'b1)
begin
fp_mean = $fopen("txt_out/mean.txt","r+");
$fseek(fp_mean,cnt_mean,0);
$fdisplay(fp_mean,"%04x\n",mean_data);
$fclose(fp_mean);
cnt_mean<=cnt_mean+6;
end
end
end
endgenerate2.模块仿真结果 1)一维求和模块(Sum_1D) 一维求和模块的仿真结果如图7-17所示。不妨从输入数据有效开始,截取10个时钟的数据进行分析。设竖 线所在时刻为t,×表示无关项,如表7-5所示。 由表7-5中可以看出,在第5个时钟,已经得到了5个将要求和的数 据,在下一个时钟,这5个数据的和将会计算出来,同时数据流首尾的 插值diff也被计算出来了。在下一个时钟,当前的计算值加上diff即 为新的求和结果。
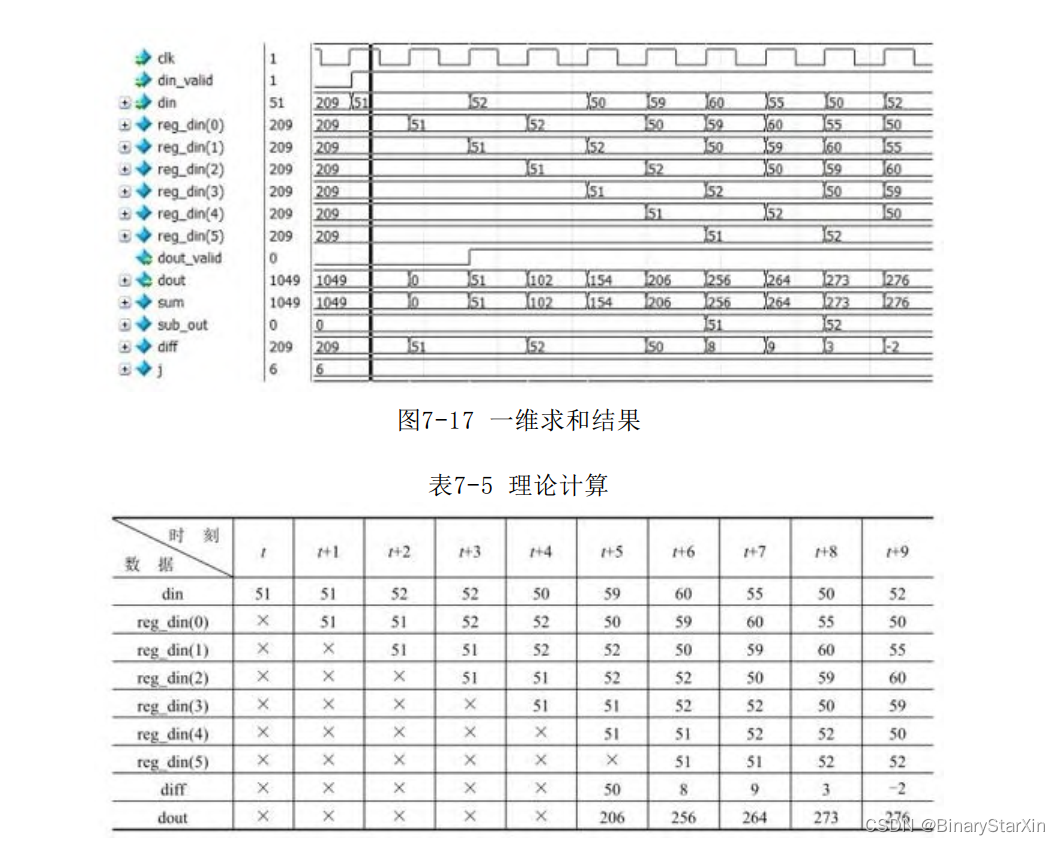
读者可能注意到,dout刚开始输出的两个时钟数据是无效的,这 是因为这两个时钟处在边界。我们将在二维处理中处理边界信息。因 此,读者需注意这两个时钟是无关项即可。2)除法电路 截取几个时钟的仿真,如图7-18所示。
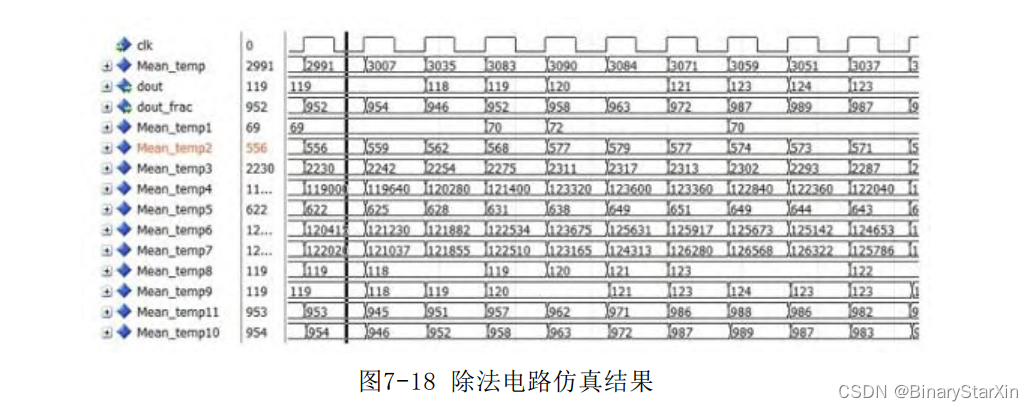
从上一节的代码设计中,我们知道Mean_temp为窗口求和的缓存, 经 过 3 个 时 钟 的 加 法 计 算 和 1 个 时 钟 的 缓 存 , 最 终 输 出 dout , 而 dout_frac是保留了3位小数的均值。从图示位置列出结果,同时与理 论均值做一个对比,如表7-6所示。
