







摘要
关键词
Shape reconstruction, hierarchical shape perception, attention gate block, point cloud.
1. Introduction
1) 提出了分层形状感知网络,以完成受限手术视觉环境下的三维形状重建任务。这是首个从单个不完整磁共振成像图像重建完整大脑点云的工作。所提出的模型设计了多种机制,以确保对三维形状的准确感知。
2) 采用对抗预测器重建不完整的点云,以尽可能描述图像细节。通过分支图卷积网络(GCN)构建的新型生成器可描述复杂的大脑微观结构。
2. Related Work
2.1. 点云生成
2.2. 图像到 PC 的重构
2.3. 点云完成
3. Method
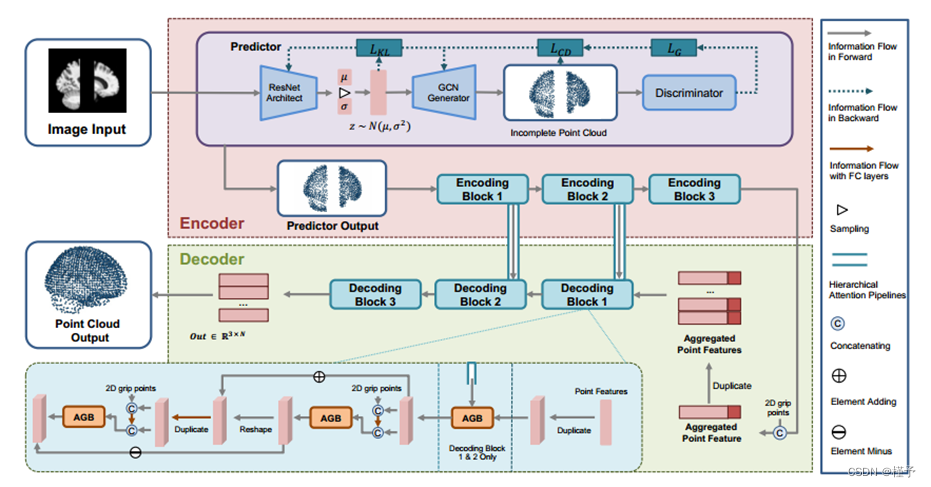
3.1. 带分层编码器和解码器的 AE 架构
为了满足这种需求,我们的编码器设计成一个特殊的架构,由预测器和多层特征提取块组成。如图 1 所示,对抗预测器大致采用 GAN 框架,输出的点云 YN×3 可以准确表示目标大脑(在本作品中,N = 2048)。然后,由 PointNet++ 构成的多个区块旨在从不完整的点云中提取特征。在经过类似于 CNN 下采样的几个过程后,最后一个区块将点云聚合成一个潜在特征,该特征携带输入图像的结构信息。特别是,为了让解码器获得足够的信息来还原完整的点云部分并生成不完整的点云部分,每个区块都会通过分层注意力管道将采样特征分享给相应的解码区块。
3.2. 逆向分支 GCN 预测器
核磁共振成像图像包含丰富的结构信息。完成的第一步是由这些不完整的图像表示还原物理结构。对抗预测器旨在提取几何信息,并利用这些信息重建尽可能接近原始形状的点云。给定一个特定的大脑受试者,其点云可以用矩阵 YN×3 表示,矩阵 YN×3 表示一组 N 个点,每个行向量表示一个顶点的三维坐标。拟议的对抗预测器需要不完整的二维图像。预测器有一个 ResNet [59] 模型,用于将此类图像 IH×W 作为输入,其中 H 是图像的高度,W 是宽度。ResNet 从具有特定均值 µ 和标准偏差 σ 的高斯分布中产生向量 z 2 R 96 作为输出,预测器的生成器将其视为只有一个点的点集。生成器有一系列 GCN 块和分支块,用于扩展和调整初始点集。然后,一个类似于 WGAN-GP [60] 的判别器将输出和真实点云进行判别,然后增强生成器。
