






最近一直在复现3D目标检测的算法,也在看一些相关算法的文献,比如这篇比较经典的PointPillars、Second和VoxelNet。第一次学习的小白理解起来还有点困难,这里记录一下自己的理解,主要是网络架构的解释。
论文:https://arxiv.org/abs/1812.05784
代码: GitHub - open-mmlab/OpenPCDet: OpenPCDet Toolbox for LiDAR-based 3D Object Detection.
(算法的复现可以参考上一篇博客:基于kitti数据集的3D目标检测算法的训练流程_mini kitti 数据集-CSDN博客)
目录
一、网络架构
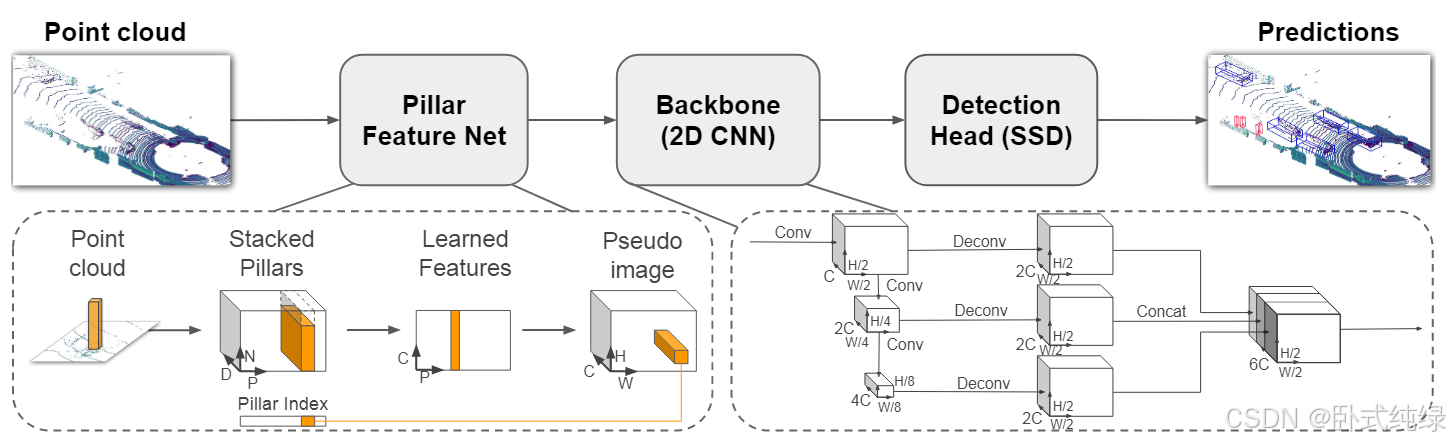
由网络架构图可知,其主要由三个阶段组成:1、Pillar Feature Net 2、Backbone(2D CNN) 3、Detection Head (SSD),下面分别介绍这三个阶段。
(一)Pillar Feature Net
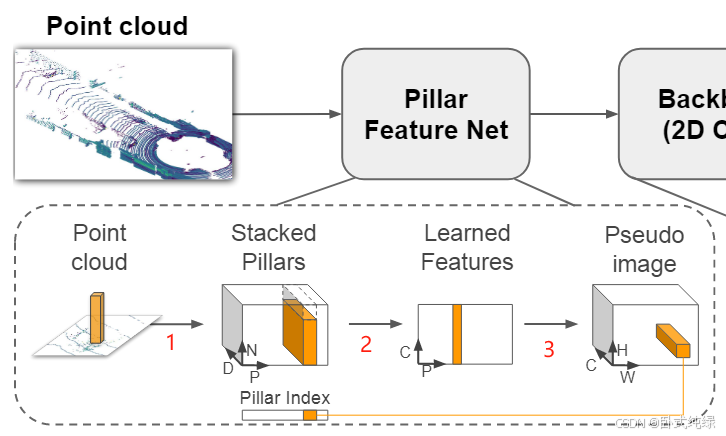
这个网络主要是将来自激光雷达(Lidar)的点云转换为稀疏伪图像(Pseduo image)。这个阶段又可以分成三个步骤(如图序号所示)。
1、点云离散化
原始点云是三维的,具有(x,y,z)三个坐标轴的坐标,这一步将三维空间中的点云沿着z轴的方向离散到x-y平面上均匀分布的网格中,形成了一组pillars(也就是柱状体),并拥有相对应的索引向量(图中对应的pillar index),引入索引向量之后可以解决点云无序性的问题。需要注意的是:这里pillar是在z轴方向上具有无限范围空间的体素(体积像素 voxel),故而不需要超参数控制z反向的融合/合并。
此时原始点云中的点由三维(x,y,z)扩展成九维(x,y,z,r,xc,yc,zc,xp,yp),其中xyz仍然是空间中的xyz轴坐标,r表示该点的反射强度(reflection),下标c表示该点到整个pillar中所有点的算术平均值的距离,即,x0表示每个点原始的坐标值;下标p表示该点距离pillar中心xy的偏移量。