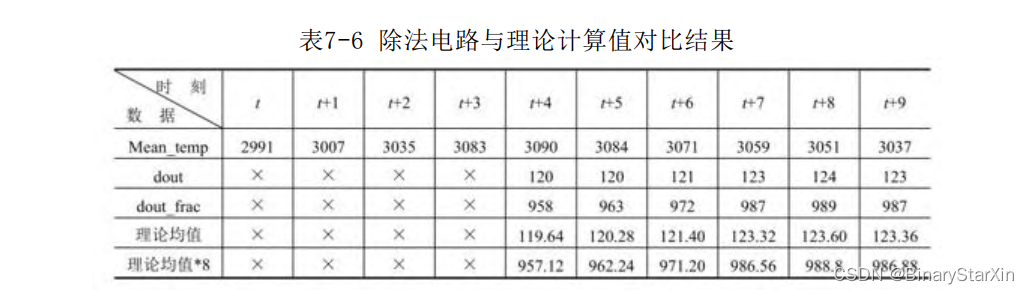
不难进行验证,除法计算结果正确。其中我们对整数输出进行四 舍五入处理。对带有3位精度的直接在末位加1处理。运算延迟为4个时 钟。 3)二维求和模块(Sum_2D)通过校验二维均值运算的结果来验证求和模块。图7-19(a)所示 为输入的原图像,经FPGA采集和5×5均值处理后的处理结果如图7- 19(b)所示。
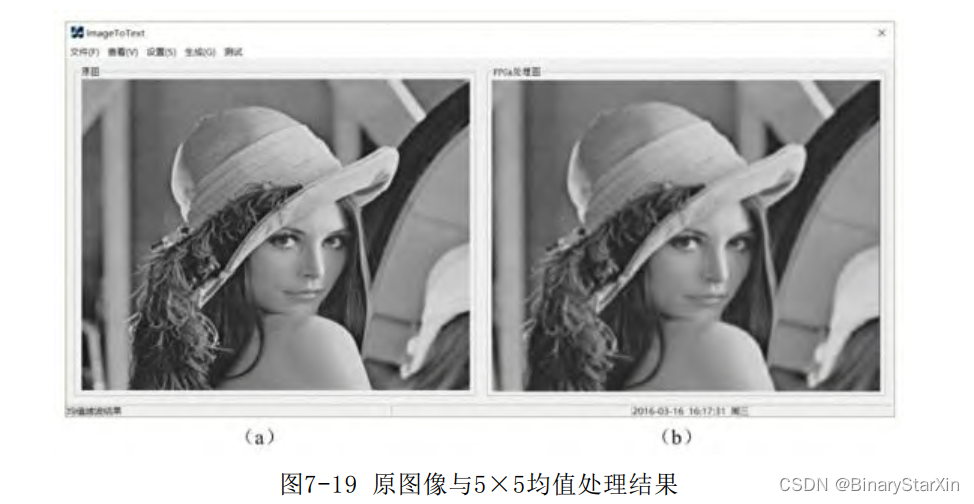
由图7-19可以看出,已经达到了预期的处理效果。不妨再用 11×11的窗口进行处理,效果如图7-20所示。模糊程度明显有所增 加,达到了我们预期的平滑目的。 3.算法实时性分析 对于处理窗口尺寸为KSZ×KSZ的窗口,至少需要等到前KSZ-1行缓 存完毕后才能得到第一个运算结果。因此,此算法的计算延时为 (KSZ-1)行。同时可以想到,数据从KSZ/2行,即半径行处开始有效 输出,不过此时输出的是边界信息,如图4-19所示的黑边。

通过仿真结果来验证这个推论,如图7-21所示是5×5处理窗口的 输入输出运算结果。仿真图也验证了我们的推论。

7.3 基于FPGA的Sobel算子
7.3.1 整体设计与模块划分
Sobel算子包括x和y两个方向的差分运算,并取其平方和根作为最 终取值,一般情况下,在FPGA处理中,考虑到效率和资源占用问题, 也可以用绝对值计算来代替。 将Sobel算子的表达式再次列出如下:
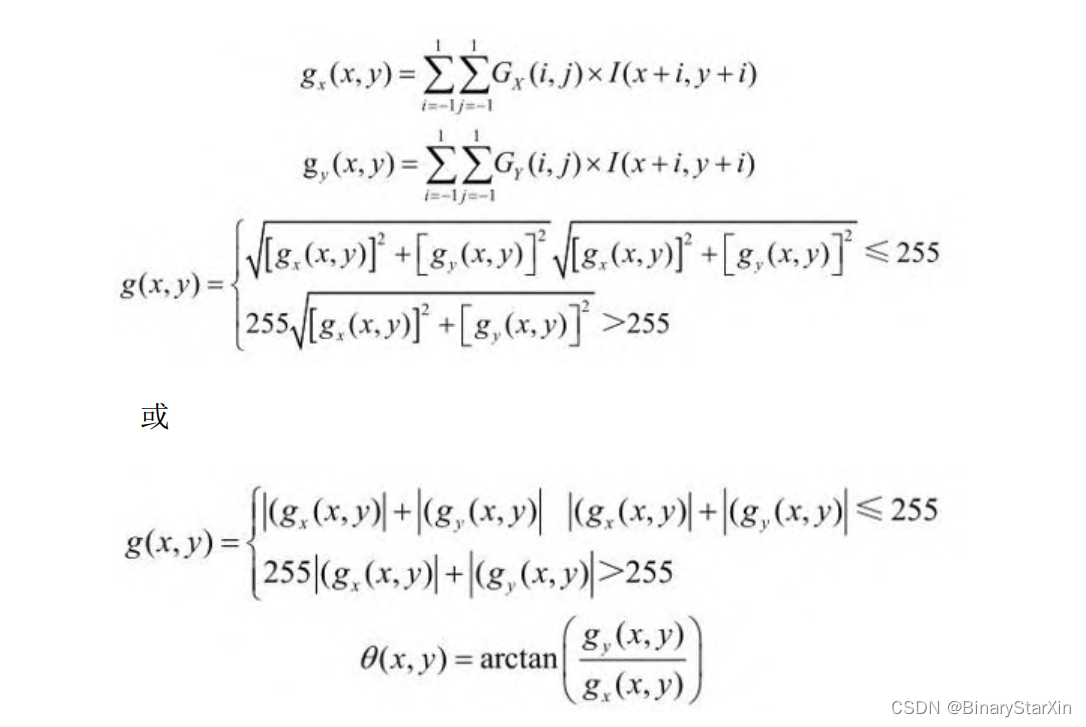
由数学表达式,计算Sobel算子需要首先计算x方向和y方向的微分 值gx (x,y)和gy (x,y),之后对两个微分结果分别求平方根或绝对值 相加并进行越界处理。在某些应用场合,可能需要用到梯度的方向, 因此,需同时计算出梯度方向θ(x,y)。 按照流水线设计的思路,单个像素的计算思路如图7-22所示。
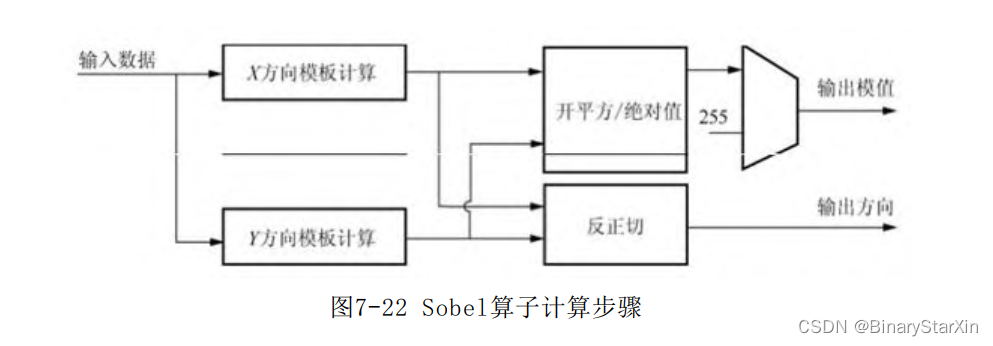
1.模板计算
两个方向的模板如何计算?由数学表达式可知,这个模板是尺寸 固定的3×3模板,我们同时需要连续三行连续三列的9个元素来读模板 进行相乘。很明显,我们需要两个行缓存来实现行列对齐。那么我们 可以按照求均值的计算方法将算法分解为行列上的操作吗?答案是否 定的,这是由于模板并不具有行一致性。
因此,我们的方法是同时得到当前窗口的9个元素,并对元素与模 板直接相乘。得到窗口9个像素无疑是比较简单的。将图像缓存两行, 加上当前行即为三行,将每行数据缓存两拍即可得到3列数据。 2.开平方及反正切计算 在软件中,开方操作和反正切运算均属于浮点运算。我们注意到 FPGA是不能直接处理浮点数的,因此如果直接按软件的思路进行浮点 计算,首先需要将定点数据转为浮点数,再进行浮点运算,转换完成 后再转换成定点。Altera也提供了强大的浮点运算IP核,包括乘法与 除法运算、开平方及正余弦反正切运算等。以本次计算需求为例,用 Altera的IP核实现的思路如图7-23所示。 首先来评估一下,需要调用的IP核和所消耗的资源(以下数据来 自quartus13.0):
