







前言:Objects及Debug方法
Objects
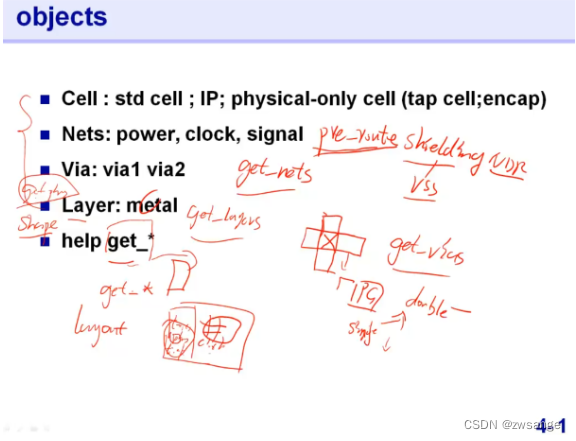
列出了一些常用的对象objects,我们向看哪种对象,都可以用get_*来快速进行抓取;
Debug

Debug能力是非常重要的,因为我们在做后端过程中,会遇到各种各样的error/warning,这些都需要我们自己去解决;简而言之,遇到报错,首先看他描述的是什么错误,然后man一下错误号,看看和什么相关,然后就是顺藤摸瓜,脑子有一个清晰的框架,根据错误提示可以想到哪些地方设置的不对可能会导致该错误;这其实就要求我们对后端的整体flow有非常清晰的结构和认识;
下面举例说明:

上图,报了两个error,首先我们看第一个描述,说是top利用率为238.33,这显然太高了,我们的利用率不可能>100,然后我们man一下错误代码,并推测什么原因会导致利用率达到这么高,可能:①blockage设置的太大了,导致cell没地方放,有限的面积利用率增大;②core面积设的太小了;③前面根本就没有做initial Floorplan,因此也就没有对应的面积;
再看这个面积利用率高达238,这肯定不是一般的blockage设的大了,因为不会导致这么高的利用率,大概率是前面忘记做initial Floorplan了;
在我们怀疑的这些方向中,真因不一定是我们想到的,但是我们在仔细检查的过程中,可能就会发现问题所在;
本章Agenda-CTS时钟树综合

单独提几个点:
①capture path就是从clock source到FF的路径(或者指DC中的network latency);Launch path又分为launch clock path和launch data path,其中,capture path和launch clock path之间的时间差可以认为就是skew;launch data path是数据从FF1到FF2的路径;
②CTS的两个重要指标:skew要尽可能的小 & 时钟树长度要尽可能短,以降低功耗;
CTS Flow
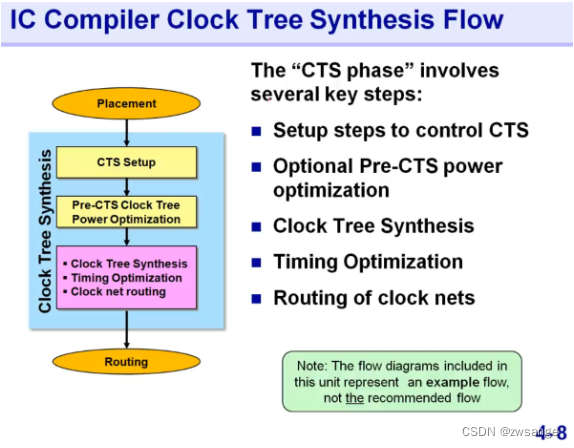
CTS的步骤和前面placement类似,都是先setup,然后执行core command,再进行优化opt;
Setup
状态检查

在进行CTS之前,我们必须要确保上述的条件都是满足的,否则无法进行;其实在后端过程中,每完成一项flow,最后都需要进行report及check,这样我们在做后续的步骤时就会方便很多;
对于AHFS的检查,我们前面在placement中,已经将AHFS的net通过建立buffer tree做好了,但是另一个理想的net就是clk net,这一步需要解决这个问题;
Before CTS
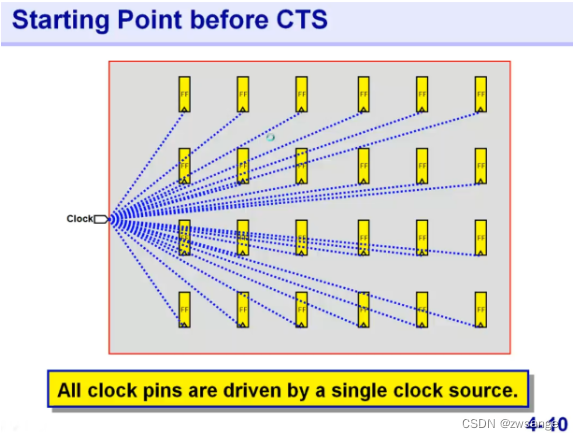
在进行CTS之前,我们可以简单看一下这个图,所有的Register都由同一个clock source来驱动;