由于点云的稀疏性,绝大部分的pillar中都是空的,并且非空的pillar中通常也就只有几个点,而作者采用了非常巧妙的方法解决这个问题:通过加强每一个样本(P)中非空pillars的数量和每一个pillar(N)中点数的限制,构造了一个(D,P,N)的密集向量用于减少稀疏性。【即P为样本中非空pillars数量、N为每个pillar中点的数量、D为维度】pillar中点数大于N则随机采样,反之则使用零进行填充来限制点数的数量。
2、生成向量
将1中生成的pillars采用简易版的PointNet,对于每一个点使用线性层,接下来是BatchNorm和Relu,生成规格为(C,P,N)的向量,之后再对N个通道进行最大池化操作(maxpooling)生成一个规格为(C,P)的输出向量。线性层可以表示为跨向量的1x1卷积故而可以实现高效率的计算。此时对N个点进行最大池化用于代表整个pillar的信息。
3、特征向量融合
将1中生成的索引和2中得到的规格为(C,P)的输出向量进行特征向量融合,形成伪图像。
即(P,C)+Pillar_index ——> (H,W,C),得到的是一个通道数位C的伪图像,从而可以使用最经典的图像网络进行处理。H和W分别代表图像的宽度和高度。
(二)Backbone(2D CNN)
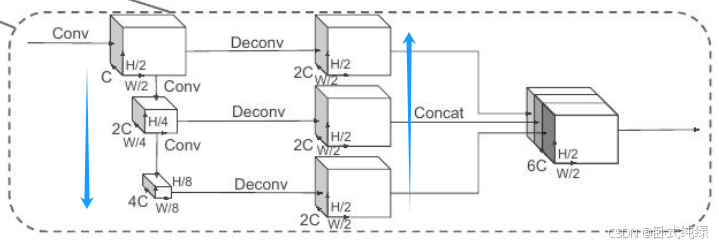
主干网络有两个子网络:一个自上而下的网络以越来越小的空间分辨率生成特征,第二个网络执行以上采样以及自上而下特征的串联。最终输出的特征将用于检测头的3D边界框的预测。
自顶向下的网络可以用一系列块Block(S,L,F)表征,每个块以步长S(相对于输入伪图像测量)运行,每个块有L个3x3 2D conv层(卷积层)和F个输出通道,每个输出通道后都跟着一个BatchNorm和ReLU。层内第一个卷积步幅为用于确保该快在接受到步幅为
的输入blob之后以步幅S运行,块中后续卷积的步幅均为1。而最终输出特征是来自不同步长的所有特征的串联。
(三)Detection Head(SSD)
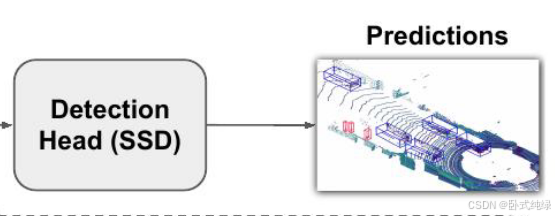
作者采用的是Single Shot Detector(SSD)进行3D目标检测。与之类似,作者使用2D intersection over Union(IoU)将先验框与地面实况进行匹配,边界框的高度和标高没有用于匹配,高度和标高成为额外的回归目标。
二、损失函数
这里直接截取论文中的内容了,大家感兴趣的自行阅读原文。

三、复现结果
花了两周的时间来复现Pointpillar和Second算法,在复现过程中遇到的各种bug和注意点都写在了我上一篇博客啦!