(1)定点除法器IP核:LPM_DIVIDE,16位:304个查找表。
(2)浮点反正切IP核:ALTFP_ATAN,单精度:52个9bit dsp块, 8298个查找表,2347个reg。 (3)浮点求根号IP核:ALTFP_SQRT,单精度:370个查找表, 1433个reg。
(4)浮点与定点转换IP核:ALTFP_CONVERT 单精度:247个reg, 1个lpm_comare,5个lpm_add_sub。
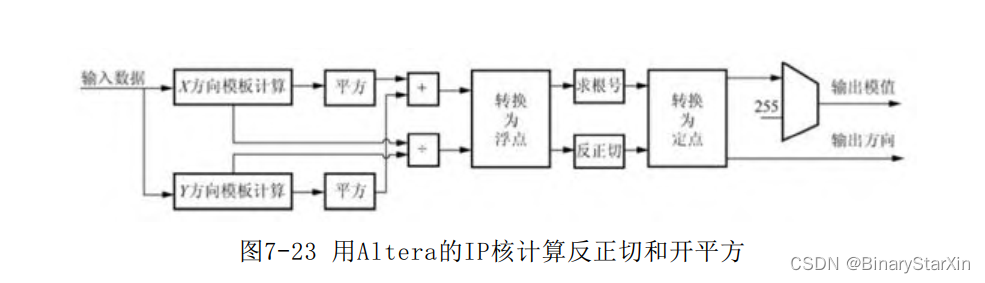
可以看出,如果采用这种方案,所带来的资源消耗是十分“恐 怖”的。这在某些资源紧张的应用场合,我们是无法接受这样的资源 消耗情况。因此,必须寻求其他的解决方案来实现此算法。 我们注意到,求取平方根和反正切的运算刚好是将笛卡儿X-Y坐标 系转换到极坐标系的一个过程。因此可以考虑采用Cordic计算方法。 在前面4.2.6节已经详细介绍了Cordic的原理及迭代公式,因此, 用FPGA来实现求反正切和平方根不是什么难事。 4.2.6节也介绍过,可以采用Cordic向量化模式来直接将举行坐标 系转换到极坐标系。同时,考虑到本系统的流水线式的处理结构,我 们将采用pipeline结构来设计Cordic处理核,如图7-24所示。
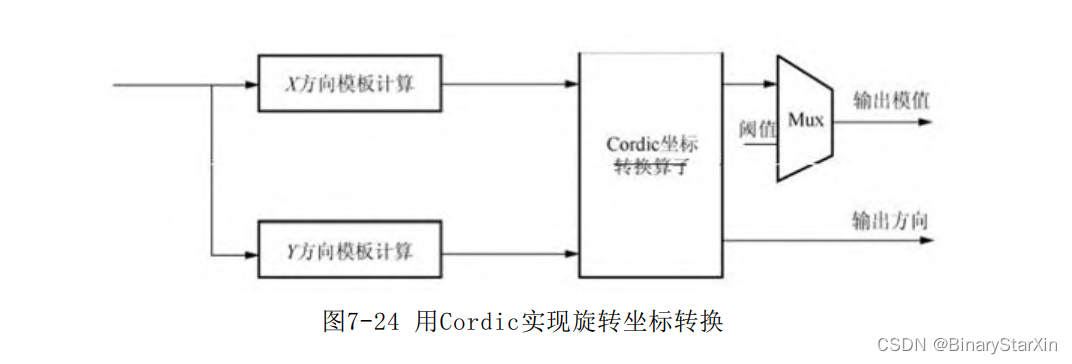