CTS就是在其中插入bufferr,将所有的FF连到同一个时钟源上,同时要平衡 负载/DRC/最小化skew;
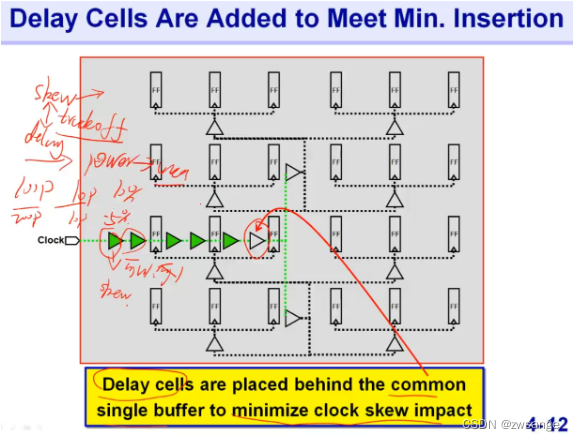
有时,我们会在common path上插一些delay进去,这样capture clk time就会增加,而由于delay是在common path上的,因此skew并不会改变,但是skew在capture clk time中的占比就会得到改善,但delay增大会导致power及area增大,这也是skew与insertion delay(network latency)之间做的一个取舍trade off;
CTS的目标
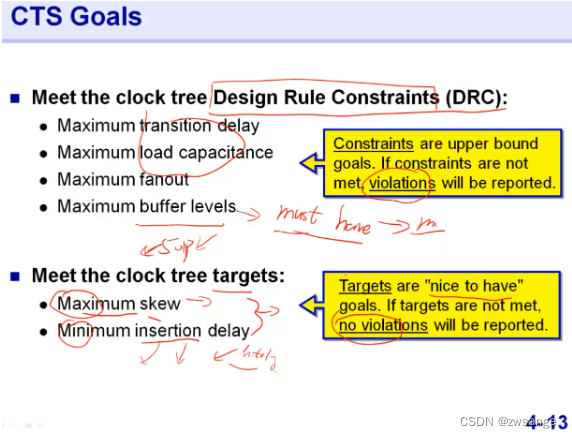
第一条的DRC约束是我们必须要满足的,称为must to have,如果不满足就会导致violation,这里面的转换时间、负载电容及最大fanout我们在DC中都提到过,buffer level是为了降低CTS长度的,即降低insertion delay;
第二条是我们的目标,nice to have,当然如果不满足也不会导致violation;这里的最小的insertion delay可以理解,毕竟越小代表延时越小(越小越好);Max skew的意思是,我们的insertion delay是不可能做到0的,那么就必然存在skew,当然skew也是越小越好,但是因为无法满足skew=0,所以我们在DC时就设置了一个skew,在优化时,就按照我们设好的skew去优化就行,比如设置skew=80ps,那就越靠近80越好,当然也不能超过80;
注意,这里的target是CTS时钟树综合的目标,包含DRC及skew+insertion delay两部分;
问题:为什么skew越小越好?主要的原因源于OCV,我们在设置OCV时存在一个timing derate的概念,当skew越大时,乘上timing derate会导致capture path与launch path之间的差距更大,导致时序难以收敛;skeew越小就会导致二者之间的差距越小,越容易时序收敛;
(记住每一章的目的)
Setup flow
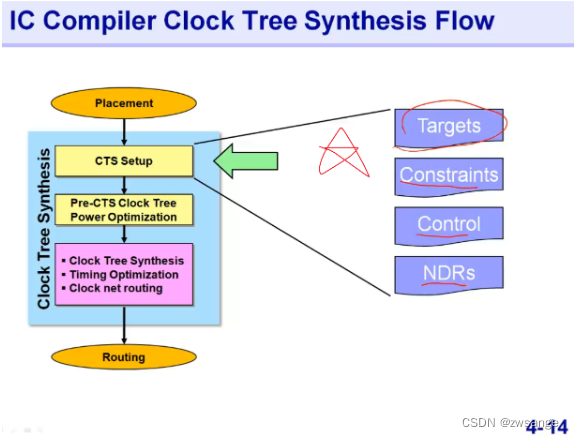
前面都是在说明CTS之前的一些铺垫,现在正式开始进行CTS setup,这一步是CTS中最重要的,只有setup做好了,后面才能做出好的CTS;
CTS target

clock tree的默认目标是把skew和insertion delay做到0,但这是不可能实现的,只是为了让工具尽可能的去优化;
在做CTS时,建议放松clock tree的target,设为10ps/20ps都可以,这样有利于减少buffer数量及run time;
我们也可以设置latency,如果不设置,默认也是0;
这里说的target是clock tree的目标,不是说的时钟树综合,仅有skew+insertion delay,可见图4-23蓝线框;
设置Clock tree target
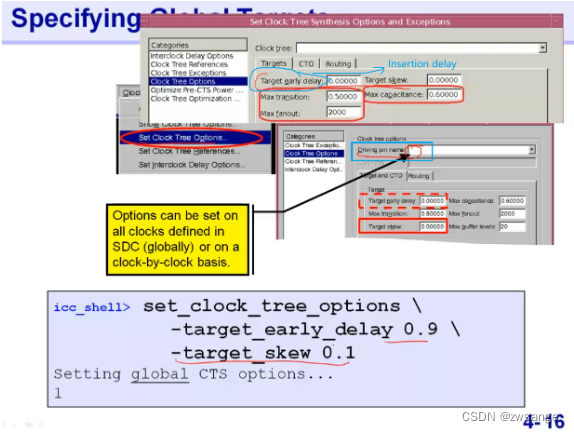
上图就是设置clock tree target的界面,target early delay就是insertion delay,默认设置的都是0,我们可以人为修改,一般会放松一点,如target early delay设为0.9,skew设为0.1;
Driving pin name:这一点如果设置了,就是针对某个clk,如果没设置就是针对所有clk;