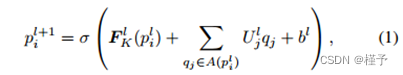
其中有三个主要部分:循环项 S l+1 i、祖先项 A l+1 i 和偏置 b l。循环项的表达式为:
![]()
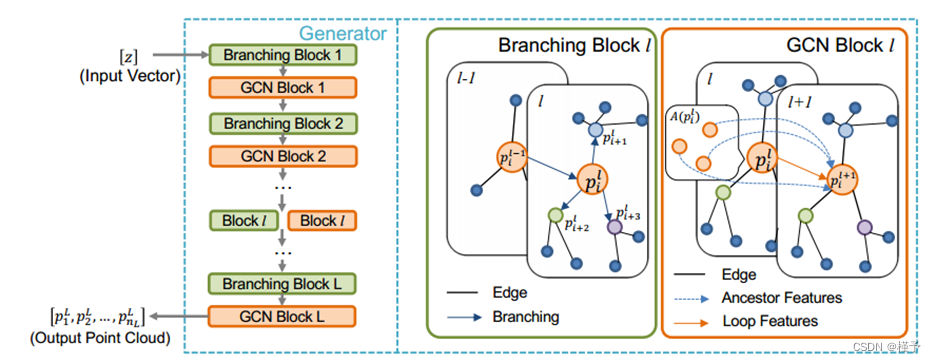
图 2. 预测器中生成器的详细结构。一个改进的分支图卷积网络由多个 GCN 块和分支块组构成。
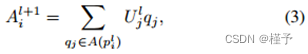
3.3. 编码和解码块
3.4. AGB:注意门模块
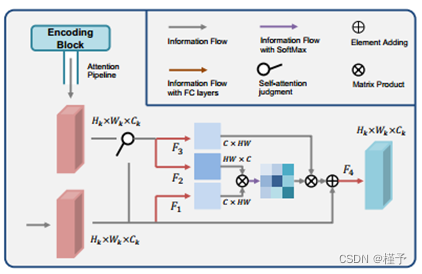
图 3. 拟议的注意力门模块的详细结构。自注意力判断将判断是否有注意力管道传输点云的局部聚合特征参与计算。如果没有,该模块将被转换为自我注意模块。
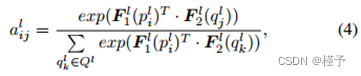
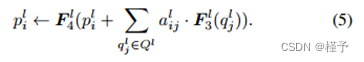
3.5. 训练中的损失函数
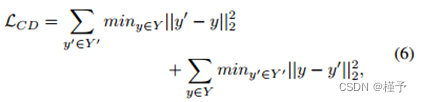
其中,y 和 y 0 分别是 Y 和 Y 0 中的点。我们将 ResNet 和预测器生成器的损失函数定义为:
![]()
其中,LKL 是库尔贝-莱布勒发散,λ1 和 λ2 是可变参数,Z 是编码器计算出的高斯分布。
同时,在鉴别器上使用了 [12] 提出的损耗。L2 定义为:
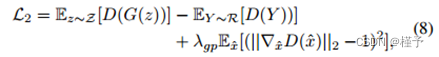
其中,x^ 取自真实点云和伪造点云之间的线段,R 代表真实点云分布,λgp 是加权参数。对于编码块和相应的解码块,倒易距离和另一种用于比较无序点云的置换不变度量--Earth Mover's distance (EMD) 都被用作损失函数。给定两个点云 Y 和 Y 0,Earth Mover's distance 的定义为:
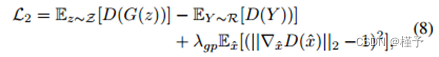
其中,φ 是偏射。CD 衡量的是一个点云中的每个点到另一个点云中的最近邻点之间的距离,有助于重建点云中的点更接近地面实况中的相应位置;而 EMD 衡量的是试图将一个点云转换为另一个点云的运输问题,有助于两个点云在整个概率空间中接近。我们建立了三维联合感知损失,以确保互补网络的拟合能力。该损失可写成:
![]()
4. EXPERIMENT