Cordic算法在FPGA上实现已经不是什么难事,遗憾的是,Altera 目前并不提供免费的Cordic IP核。Xilinx提供了Cordic的IP核,并可 以支持正余弦、反正切及开根号等运算,本书不打算介绍Xilinx CordicIP核的使用及原理,有兴趣的读者请参考Xilinx的官方说明文档及相应教程。在下一节中,我们将详细讨论基于Cordic原理的坐标 系转换。
7.3.2 Sobel模板计算电路
上一节已经简单分析了Sobel模板计算的基本原理。为了尽量利用 FPGA的并行特性,我们考虑同时进行X方向和Y方向的计算。同时,我 们注意到,由于模板的数值为1和2或者-1,-2,我们考虑将负数和正 数相加后再整体做减法。模板元素为2时直接进行移位操作则简单地 多。 同时得到窗口内9个像素的值是比较简单的一件事情。两个行缓存 加上当前行即可同时得到3行图像数据,将3行数据分别打两拍即可得 到一个窗口9个像素数据。这里将这9个数据命名如表7-7所示。
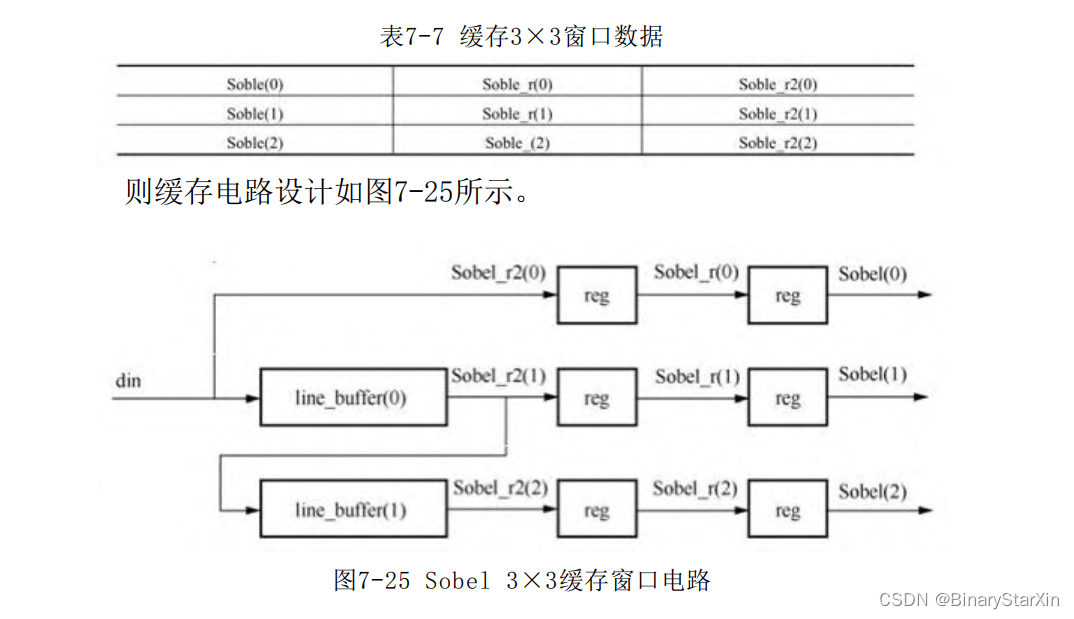
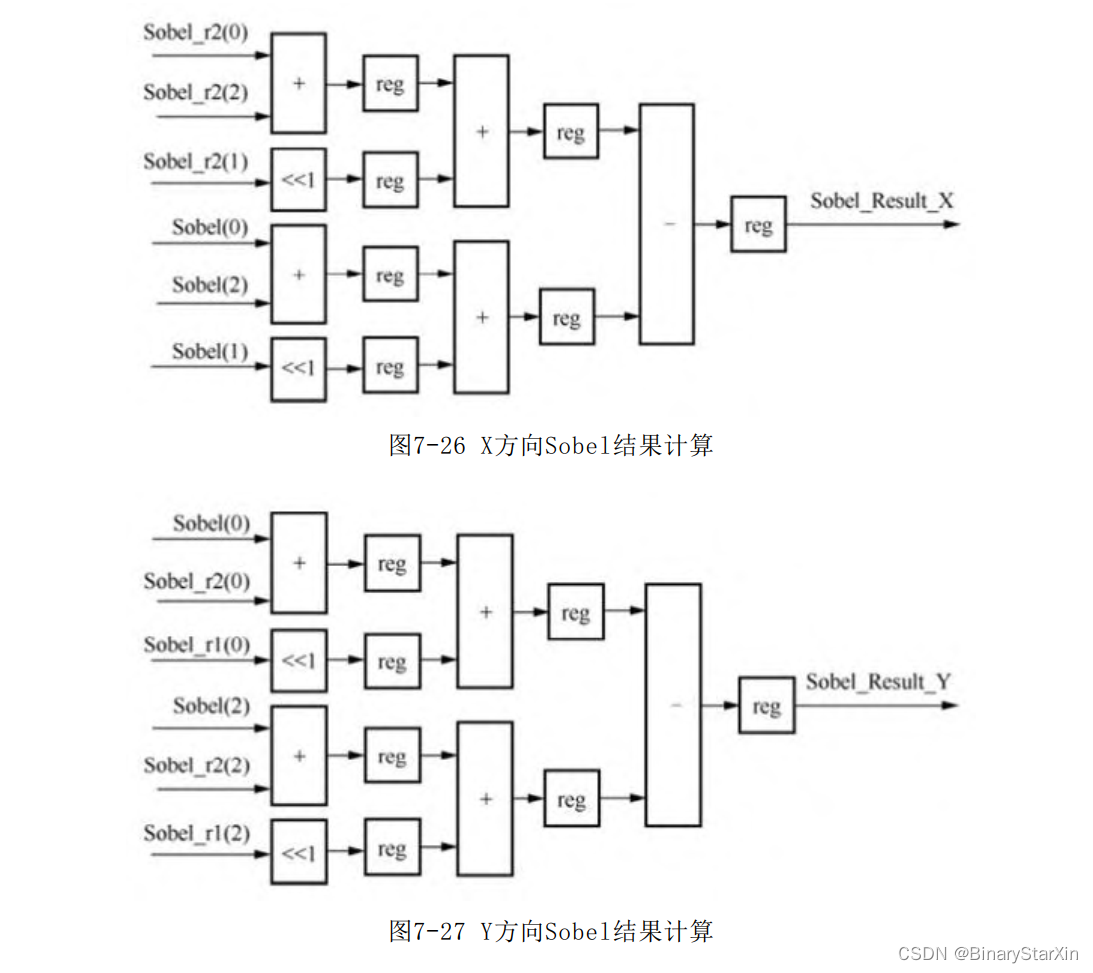
得到9个像素之后还需将分别对X和Y方向的模板进行运算。由于两 个模板中有3个像素恒为零。实际上需要完成6个数据的加法运算,经 过 3 个 时 钟 的 运 算 即 可 得 出 结 果 。 记 X 方 向 的 运 算 结 果 为 Sobel_Result_X,Y方向的运算结果为Sobel_Result_Y分别如图7-26和 图7-27所示。
7.3.3 基于Cordic的坐标系转换电路