对于不同的clock,我们可以用上图的GUI界面的Driving pin name来分别设置,当然也可以用命令设置,标注不同的clk名称即可;
Buffer/Inverter的选择-reference list

如果不设置buffer list,那么工具默认库中所有的buffer/inverter都是可以使用的,一般建议设置list;
对于修DRC的buffer,要驱动能力大的;平衡skew的buffer,则要上升沿/下降沿时间近似相等的;降低insertion delay的buffer一般驱动能力适中就行;当然,要确保所选的cell都在target lib中;
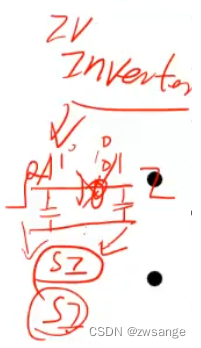
这里说一下,一般现在<22nm的先进制程,都是用inverter反相器来替代buffer的,还是因为串扰电容的原因,如上图,一般在buffer两边会形成串扰电容影响信号的跳变,而如果插入的是inverter的话,那么两边串扰电容的影响就会抵消,从而神奇的解决了这个问题;
CTS Constraints
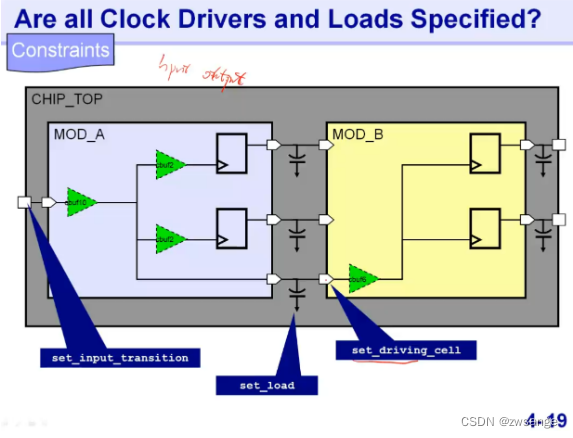
前面在DC中,我们设置了不同路径的时序约束timing contraints,此处我们也要设置input transition、driving_cell及output的load;这一点在前面第十六课的DC环境约束中我们也设置过;
移除 uncertainty中”skew"

在进行CTS之前,我们需要将uncertainty中”skew" remove,并且将jitter和margin放松一些,但是要保留;
为什么在CTS之前要去掉uncertainty中的skew? 因为在做CTS之前,uncertainty包含了skew、margin及jitter,这几个值都是根据经验估算出来的;而在做CTS之后skew就不需要用估算值了,工具可以通过时钟树的propagated clk计算出实际确定的skew,也就使得不需要再把skew算到uncertainty不确定性中了;
定义CTS的DRC约束值