这里只对复现结果进行展示。
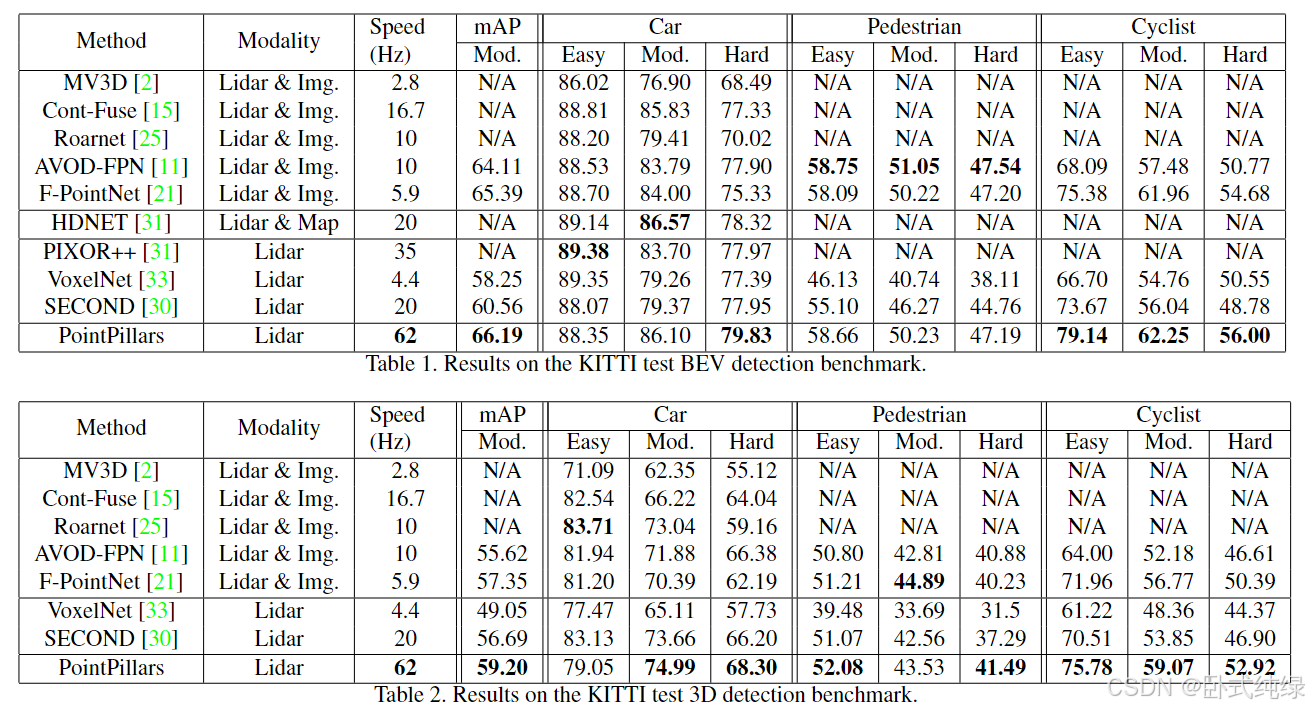

以上是文献中给出的结果。
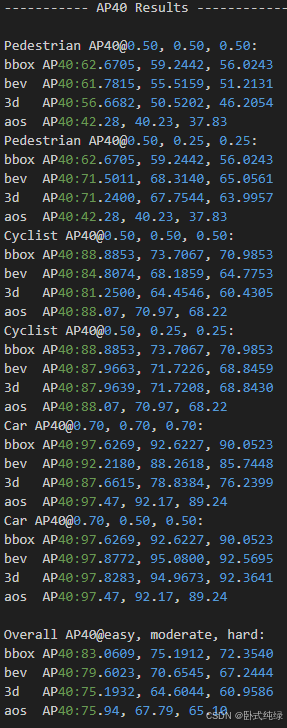
以上是本人复现结果的截图,其中
- bbox:2D检测框的准确率
- bev:bird'eye view 鸟瞰图下的准确率
- 3d: 3D检测框的准确率
- aos:检测目标旋转角的检测率(Average Orientation Similarity 平均方向相似度)
- 三列代表的事不同困难程度下的结果,依次是easy(简单)、moderate(中等)和hard(困难)
- @0.7……代表的事bbox/bev/3d评估时的IoU的阈值
- AP_R40代表的是基于40个召回位置计算的AP
本人跑的是三种类别的,以上有Pedestrian(行人)、Cyclist(自行车)和Car(汽车)的运行结果,大家可以根据自己的需要只跑一种类型。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