我们的目标是将笛卡儿坐标系转换到极坐标系。为了不引起混 淆,规定极坐标系的定义域如下: ρ﹥0,0﹤θ﹤2π 即转换后的θ值为0~2 π,也就是0~360°(相当一部分反正切 函数取值范围为-π/2~π/2 )。 1.Cordic迭代公式 按照4.2.6节所述,将坐标Yi 进行迭代旋转到0,即可实现笛卡儿 坐标系到极坐标转换。设初始坐标为[Xi ,Yi ,Zi ],旋转后坐标为 X j ,Yj ,Zj ,Z表示角度,P为旋转过程中的增益补偿,则旋转公式 如下。

上式的基本意义是初始坐标[Xi ,Yi ,Zi ],旋转一定角度后到坐 标 X j ,0,Zj ,也即原始坐标经过若干次迭代旋转后旋转到x轴。 由几何意义可知,理论情况下,旋转后到x轴上的坐标的绝对值|Xj | 即原始坐标的模值 ,由于采用了消除公因式的运算方式来减小计算量(见4.2.6节),需要乘上一个增益补偿P。而这个旋转角度 也就是arctan ,如图7-28所示。
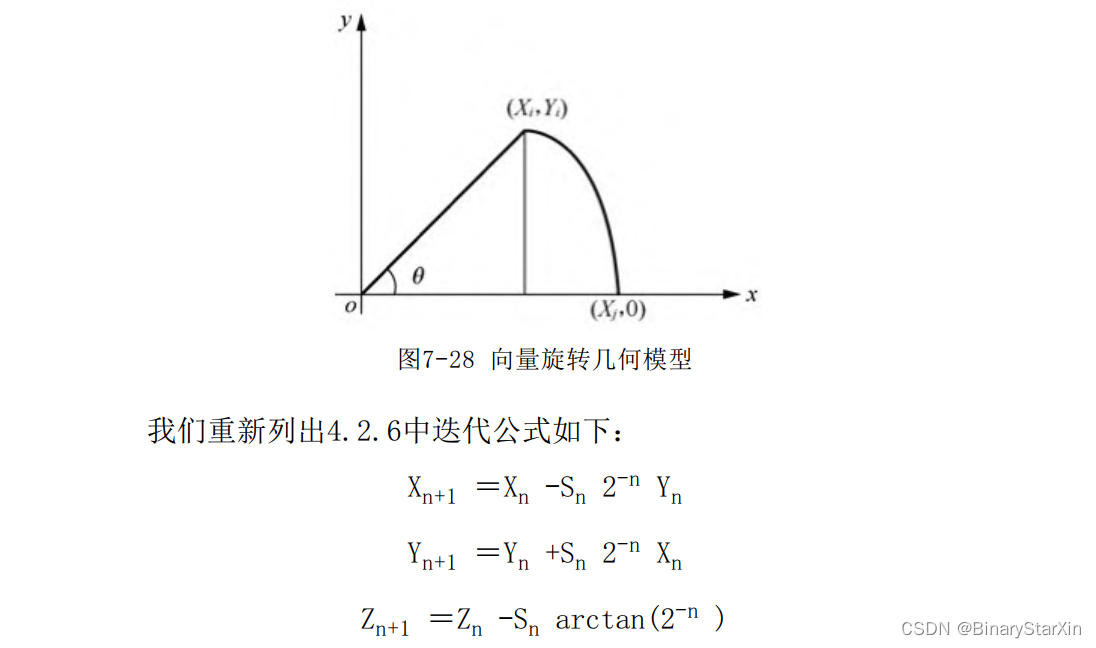
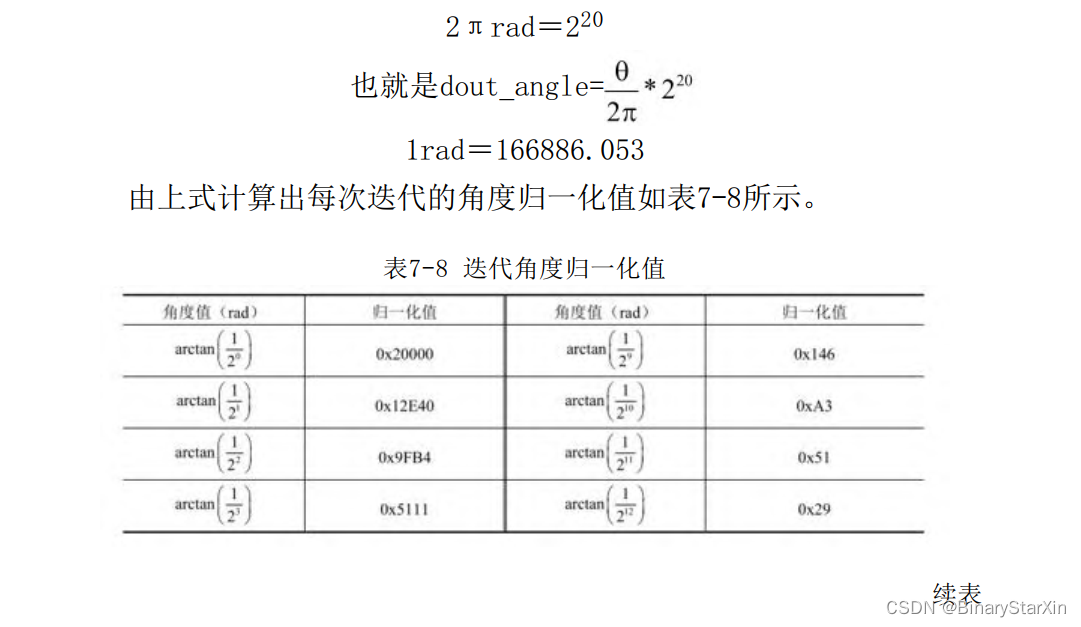
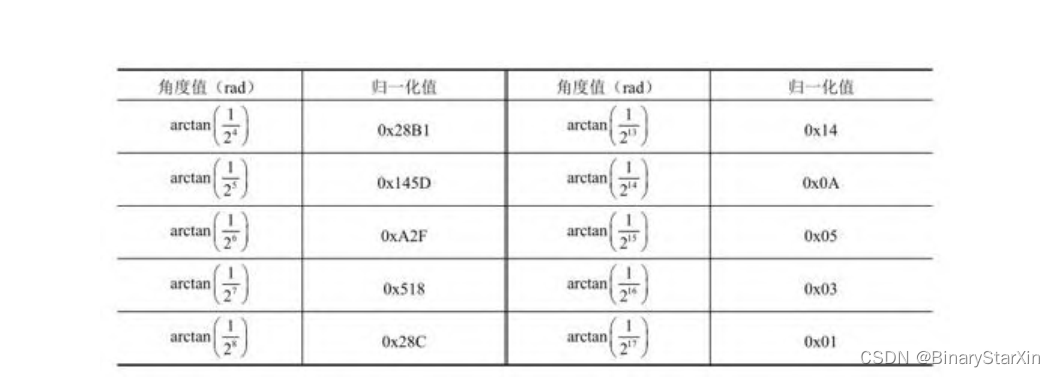
由于我们的目的是使Y趋向于零,因此Y的符号位决定了旋转的方 向Sn 。这是很容易理解的:如果在迭代旋转(第n次旋转的角度为 arctan(2-n ))的过程中,图示时刻Y大于0,需要将Y减小,也就是需 要将Y沿顺时钟进行旋转,此时Sn =1;而由于不能“恰好”在某次旋 转中将线段旋转到Y轴上,因此需执行若干次在Y轴上下的旋转工作。 若在某次旋转过程中,Y旋转到了Y轴下面,这个时候需要将Y变大。