对于max transition、max capacition等DRC rules,会存在于三个地方:lib/SDC约束/CTS setting中,工具对于这三个地方的设置,默认会取最小的一处来使用;
上图工具中的三个默认设置项的值都过于大了,一般我们max transition设置为0.1ns/0.15ns;max capacitance设为0.1;max fanout设为32;不过这也是经验值,不同的工艺和设计也会有不用;
CTS Control
CLK tree的起点与终点
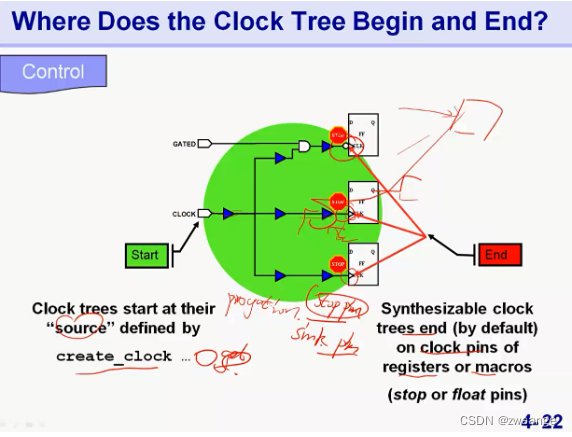
如上图所示,clock tree的起点通常都是我们定义的起点,也就是”create_clock“后面跟的get_ports的点,即clk source;而终点默认是一些register or macro 的clock pin,一般称为stop pin/sink pin;
Clock tree的终点pin分类
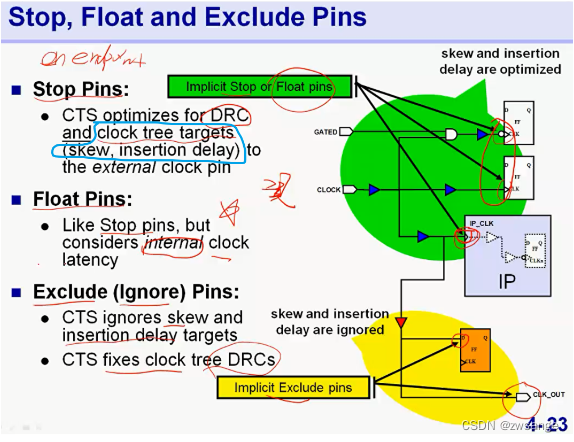
对于ICC工具而言,会默认将clk end pin分为三种,如上图所示:
①stop pin,一般是寄存器的clk pin及macro的clk 输入pin,对于这种pin,CTS会优化DRC、skew和insertion delay;
②float pin,通常macro 的clk 输入pin 可以当作stop pin,也可以最为float pin,优化时和stop pin类似,但会同时考虑IP内部的clock latency dalay;
③Exclude(Ignore) pin ,对于一些clk接到data输入端/clk out 的pin,优化时CTS只会修复DRC,不会优化skew与insertion delay;
产生时钟与gate clock的处理
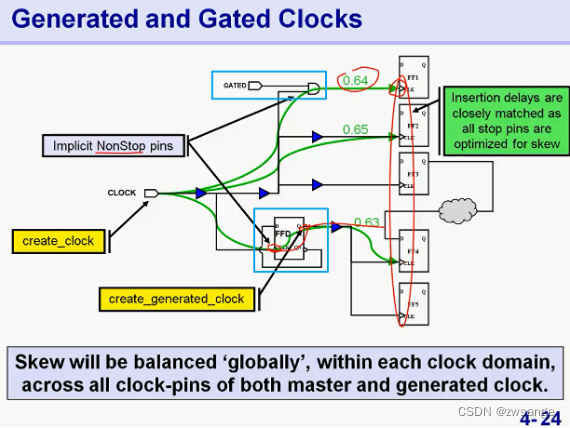
产生时钟域与主时钟域有crossing path连接:当master clk经过寄存器得到generated clk后,就得到了master clk domain和generated clk domain两个时钟域,此时,如果两个时钟域之间有crossing path相连接(时钟域能否平衡skew的区分条件,这个需要在做Clk tree时和前端沟通),CTS会将产生时钟的寄存器看作是Nonstop pin来对待,就相当于clk穿过了该寄存器,优化时会将两个时钟域看作同一个来均衡skew;简单来说就是直接看作时钟穿过了寄存器,不影响优化;
但是,这种的缺点就是,两个时钟域的skew肯定是不同的,那么工具就必须在skew小的那个时钟域插入一些buffer或者delay来平衡两个时钟域的skew,从而增大功耗和面积;
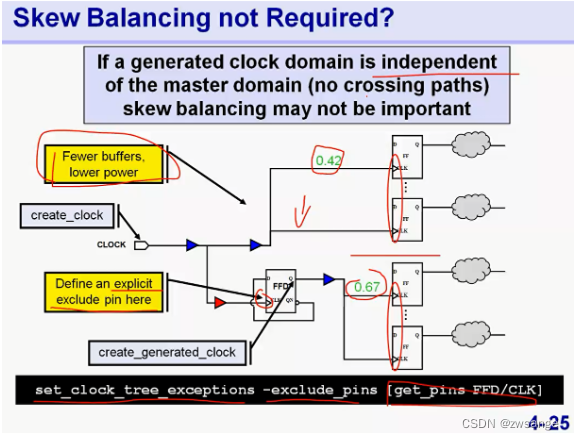
当产生时钟域与主时钟域没有crossing path连接时,那么就不需要平衡skew了,因此主时钟域就不用插那么多buffer,功耗也进一步降低;
设置时,就是将产生时钟的寄存器clk设为exclude pin即可,如上图;
Inter-Clock的设置
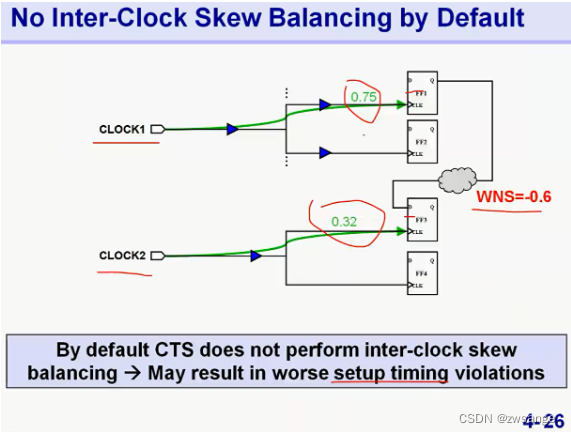
首先,明确什么时Inter-Clock:来自两个不同源的时钟域之间存在crossing path,这样的时钟称为Inter-clock,工具默认是不会对inter-clock做skew balance的,这样的话crossing path之间的timing violation可能就会很严重;

我们可以人为告诉工具在clk1和clk2之间进行skew balance,命令如上;但这样做的代价就是会导致shew较小的时钟域要加入较多的buffer,导致时序变差,功耗增加且面积增大;
上图我们可以看出,即使我们做了skew balance,但由于crossing path仍存在dalay,故还是存在较大的timing violation,那么要怎么消除呢?见下图;

我们可以在skew balance的基础上,进一步插入buffer,增大clk2的insertion delay/skew,从而抵消crossing path delay,达到消除timing violation的目的;
但是代价是很大的,clk2的skew从最初的0.32增大到了0.96,这其中需要很多的buffer,使得面积增大,功耗增大,这种代价一般是不可接受的,因此,一般在前端RTL设计时,就要把clock之间的skew做平,或者直接在crossing data path上进行修复,实在不行再去动clock tree;
SDC Latencies
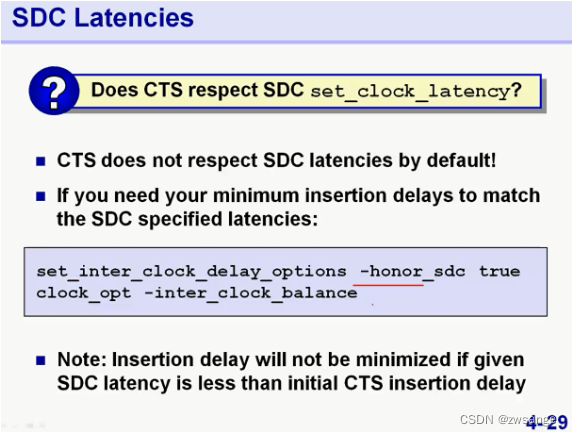
对于inter-clock,在做CTS时,工具默认是不会接受当时DC设置的SDC latency约束的,如果需要服从,可以手动设置honor_SDC;设置以后工具就会遵守SDC的约束而不管CTS设置的insertion delay了;
自定义clock stop pin