4.1. 数据准备和实施细节
为了评估所提出模型的性能,我们在内部数据集上进行了实验。预处理是在医生的专业指导下完成的。数据集由 317 张患有阿尔茨海默病(AD)的脑部 MRI 和 723 张健康的脑部 MRI 组成。磁共振成像中的所有骨结构均被去除,剩余图像通过 FSL 软件注册为 91 × 109 × 91 格式。900 张核磁共振成像随机选取其中一个作为训练集,其他的作为测试集。我们选择一些归一化为 [0, 1] 的核磁共振成像二维切片作为模型的输入。我们通过精确的体素级分割建立原点数据集,然后将其转换为点云。
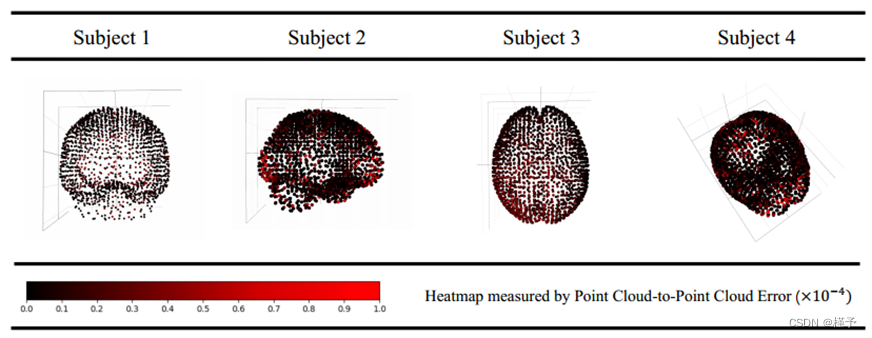
图 6. 点对点重构精度的结果是角度的倍数,用 PC 对 PC 误差的热图表示。
我们的生成模型和所有比较模型都训练了 2000 个历元。HSPN 由 Pytorch 实现,实验在英特尔酷睿 i97960X CPU @ 2.80GHz×32 和 Nvidia GeForce RTX 2080 Ti GPU 上进行。我们将 λ1、λ3、λ4 和 λgp 分别设置为 0.1、1、0.05 和 10,并使用初始学习率为 1 × 10-4 的 Adam 优化器。具体来说,我们通过将 λ2 从 0.1 增加到 1 来动态调整训练参数。
为了评估所提模型的有效性,利用倒角距离来评估客观质量。点云到点云(PC-to-PC)误差[3]用于测量输出中每个点的误差值。此外,我们还测量了模型的鲁棒性。
4.2. 完成绩效评估
图 4. 建议模型的定性评估。我们选择不同角度的核磁共振成像作为 HSPN 的输入。我们在三维空间中显示重建的点云,并将其投影到二维平面上。
4.3. 消融研究
表 I 用 CD(×10-1)测量的不同预测结构的效果