因 此,将Y沿逆时针向上旋转,此时Sn =-1。 2.Cordic迭代次数及查找表计算我们将首先确定旋转迭代的次数,并根据迭代次数来计算每次旋 转的角度arctan(2-k )(k代表第k次迭代旋转)。通常情况下会将这n 个角度值实现计算好,并作为一个查找表写死到FPGA中,每次旋转计 算角度的时候FPGA来查找这个表进行迭代运算。可以想象,最后依次 旋转调整,即最小的旋转角度决定了算法的计算精度。 接下来的问题是这个角度值一般情况下是个小数,在FPGA处理中 需要对其做一个整形转换,以方便计算。在本次设计中我们取迭代次 数为15次,归一化系数设置为220 。定义如下:
3.坐标象限变换 我们注意到在图7-28中,变换是基于第一象限的,到目前为止, 我们讨论的情况也都是在第一象限的范围内。而实际上,输入的x与y 在4个象限内都有分布。那么如何解决这个问题? 在迭代代码设计中考虑四象限问题无疑带来了代码设计的复杂 性,同时也极易出错。我们这里所采用的思路是将x与y转换为无符号 数,即求取绝对值,同时缓存其符号位。在对x与y进行迭代变换后再 取出符号位还原象限信息。 同时,为了尽快使其收敛,我们再将其进行变换到1/4象限,也即 (0~45°)范围。这个变换也非常简单,当y>x时将x与y调,迭代变 换后再将其还原即可。 4.增益补偿 增益补偿负责旋转过程中的模值失真补偿,对于固定的迭代次 数,它是一个常数。
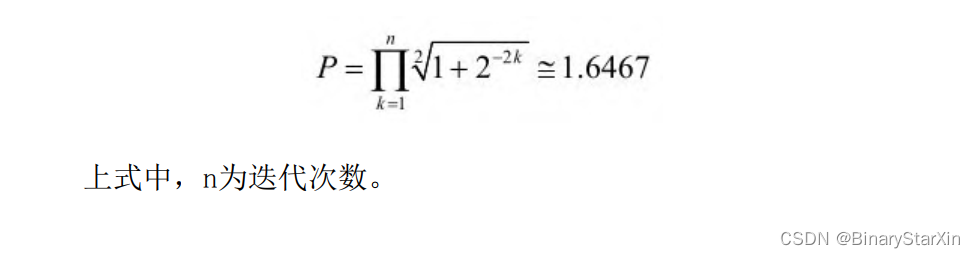