前面我们提过,对于macro cell的clk pin,一般是被定义过的,工具会当作stop pin/float pin来对待,但如果是没有定义的clk pin,那么工具就会当作exclude pin对待,优化时只会优化DRC,这是我们不希望的;
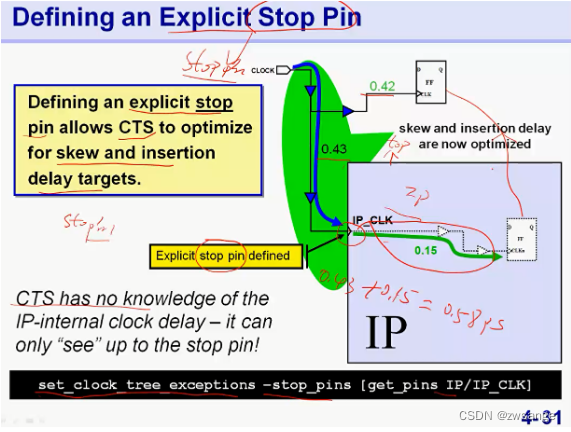
我们可以人为将macro cell的clk pin定义为stop pin,命令如上,这样工具就可以同时优化了;
需要注意的是,此时优化的skew balance只是从clock source到IP_CLK这一段的balance,如上图的0.43ps和0.42ps 的平衡,对于IP内部的clock delay,工具是无法得知的,因此一旦IP与外部的FF存在某些path,就很容易形成timing violation;
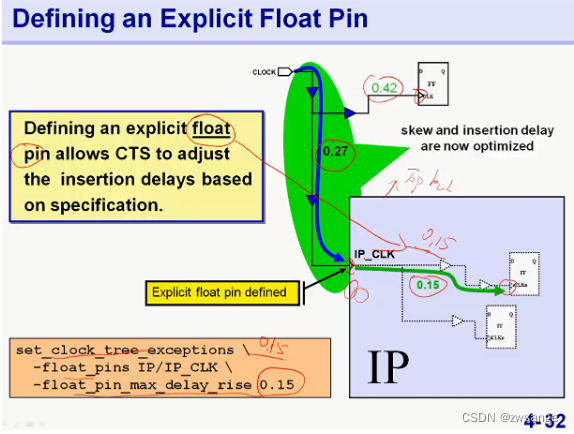
为了解决前述的IP内部clk delay不匹配的问题,我们可以将IP clk pin设置为float pin,同时附上一个IP内部clk delay的数值,这样工具就会考虑迟到IP内部的clk path delay,从而做到内外整体的skew balance,如上图,外部skew为0.27,内部skew为0.15,总共为0.42ps;
已存在的局部时钟树处理
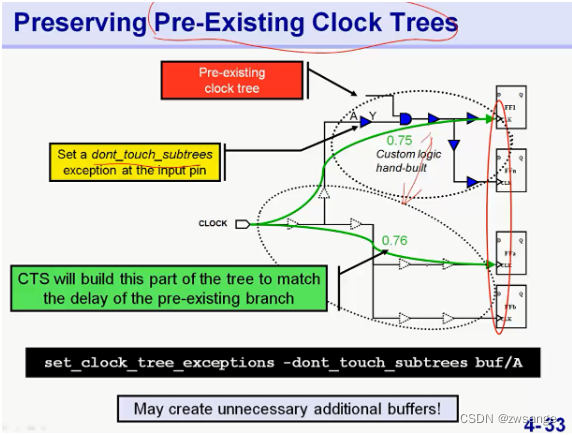
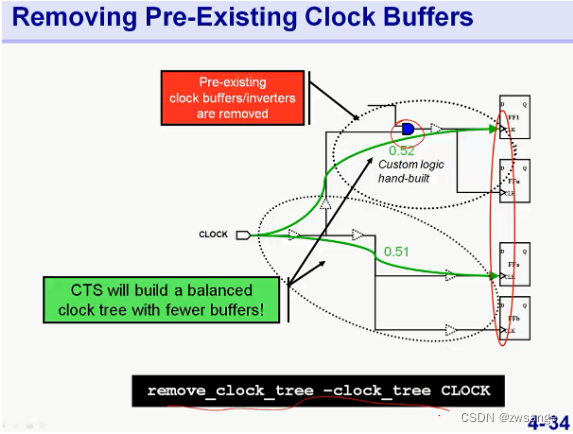
如上,对于有些局部已经存在的时钟树,我们可以选择保留 -dont_touch_subtrees,然后工具就会将根据这部分的skew去平衡其他部分的skew;
当然,我们也可以直接remove_clock_tree掉,然后让工具重新做时钟树;
计算模型的切换

在CTS之前,我们对于net delay的计算模型是用的Elmore delay model,在做CTS时,需要切换为Arnoldi-based delay model,这种模型在计算net delay时更加精准,缺点是会增加run time;
CTS NDR