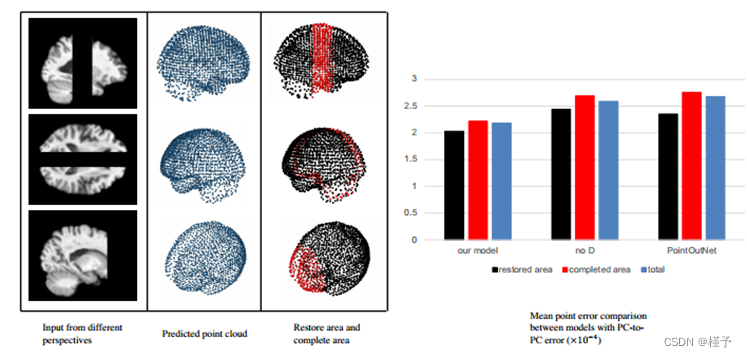
图 7. 不同编码器结构的比较结果。左图为完整区域和不完整区域的重建结果,右图为整个测试的平均点云对点云误差。
2) 补全系统的效果: 补全系统的生成能力直接影响装配效果模型的质量,并决定完成点云的最终质量。我们使用了几种不同的模型来替换我们建立的编码器(如果需要)和解码器,并测试了它们的性能:(1) "FC "是进行全连接解码器替换建议的解码器框架的变体。三层网络中输入和输出的大小分别为 [96; 1024];[1024; 2048];[2048; 2048 × 3]。(2) "FN "是进行基于 FoldingNet 的编码器和解码器的变体,由 [49] 提出。FoldingNet 通常是一个生成模型,但也可以通过适当改变输入来通用于点云完成任务。(3) "TN "是指用 [58] 中的 TopNet 替换编码块和解码块。我们在图 8 的上半部分展示了从测试中随机抽取的两个样本的处理过程,并在图 8 的下半部分和表 II 中报告了结果。平均误差和总点误差的比较表明我们的模型具有最强的重构能力。
表 II 用 CD 测量的完成系统对模型的影响(×10-1)

表 III Agb 对我们模型的影响,所有结果均以 CD(×10-1)表示

表 IV 用 CD 测量的点数的影响(×10-1)

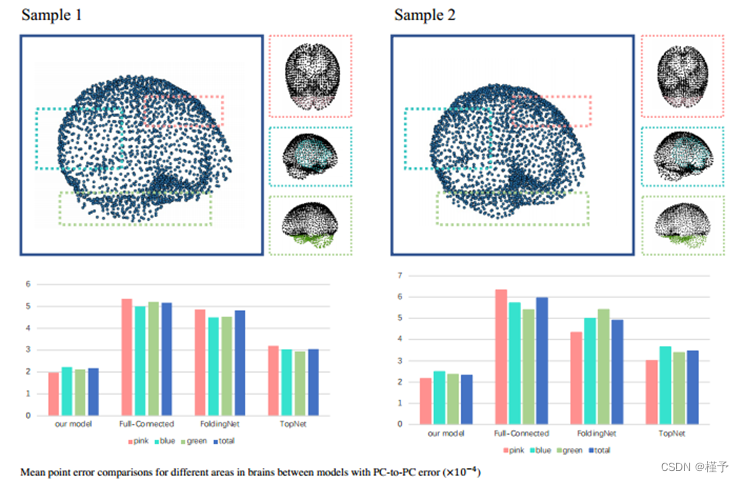
图 8. 不同解码器结构的比较结果。我们在左图中报告了采样过程,在右图中报告了整个测试的平均点云对点云误差。
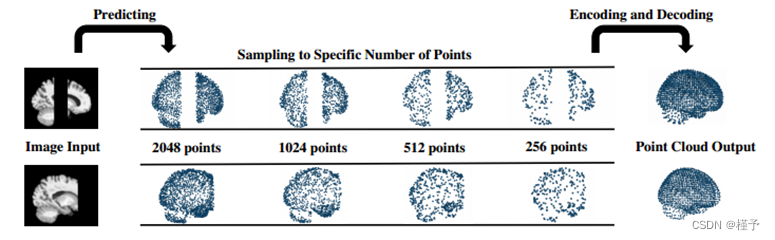
图 9. 预测器不同点数的比较过程。我们从 2048 个点的结果中按照预先确定的编号随机抽样,并将其输入后续模块。
表 V 用 CD 测量的图像输入数的影响(×10-1)

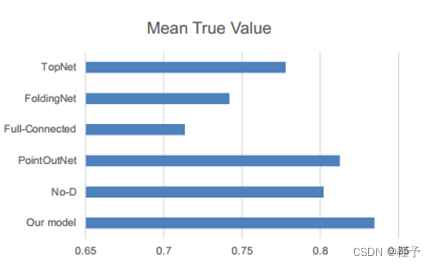
4.4. 重建点云的分类实验















 9319
9319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