同样的,对于固定的除法运算,我们采用移位和加法来实现。要 得到实际的模值,需要将旋转后x轴的值除以P,也就是乘以0.60725。 采用以下公式来近似:
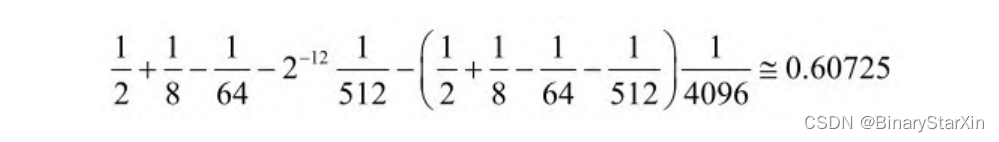
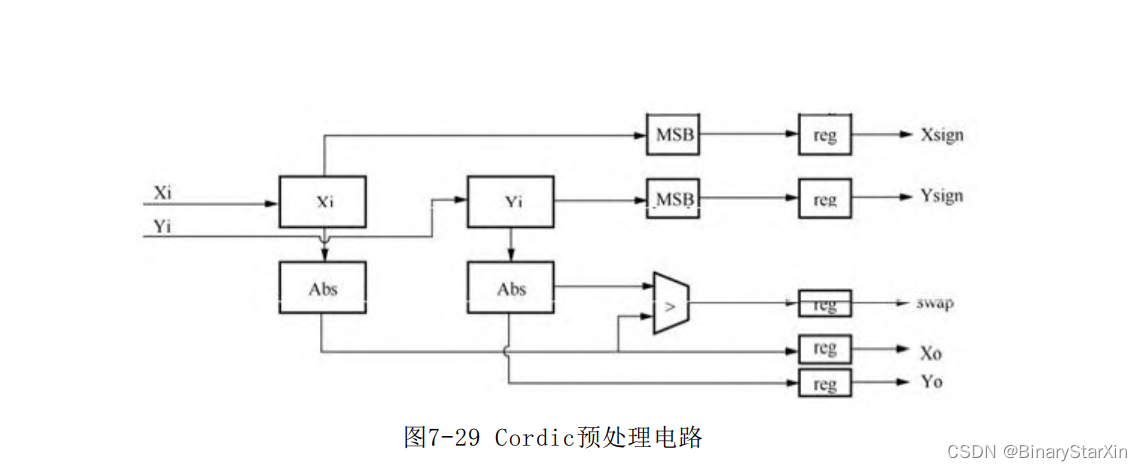
5.Cordic模块划分及设计 基于上面的讨论,我们要完成以下3个要点的设计。 (1)前期预处理:完成坐标象限转换。 (2)完成n次迭代工作:采用菊花链式结构设计。 (3)后期处理工作:恢复象限转换,增益补偿。 将 上 述 3 个 模 块 分 开 进 行 设 计 , 分 别 命 名 为 cordic_pre,cordic_core,cordic_post,同时,由于每次迭代工作都是 一致的,将迭代算法的基本流失单元也组装成一个小模块,将其命名 为cordic_ir_unit。 下面分别介绍各个模块的设计。 6.预处理模块(coridc_pre) 预处理主要负责象限转换工作,主要是将输入四象限坐标转换到 第一象限的前半象限,即0°~45°。 转换工作十分简单,只需提取输入x和y的坐标绝对值作为输出,即 可将坐标转换到第一象限,同时判断x和y的绝对值大小,当y>x时将x 和y调换即可将坐标转换到第一象限的前半象限。 模块需记录输入x和y的象限信息,包括半象限信息,以供象限位 置还原。 模块设计框图如图7-29所示。
















 6007
6007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