前面placement中也提过,串扰电容的影响,主要影响SI信号完整性;
这里再说明一下,一条net,一般会存在一个对地电容,这个电容在net与地之间,一般不影响;而串扰电容存在于两条net之间,会影响net信号的完整性;解决方法就是double-spacing、double-width、shielding,称为NDR Rules;
NDR rules专门就是解决串扰电容和提高抗EM性能;
NDR参数设置规则

因为我们的net都是在track上的,两条相邻track之间的中心距称为pitch,我们在设置NDR Rule时,要保证spacing+width=整数倍的pitch,这样才能保证net准确的落在track上,同时工具在评估NDR后的net timing会更加准确,如果不遵守,timing评估很可能会出问题;
如上图的案例,2*pitch=2*0.81=1.62;double-spacing=2*0.34=0.62、double-width=2*0.4=0.8;由于double-spacing+double-width=1.42≠2*pitch=1.62,因此不能这样设置是不对的;此时,由于线宽是不能随意设置的,因此我们可以调整space的宽度为1.62-0.8=0.82,space的宽度只要大于minSpacing即可,这样就可以凑起来使得spacing+width=2*pitch了;

如上图的NDR rules设置举例;值得注意的是,我们最后要将设好的NDR rule及布线的metal层与clock tree相联系起来;
Stop pin的NDR rule设置

这一点需要注意下,在clock pin 的stop pin位置,也即是最后一级连到std cell出pin的地方,我们需要改为default rule,因为std cell都是default rule制造的,出pin的位置一般只有0.1,如果用NDR rule,net宽度就是0.2,而cell的摆放又是很密集的,就会很容易和附近的cell产生DRC问题;
NDR使用建议

①clock net一般在M3金属以上布线,因为低层metal RC很差,delay很大,导致clk tree很长;我推测,根据metal制造工艺,越往上层的金属越粗,低层金属线很细且密集,就导致RC值差,同时net越细电阻越大,导致延迟高;
②采用double width降低电阻,从而较小delay,增大抗EM能力;
③double spacing降低串扰电容的影响;
④double via降低电阻并提高良率与延时;
⑤最后一级连接sink/stop pin的不用NDR rule;
⑥M1不用NDRs;
⑦NDR spacing+width=整数倍pitch;
Pre-CTS的功耗优化
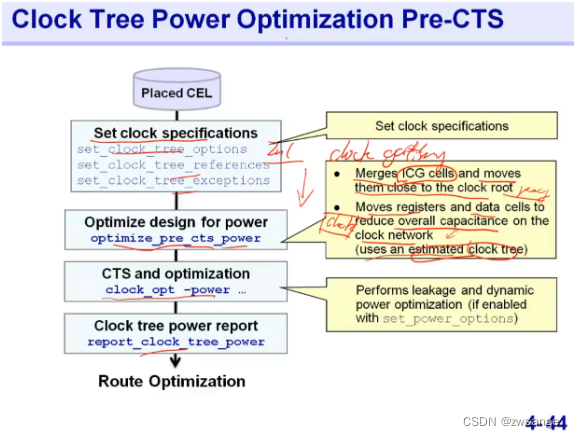
ICG cell:Integrate Clock Gate--集成门控时钟,一般由一个latch加一个与门/或门构成,工艺厂商做成了一个整体cell,称ICG;CTS之前的功耗优化就是在前面完成setup后,加入一个optimize_pre_cts_power命令,将门控时钟cell和register靠的更近,从而降低net负载电容,降低功耗;同时,将register和data cell也移动靠的更近,降低功耗;
ICG都是成对出现的,一个在靠近clk source端,另一个位于stop pin端,做CTS时对于靠近clk source端的ICG cell setup约束要加紧一些,否则后面很容易出现时序问题;
Preform CTS and Timing opt

CTS前check

如上图所示,在进行CTS之前,我们需要check一下是否满足,可以用两个命令来check:
①check_physical_design,用来check placement是否完成,clock是否都定义好了等;
②check_clock_tree,用来检查产生时钟是否定义好;时钟是否是同步的;多时钟设计是否定义;master clock是否在合适的位置stop;等等;
Preform CTS

core command:clock_opt;默认的,工具会执行三个步骤:第一步,针对clock path,进行balance的时钟树综合;第二步,针对data path,进行timing 和DRC优化;第三步,对时钟树进行routing;
此外,我们可以看一下manpage,他还有一些额外的参数可以控制,如优化dft/power/inter-clock balance等;
在执行CTS时,推荐用以下三步走:(其实就是对应clock_opt默认做的那三步骤,只是将他们分开做一步分析一步)


第一步:针对clock path,只进行CTS时钟树综合及CTO时钟树优化,做完进行分析;
第二步:针对data path,做逻辑优化logic_opt,做完进行分析;
第三步:进行routing;
这样分开来每做一步分析一下,有助于提高我们做的CTS质量;
做完CTS/CTO后的影响

在我们完成了前面所说的第一步时钟树综合和优化后,对当前的设计有什么影响呢?
工具会在设计中插入大量的buffer来构建时钟树,这些buffer的加入会导致congestion问题;同时由于clock cell的优先级要大于其他cell,工具会将其他cell从理想的location移走以放置clock cell,这就会导致非clock path出现新的timing 和DRC violation;这也是为什么后面我们第二步要做针对data path logic_opt的原因;
分析CTS结果-GUI

我们可以通过GUI界面分析CTS后的结果,如上图,柱形图的X轴表示skew,纵坐标表示该skew下的path数量,可以看出该设计的skew还算可以,比较集中;
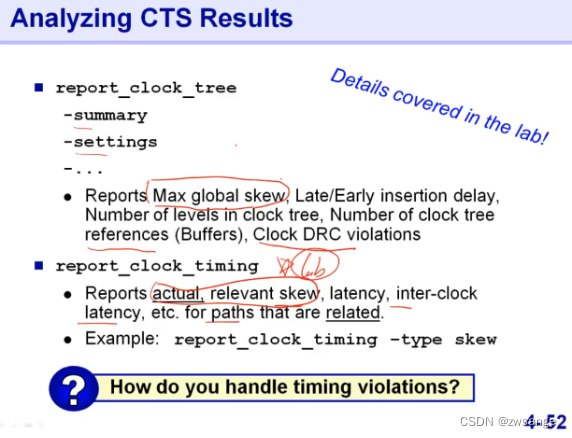
此外,我们也可以通过report命令来分析,如上图;
report_clock_tree来报告CTS相关信息;
report_clock_timing查看相关timing violation;
此时,如果出现了timing violation,我们就接着做第二步-针对data path的logic_opt;
Logic_opt for data path

通过对non-clock path的logic_opt,来修复timing violation,同时还可以针对power/congestion/dft进行优化;
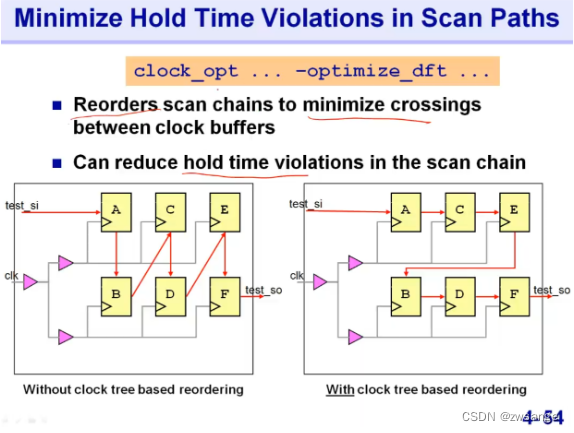
针对DFT Hold time violation优化 -optimize_dft的优化举例;
Hold time fixing

修复hold violation,命令:set_fix_hold;在工具会抽取当前route的RC值,然后会自动完成hold的修复;
注意,这一步是在做完CTS/CTO后做的,设置修复hold的命令后,抽取当前route RC值,再执行data path logic_opt;
Summary--CTS Flow


复习的时候对着复习;
补充:Stand-Alone CTO
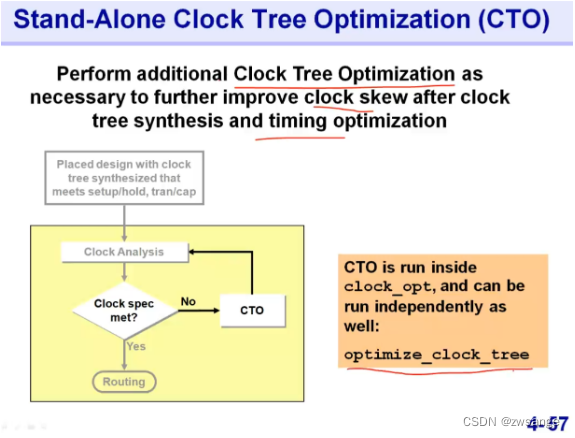
前面我们提到了,在做完CTS后,会进行分析,如果skew/timing等不满足要求,我们可以单独进行CTO;
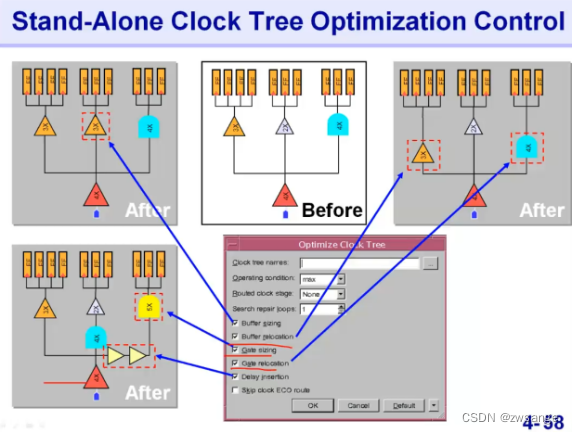
CTO的优化策略:改变buffer的位置与尺寸/改变gate的位置与尺寸/插入buffer提高驱动能力,从而降低延时;
附录A:IO latency update

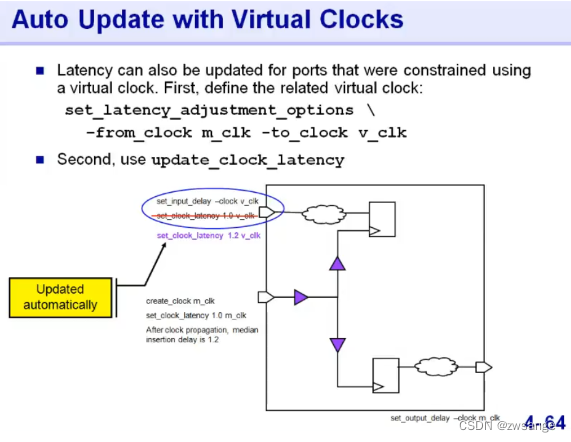
IO latency update 不是很常见,一边拿来说我们做完clock tree后,IO latency 都已经自动update了;我们可以用 -update_clock_latency 命令来手动update;
简单说一下update了什么地方,在我们做完了CTS后,network latency会有更新,这时候从source latency+network latency的值就会发生变化,那么相应的,我们对于IO path设置的input delay也要做出改变;
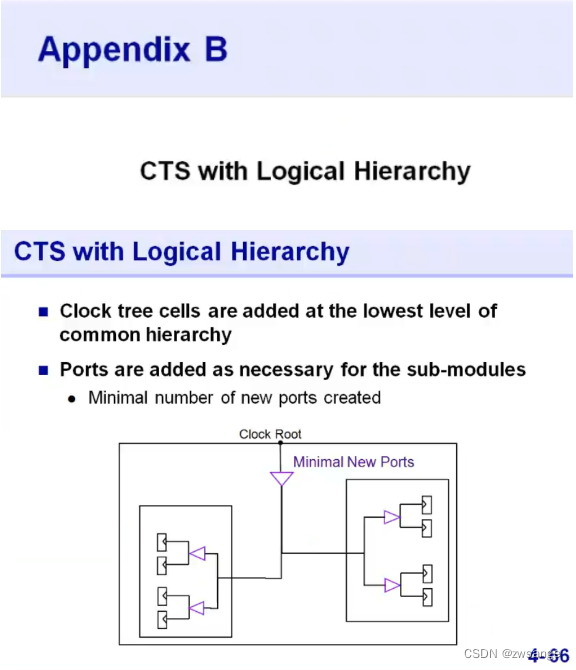
附录B:CTS with logical Hierarchy
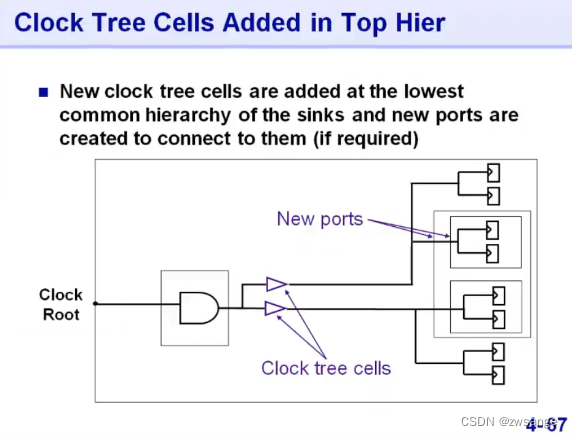
附录C:时钟树配置文件设置


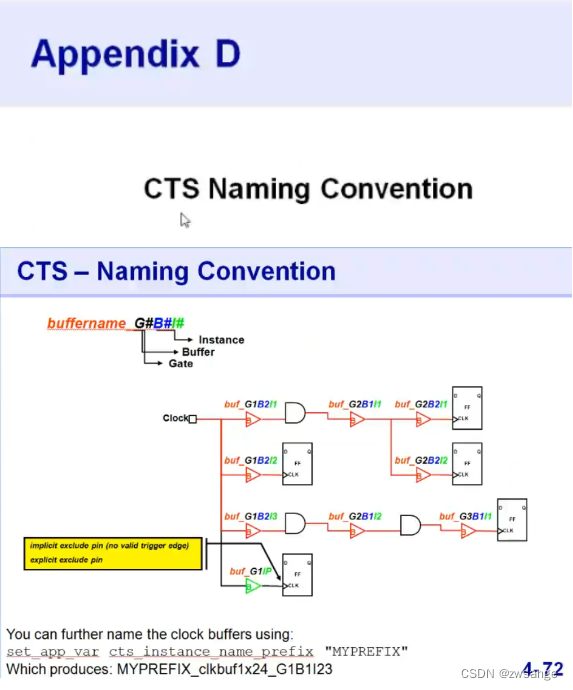
附录D:CTS的命名习惯
附录E:Clock shielding屏蔽线

在高速芯片的设计中,为了解决串扰电容的影响,我们使用的方法是加入屏蔽线shielding;

通过命令:create_zrt_shield在同一层net中加入shield;一般我们会在route之前加入shield,这样可以屏蔽的百分比会更多,但同时也会占用更多的绕线资源;route后也可以加入shield,但是百分比会低一些,因为有些位置被占了就无法布置屏蔽线了;

全屏蔽
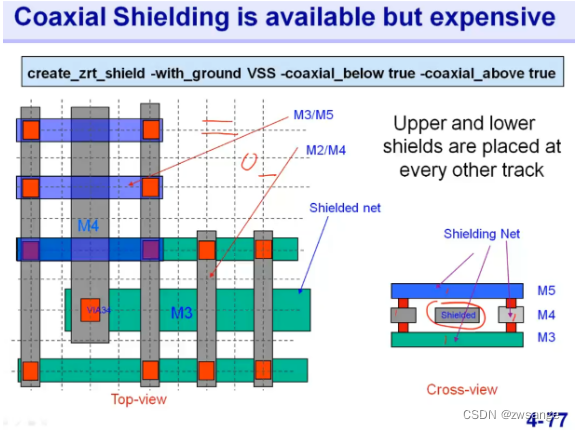
我们一般所说的屏蔽是在同一层中做的两侧相邻位置的屏蔽;而全屏蔽不仅包括同层,还包括相邻层之间的屏蔽,因为研究发现当相邻层部分重叠的地方也会产生串扰电容的影响;但是全屏蔽的代价太大了,一般不轻易使用;















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









